The fist exercise out of eight that I have to solve in the optimal estimation course. The focus is on MAP estimation, MMSE estimation; MMAE estimation; ML estimation.
In this case, I need to use the minimum risk (Bayes) estimators from The Estimation Paradigm (the static case) and also apply the knowledge from Introduction to Optimal Estimation and Dynamics.
Context
The measurement system
I need to estimate the depth of the water below a ship by using a ultrasonic depth gauge sensor. It is mounted on the bottom of the boat and presents a transmitter and a receiver which capture a tone burst transmitted downwards.
The principle is ToF (Time of Flight).
The ToF is proportional to the depth . Let be the speed of sound in the water, then
For clarity, we denote the true depth of the water with and the noisy measurement with .
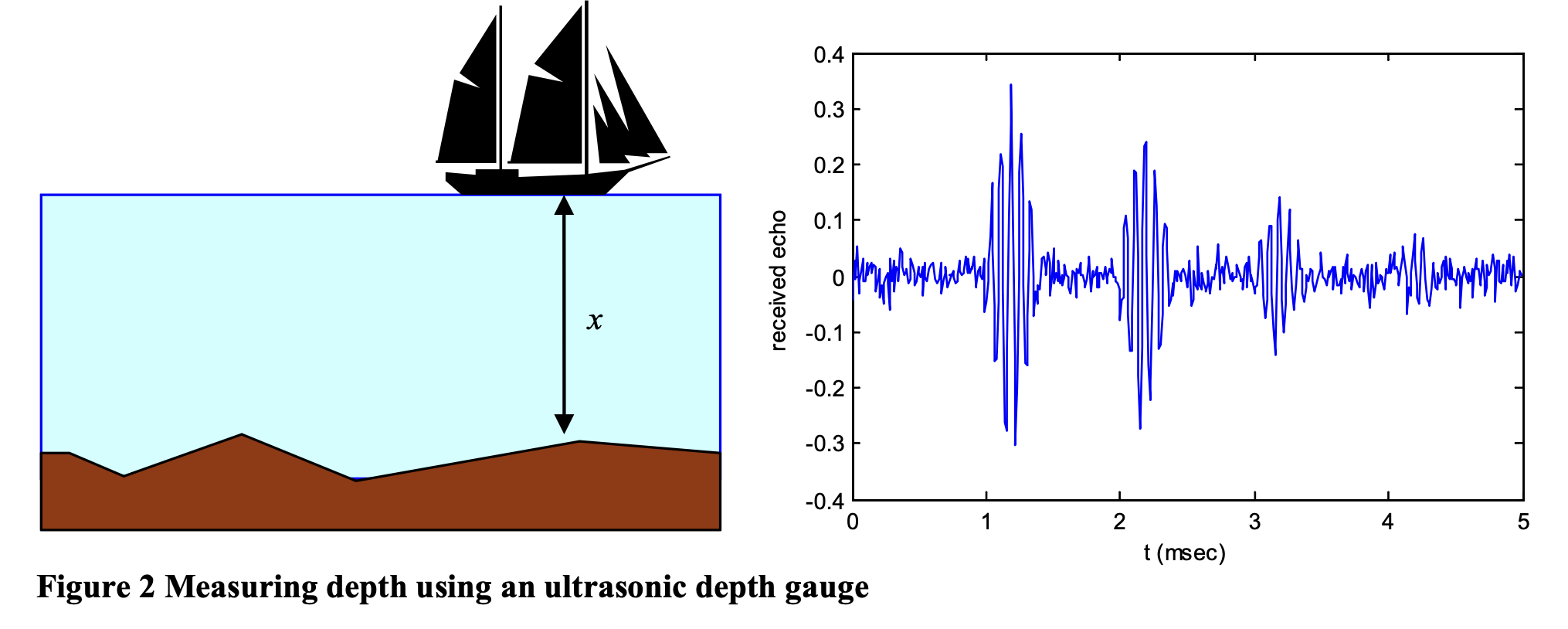
However, the measurement can be disturbed by multiple factors:
- Secondary echoes (Multipath Interference)
- The echo may reflect at the bottom of the boat causing a second echo that arrives at . The second echo may cause a third echo, and so on. This makes the depth appear twice as deep () than it actually is.
- Electronic noise
- The measurement is contaminated by Gaussian noise with standard deviation . If we assume that is the real depth and is the result of our measurement, we can adopt the following Gaussian mixture model (Likelihood Function) for the conditional probability density of
is the probability that the first echo is missed and replaced by the second echo. Obviously, is the probability that the first echo is correctly detected. .
In simple words, electronic interference adds “jitter” to the measurement, represented by a standard deviation .
Prior Knowledge (Ground-Truth)
Based on the information from a nautical map, the shipper has some prior knowledge about the depth. The map indicates an interval of possible depths. This interval is considered to be softly bounded. Such prior knowledge can be modeled with a Generalized Normal Distribution.
So, the captain gives the Prior Distribution . Instead of a standard bell curve, it uses a Generalized Normal Distribution, which allows for a “softly bounded” interval of likely depths using parameters (scale), (mean), and (shape).
For example, if the depth interval is , then and
My case
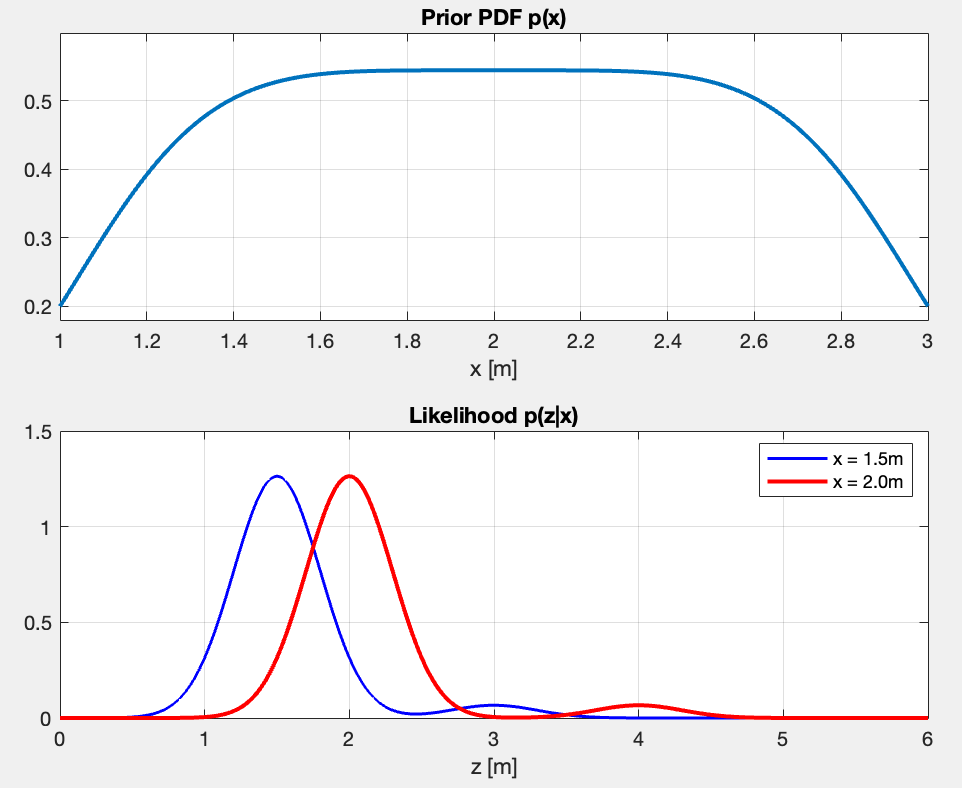
First Question: If we model and against for and , what do these PDFs model?
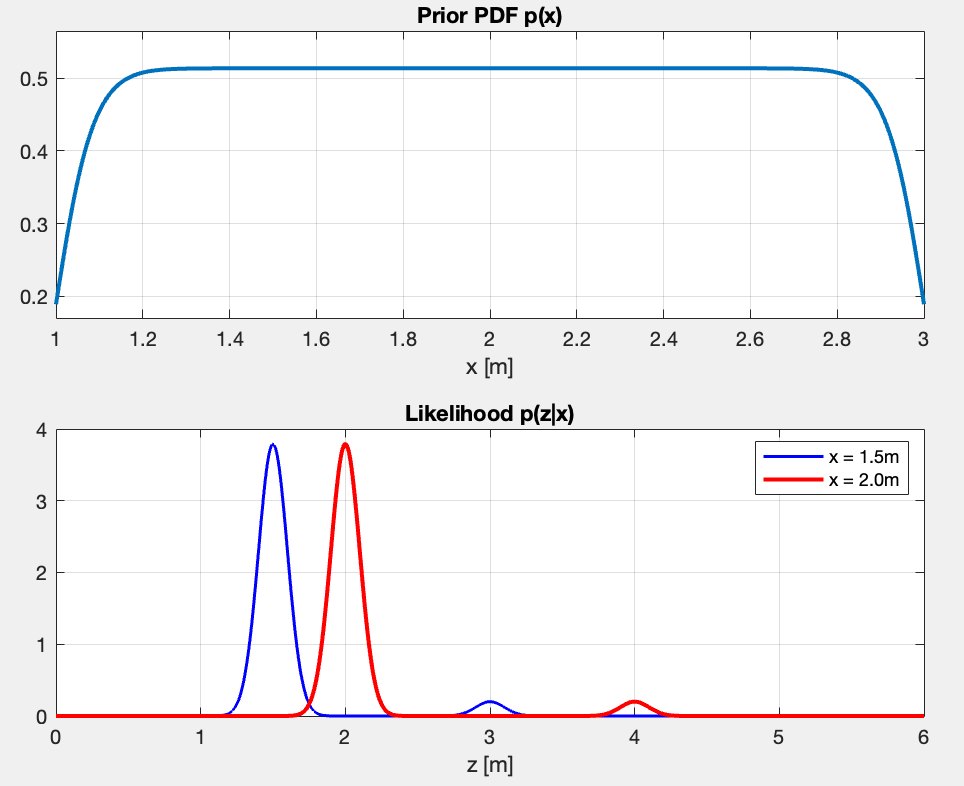
- The prior shows my belief before even measuring. It’s nearly uniform between and , meaning I consider all depth in that range roughly equally likely. Again, this one reflects the captain’s knowledge based on the nautical map.
- The Likelihood tells me what measurement I should expect given the two true depths (blue with and red with ).
- The blue PDF shows two peaks - one main peak at (correct echo, 95% probable), and a small peak at (secondary echo at 2x, 5% probable)
- Same thing for the red PDF - main peak at and small peak at .
- The peaks are sharp, showing the sensor is precise ().
What happens if I modify ? But ?
Modifying :
- The peak location stays the same, but the PDFs are more spreaded. As >>, the noise gets larger ⇒ the measurement is less precise
- The integral under each peak stays the same
- But the probability of getting a measurement near a value changes. The peak heights change.
- With (wider), there’s higher probability of measuring when . With (narrower), that probability is much lower.
Modifying :
- Changes which depths are considered more likely a priori
- As >>, I approach uniform distribution, meaning I assign all probabilities the same weight.
- In my current case, is good for “depth is somewhere between 1-3m, no strong preference”.
example for and
Second Question: Compute the PDFs regarding and . Now we model these against for and for .
What do they represent?
The evidence is the total probability of observing a measurement . It is calculated by integrating the likelihood over all possible true depths .
The posterior represent my updated belief about the true depth after seeing measurement . Per Bayes’ Theorem:
The marginal PDF and the posterior PDF look like this:
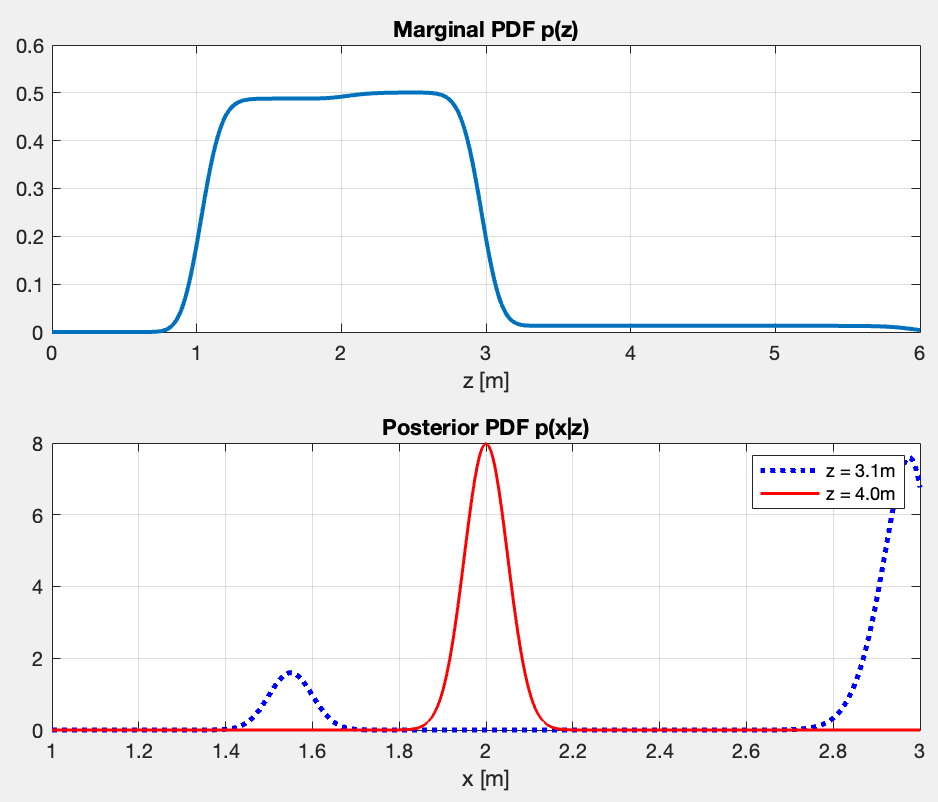
- The top plot shows the two plateaus — the taller one for corresponds to the chance of a direct reflection from the uniform prior . What follows is the plateau which corresponds to the echoes.
- “What measurement are we likely to see?”
- The bottom plot captures the two cases mentioned above.
- “Given I measured , what is the true depth ?”
- For , a direct reflection is impossible since the maximum known depth is (I know that from the prior). Therefore a measurement of cannot possibly be a direct echo. The model infers it must be a double reflection which happens at , resulting in the distinct, confident peak at exactly .
- The case regarding is ambiguous and presents two conflicting possibilities. It could be a double reflection, meaning the true depth is half of the measurement (the first small peak at ). Alternatively, it could be a direct reflection of a true depth very close to the maximum, pushed up to by sensor noise. Since direct reflections are highly probable, the model strongly leans toward this explanation, causing the massive spike at the boundary.
Third Question: Create m-files that calculate:
- The MMSE estimator for and for .
- Minimum Mean Square Error calculates the expected value, or the center of mass, of the posterior distribution. It minimizes the squared error of the estimate, meaning its position is influenced by all possible outcomes, including the small distant probabilities of secondary echoes.
- The MAP estimator for and for .
- Maximum A Posteriori maximizes the posterior distribution . It identifies the absolute highest peak of the combined probability, representing the single most likely depth when both the sensor measurement and the prior bounds are factored in.
- The MMAE estimator for and for .
- Minimum Mean Absolute Error calculates the median of the posterior distribution. It finds the exact depth that divides the total probability area perfectly in half, making it more robust against distant secondary peaks than the MMSE. (look more into this)
-
- In other words, minimize the expected absolute error . The solution is provably the median of the posterior, hence finding where the CDF(Cumulative Distribution Function) crosses 0.5.
- The ML estimator for and for .
- Maximum Likelihood maximizes the the likelihood function . It strictly trusts the sensor data and finds the depth that makes the observed measurement most probable, completely ignoring the prior knowledge from the nautical map.
Can you explain the results, especially the ones for ?
Results:
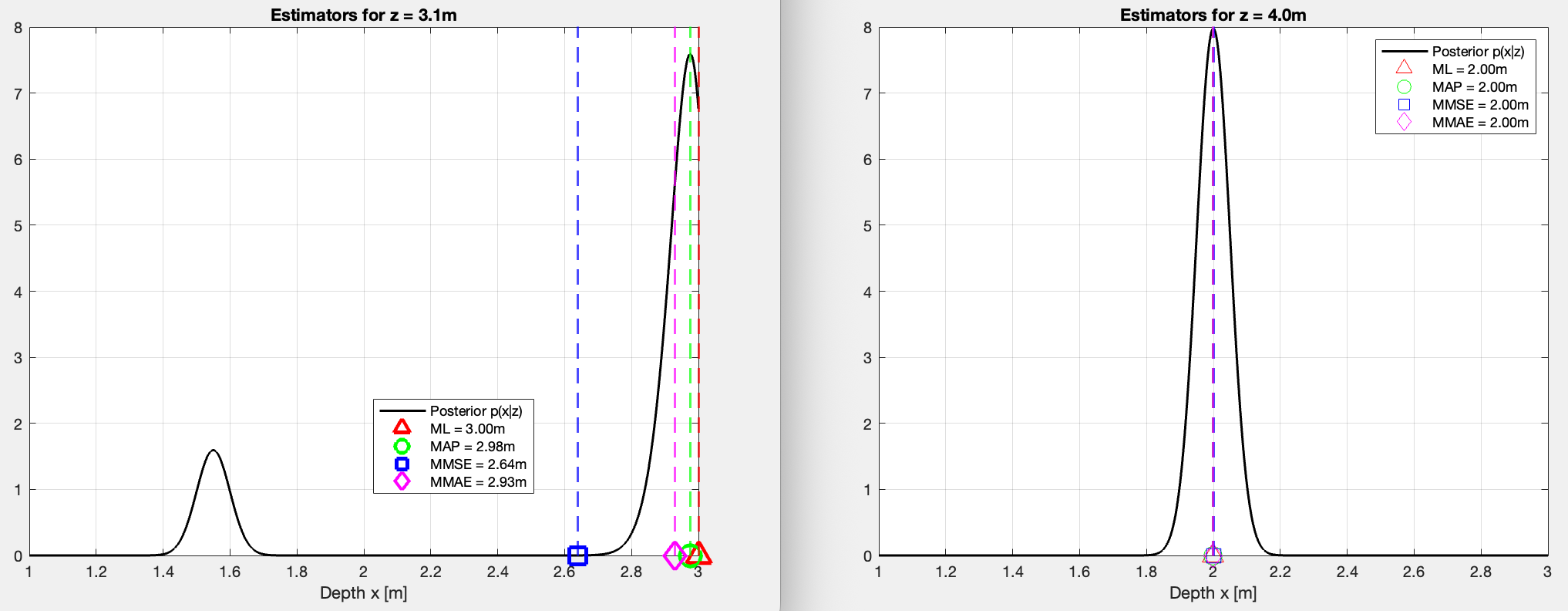
z=4m
All four estimators agree at . The posterior is unimodal so, naturally, all estimators converge because the prior eliminates any chance of a direct echo.
z=3.1m
In this case, the posterior is bimodal (two peaks which I explained earlier).
-
The MMSE is the only one that’s pulled more to the left since it acts as a center of gravity. It does incline towards the correct answer, but in this case the value of 2.66 doesn’t make sense given the posterior.
-
The MAP is the same as ML but multiplies the likelihood by the prior first. The prior slightly penalizes since it’s near the boundary, nudging the peak marginally left to . Very close to ML here because the likelihood peak dominates.
-
The MMAE integrates the posterior from left to right until it has accumulated 50% of the total probability mass. The small left peak at contributes some mass, which means the point is reached slightly earlier than the MAP peak, pulling it to . Essentially asking “where is the middle of all the probability?”
p(x|z) CDF | 1| ___ | /\ /\ | / | / \ / \ 0.5|_ _ _ _/· · · ← median here |/ \ / \ | / | \/ \ 0|_____/ +-------------->x +------------>x -
The ML looks at and asks “for which x is this measurement most likely?”. It finds the peak of the likelihood. Since is just inside the prior boundary, the direct echo peak lands at . No prior involved at all.
Fourth+Fifth Question:
Calculate for each case in 3 the conditional risk. Compare and explain the results. Do that for any of the following cost functions:
- Quadratic cost function
- Absolute cost function
- Uniform cost function with . The definition of is if
The risks that are calculated may have a physical unit. Don’t forget to add them.
From The Estimation Paradigm, the risk is defined as the expected cost of an estimation error:
z = 3.1m
| Estimator | Quadratic (m²) | Absolute (m) | Uniform (-) |
|---|---|---|---|
| MMSE | 0.3098 | 0.4435 | 0.9997 |
| MAP | 0.4100 | 0.3211 | 0.4838 |
| MMAE | 0.3819 | 0.3071 | 0.4732 |
| ML | 0.4258 | 0.3406 | 0.6333 |
z = 4.0m
| Estimator | Quadratic (m²) | Absolute (m) | Uniform (-) |
|---|---|---|---|
| MMSE | 0.0025 | 0.0399 | 0.3168 |
| MAP | 0.0025 | 0.0399 | 0.3267 |
| MMAE | 0.0025 | 0.0399 | 0.3267 |
| ML | 0.0025 | 0.0399 | 0.3267 |
- For all estimators agree, so the risks are nearly identical across estimators for each cost function. The posterior distribution is unimodal, meaning there is only one logical explanation for the measurement.
- For each estimator is lowest on its own cost function (MMSE lowest quadratic, MMAE lowest absolute, MAP lowest uniform) — exactly as the theory predicts.
- The uniform risk of MMSE at is nearly , meaning it almost always falls outside the window. Since the uniform cost function penalizes any estimate outside the 0.05m threshold, and there is virtually zero probability mass in that valley, the MMSE is almost guaranteed to incur the maximum penalty.