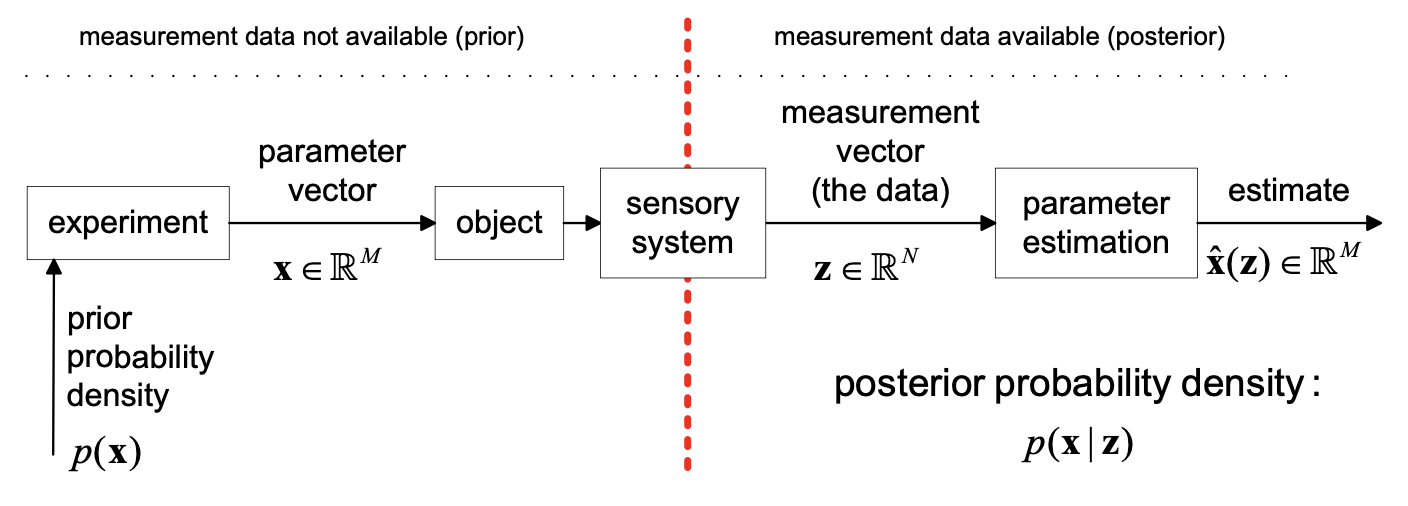
Estimation Paradigm
In the static case, we aim to estimate a fixed parameter vector that does not change over time, based on a set of measurements .
- Physical Process: The source of the parameter .
- Sensory System: Maps the physical parameter to a measurement vector .
- Estimator: A mathematical function that produces an estimate of the true parameter based on the observed data.
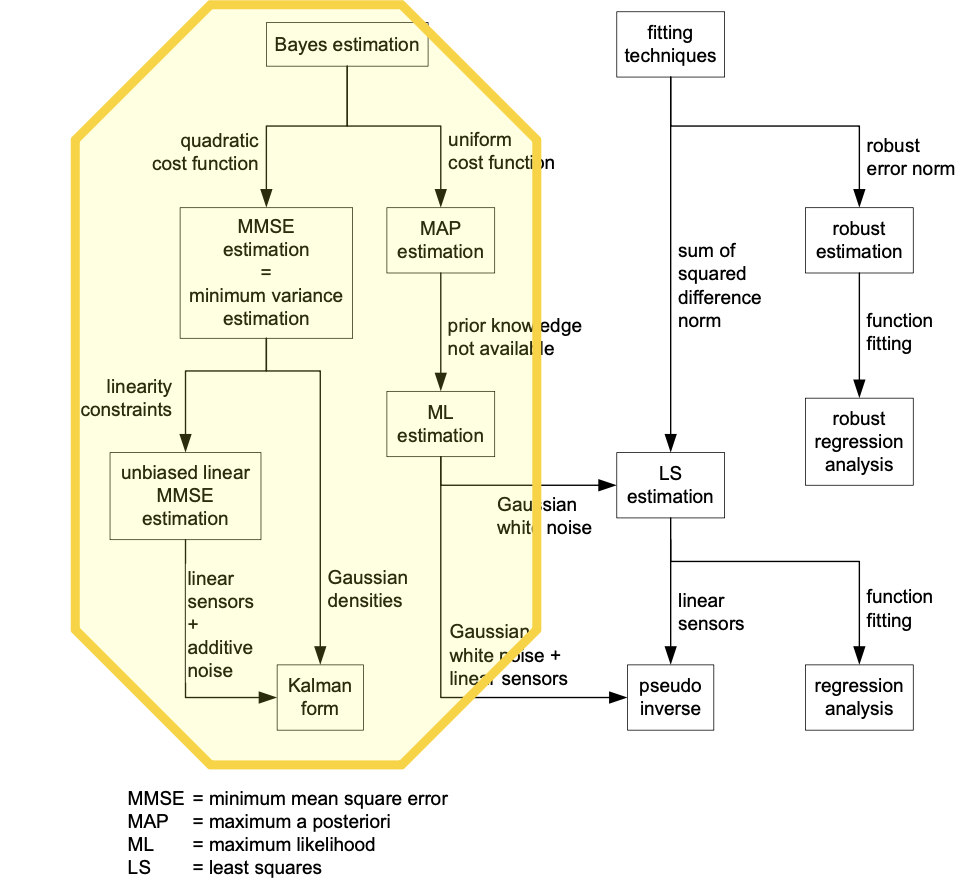
Two Primary Design Approaches
A. Bayesian Approach
Uses a probabilistic model including prior knowledge. It minimizes a “probabilistic risk” based on a cost function.
- Requires: Prior PDF and Likelihood .
B. Data Fitting Approach
Focuses on a measurement model and residuals (the difference between measured data and model-predicted data).
- Goal: Minimize an error norm of the residuals (e.g., Least Squares).
The Bayesian Framework
The Bayesian approach relies on Bayes’ Theorem to calculate the Posterior PDF, which combines prior beliefs with new evidence:
The Estimation Process:
- Define Prior PDF (what we know before measuring).
- Define Likelihood (the sensor model).
- Calculate Posterior PDF (updated knowledge after measurement).
- Minimize Conditional Risk . Where is the expected value of state , given measurement .
Risk is defined as the expected cost of an estimation error . The Bayes’ optimality criterion looks to minimize this integral.
Where is the cost function in the scalar case (quadratic, uniform, absolute value), with
- the true parameter
- the estimated parameter
- the estimation error
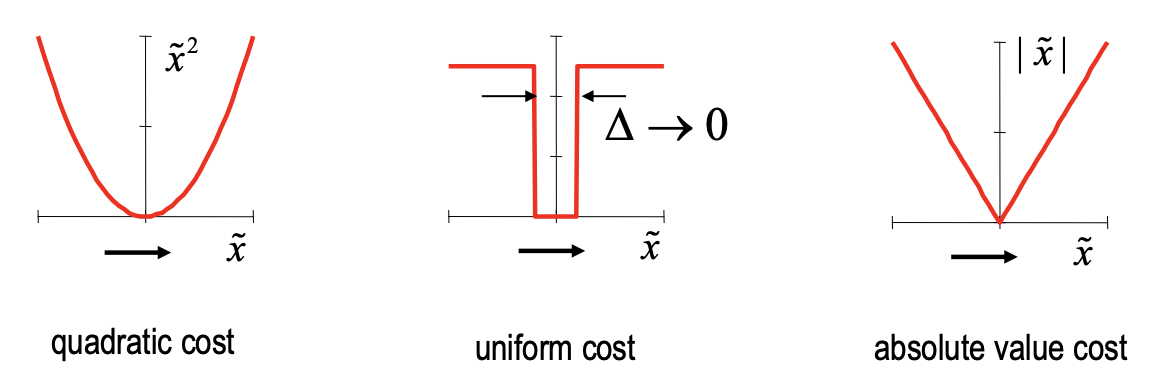
The overall risk is over all . I don’t know if I will have to use this form ever, but here it is:
Bayes (minimum risk) estimators
- Quadratic cost Conditional mean (MMSE)
- You want to minimize squared error:
- Absolute cost Median (MMAE)
- You want to minimize absolute error:
- Uniform cost Mode (MAP)
- You get penalized equally for any error, but zero cost if exactly correct
A quick example from Claude to help me understand these three concepts.
Imagine you’re trying to estimate someone’s age based on their appearance ( = how they look). You have some uncertainty, so your belief is a probability distribution .
Let’s say this distribution shows they’re likely between 25-35, with possibilities:
- 25 years: 10% chance
- 30 years: 70% chance
- 35 years: 20% chance
Now you must give ONE estimate. Which do you choose?
Quadratic cost (mean):
- If you’re wrong, the penalty grows with the square of your error
- Being off by 10 years is MUCH worse than being off by 5
- Best estimate: weighted average = 0.1×25 + 0.7×30 + 0.2×35 = 30.5 years
Absolute cost (median):
- If you’re wrong, penalty is just the absolute difference
- Being off by 10 is exactly twice as bad as being off by 5
- Best estimate: the middle value = 30 years
Uniform cost (mode):
- You either get it exactly right (no penalty) or wrong (same penalty regardless)
- Best estimate: most likely value = 30 years (the 70% one)
Different loss functions different “best guess” from the same distribution.
Maximum Likelihood Estimation (MLE)
Also covered in MLE. Basically, we use this when no prior knowledge of is available (i.e. with ).
The MAP estimator in this case becomes the ML estimator: