This is the continuation to Fundamentals of parameter estimation - Part I. Exercise 2/8 from my optimal estimation course. The focus is on linear MMSE and unbiased linear MMSE.
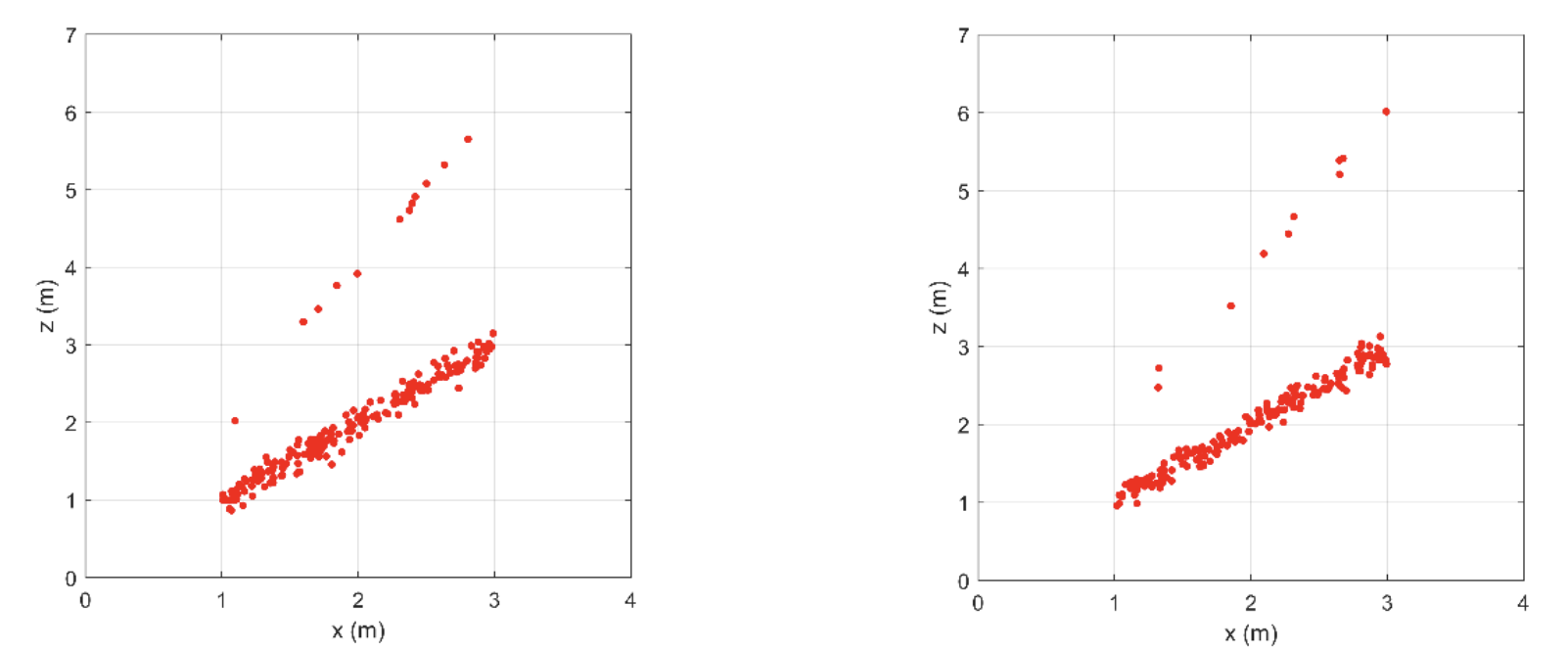
I need to reconsider the ultrasonic depth gauge discussed in Part 1. The Figure below shows two data sets that are obtained from the probabilistic model. Each data set contains 200 points . The realizations are a-select and independent.
The goals, in the end, are:
- To design a linMMSE estimator and an unbiased linMMSE estimator using the first data set.
- To evaluate these estimators with respect to bias and variance using the second data set.
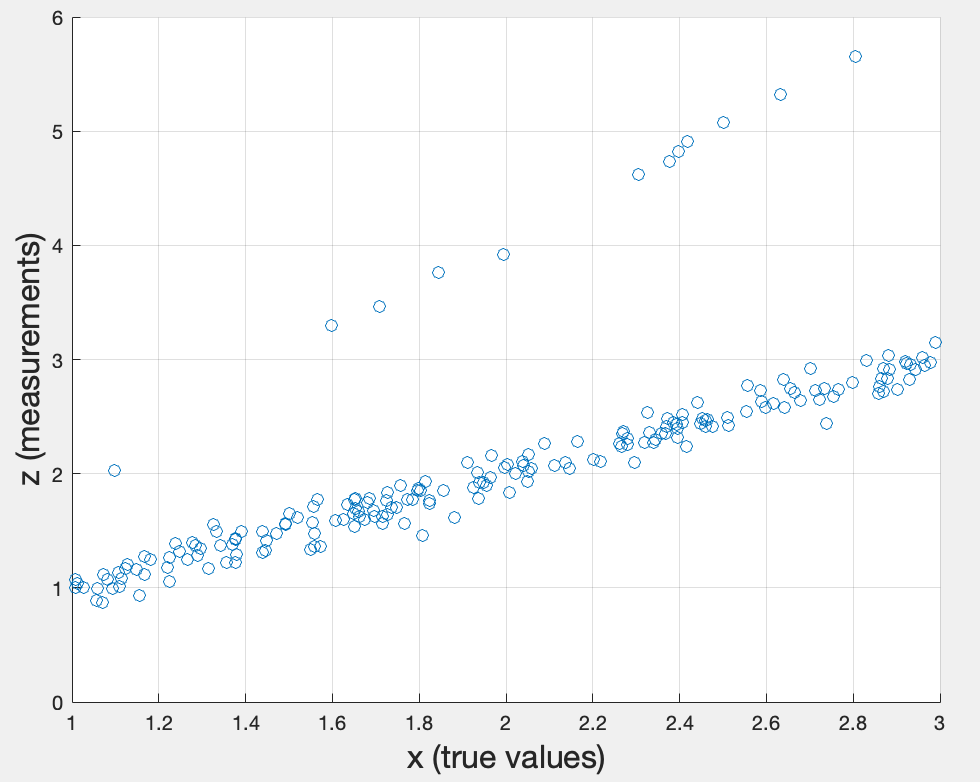
First topic: Create an xy-scatter diagram showing the true values against the measurements .
Second topic: Design a linear MMSE estimator , i.e. determine , using estimates of and derived from the first data set.
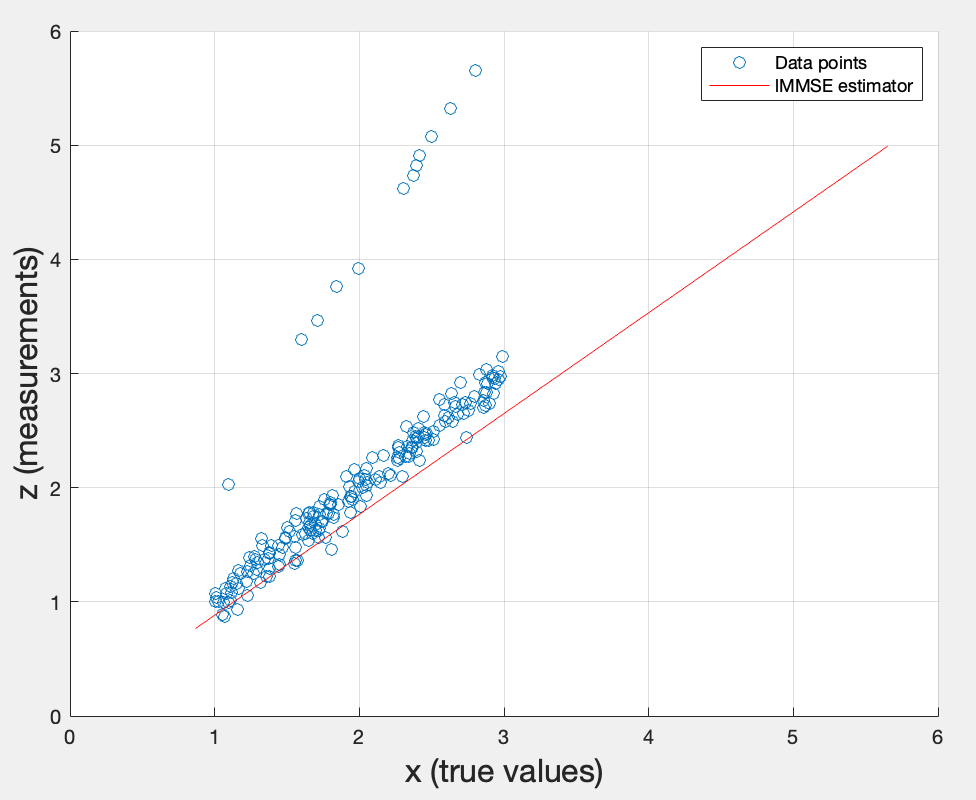
The line represents the best linear estimate of given , passing through the origin (since there’s no offset ). It fits the main cluster of data reasonably well, but the outliers in the upper-left — those are likely the secondary echo measurements from the depth gauge model — pull the estimator slightly off.
To derive the linear MMSE , I need to minimize the MSE cost function . Now I take the derivative of w.r.t. and set it to 0: . Distributing the expectations gives , which gives .
Third topic: Design the unbiased linear MMSE estimator , i.e. determine and , using estimates of , , , derived from the first data set.
According to the material, I can define the covariance between the two variables and like this:
In MATLAB, returns a matrix: . For that reason, it seems that I only need to select the second column from the first row.
From the provided equation, , I can deduce that .
Why? Because the unbiased linear MMSE estimator minimizes the MSE under the constraint that it is unbiased, meaning .
- Expanding with , I go further into .
- Now I minimize the MSE cost function by taking the derivative w.r.t. and setting it to 0.
- It simplifies to
- The left side is the definition of covariance, .
- The right side is the definition of variance, .
- Dividing the two gives
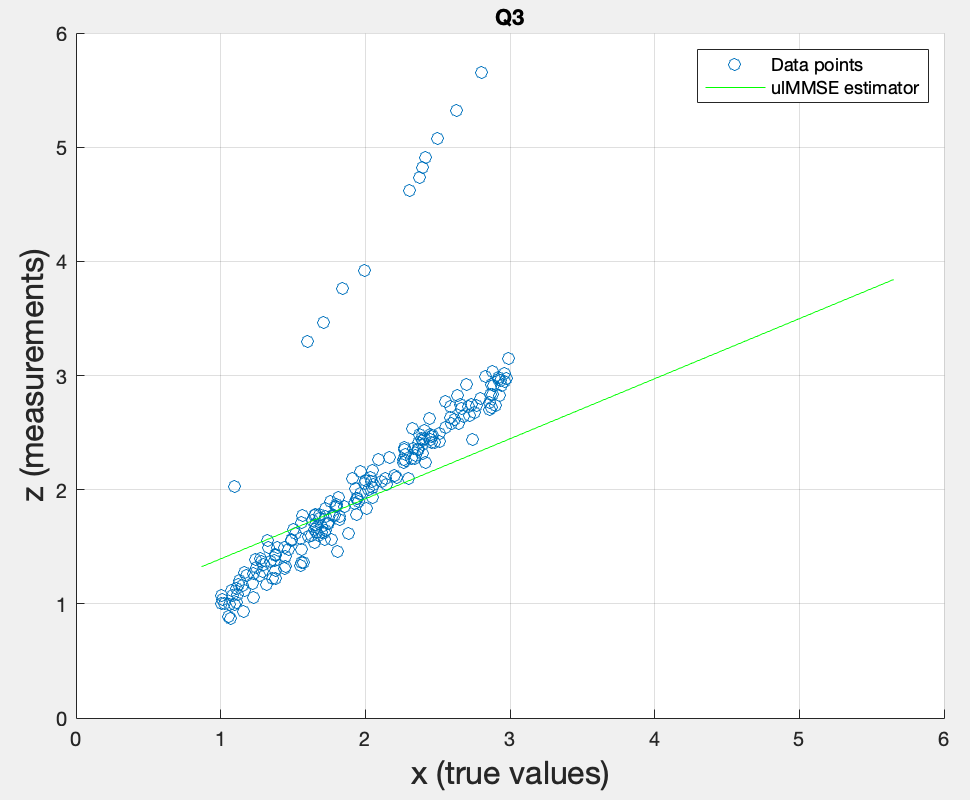
As a comparison, the ulMMSE line passes through the mean of the data (unlike the lMMSE which was forced through the origin), since the parameter allows the line to shift and pass directly through the mean value of the dataset. However, the outliers (secondary echoes) pull the overall mean slightly upward.
Fourth topic: Load the second data set. Apply the linear MMSE estimator that you have developed with the first set to the measurements from the second set. Determine the estimation errors . Estimate the overall bias (mean of the estimation errors) and the variance of the errors.
Going back to the second topic, I know . Therefore, I simply need to reuse the alpha from the second topic and apply it to this dataset.
Currently, I get a bias of -0.1488. It means the estimator systematically underestimates on average by ~0.15m. This is expected since lMMSE is forced through the origin and doesn’t account for the mean offset. The variance of 0.1993 reflects the spread of the errors.
Fifth topic: Do the same for the unbiased linear MMSE esimator.
| lMMSE (DS1) | lMMSE (DS2) | ulMMSE (DS1) | ulMMSE (DS2) | |
|---|---|---|---|---|
| Bias | -0.1179 | -0.1488 | 0.0000 | -0.0501 |
| Variance | 0.2238 | 0.1993 | 0.1349 | 0.1372 |
- ulMMSE has near-zero bias on dataset 1 (0.0000) because it was designed with the unbiased constraint using that same dataset. On dataset 2 the bias is small (-0.0501) but not zero, since it’s a different sample.
- ulMMSE has lower variance (~0.135) compared to lMMSE (~0.2) on both datasets, meaning it’s also more precise.
- lMMSE has notable bias on both datasets (-0.1179 and -0.1488) because it’s forced through the origin, ignoring the mean offset.
Sixth topic: Why did we need to use a second dataset?
A second dataset is needed because evaluating bias and variance on the same data used to design the estimator would be overly optimistic — the estimator was literally fitted to that data. Dataset 2 gives an honest, independent evaluation of performance.