Related to Reinforcement Learning.
Policy-based methods directly train the policy to select what action to take given a state (or a probability distribution over actions at that state) and the optimal policy () is found by training the policy directly.
- can be deterministic or stochastic
Definition
Value-based methods learn the value function that maps a state to the expected value of being at that state to have an optimal policy .
- is the value of a state
- is the expected discounted return of the agent if it starts in that state
State value functions
Two typologies of value-based functions:
- state-value function (denoted with ): it calculates the value of a state
- For each state, the state-value function outputs the expected return if the agent starts at that state s and then follows the policy forever afterwards (for all future timesteps, if you prefer).
- action-value function (denoted with ): calculate the value of the state-action pair .
- for each state and action pair, the action-value function outputs the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
To calculate EACH value of a state or a state-action pair is redundant.
Bellman Equation simplifies the state value or state-action value calculation.
In this course, we will focus on Epsilon Greedy -greedy policy that handles the exploration/exploitation trade-off.
There are two strategies on how train our value function or our policy function.
On-policy vs. Off-policy
On-policy = learning from policy’s own demonstrations
- Direct experience. Evaluates or improves the policy that is used to make decisions. Less sample efficient
- Examples: Value-Based Methods (Sarsa), Policy Gradient Methods (PPO, A2C, A3C)
Off-policy = learning from other policy’s demonstrations. Off-Policy Learning is the idea of evaluating target policy while following behavior policy .
- Evaluates or improves a policy different from that used to generate the data. More sample efficient.
- Examples: Value-Based Methods (Q-Learning, DQN), Policy Gradient Methods (DDPG, SAC, TD3)
Q-Learning is off-policy, but we only update states that we visited?
The fundamental difference is that the optimal policy is not followed from that. You learn about the optimal policy using data collected from a different policy.
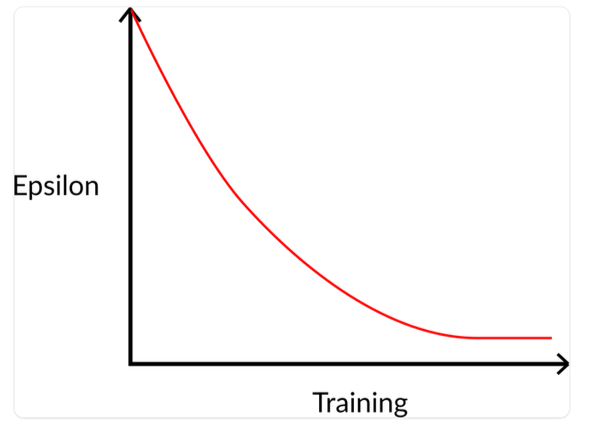
-greedy Exploitation/Exploration
The -greedy strategy is a policy that handles the exploration/exploitation trade-off. With an initial value of :
- With _probability : we do exploitation (aka our agent selects the action with the highest state-action pair value).
- With probability : we do exploration (trying random action).
At the beginning of the training, the probability of doing exploration will be huge since is very high, mainly exploring. But as the training goes on, Q-table estimates better, is reduced since we will need less and less exploration and more exploitation.