Reinforcement Learning (RL) was invented as a way to model and solve problems of decision making under uncertainty.
The goal is to maximize the expected sum of discounted rewards:
Terminology
Agent: Entity that perceives its environment and acts upon that environment. Learns through trial and error.
State: A configuration of the agent in its environment.
Actions: Choices that can be made in a state. Defined as a function:
- returns as output the set of actions that can be executed in state
s.The goal is to go from the initial state to the goal state by choosing actions.
Transition Model: A description of what state results from performing any application action in any state. In code:
RESULT(s,a)State Space: The set of all states reachable form the initial state by any sequence of actions.
Goal Test: The condition that determines whether a given state is a goal state.
Path cost: Numerical cost associated with a given path. Goal is to minimize this cost.
- gives the likelihood of a trajectory under policy .
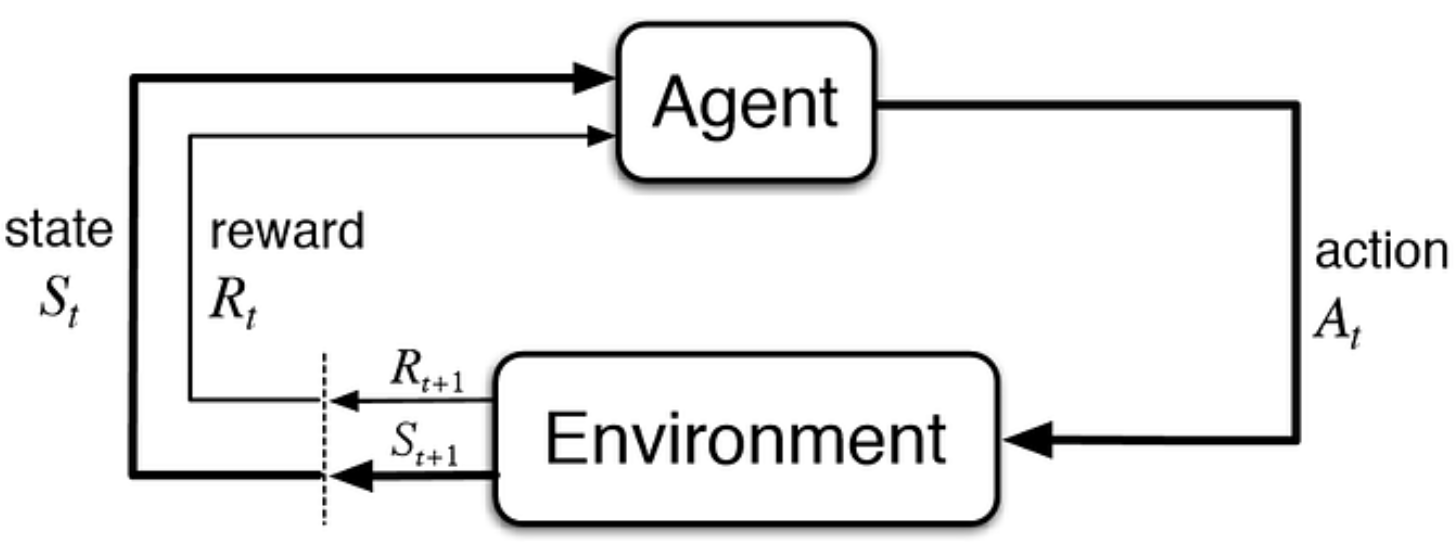
Contrast to other learning tasks:
- It is active rather than passive
- Interactions are often sequential
What makes reinforcement learning different from other machine learning paradigms?
- There is no supervisor, only a reward signal
- Feedback is delayed,
- not instantaneous
- Time really matters (sequential, non i.i.d data)
- Agent’s actions affect the subsequent data it receives
RL is like a one-size fits all solution.
Exploitation vs Exploration
- Exploration is exploring the environment by trying random actions in order to find more information about the environment
- Exploitation is exploiting known information to maximize the reward.
There is a trade-off. We need to balance the two.
Type of task in RL
- Episodic task: here is a starting point and an ending point (a terminal state). This creates an episode: a list of States, Actions, Rewards, and new States.
- Continuing task: These are tasks that continue forever (no terminal state). In this case, the agent must learn how to choose the best actions and simultaneously interact with the environment.
Policy
A policy is a mapping that, for every state assigns for every action the probability of taking that action.
- it’s the “brain” of the agent
- we want to find the optimal policy through training.
The goal of an RL agent is to find a behavior policy that maximizes the expected return .
“Any goal can be formalized as the outcome of maximizing a cumulative reward”
However, in reality, we can’t just add them like that.The rewards that come sooner (at the beginning) are more likely to happen since they are more predictable than the long-term future reward.Therefore we define the discount . Mostly between .
- larger ⇒ smaller discount ⇒ agent cares more about
long-term reward- smaller ⇒ bigger discount ⇒ agent cares more about
short-term reward
A MDP is considered “solved” if we find a policy that maximizes the expected discounted return. See Markov Decision Process.
- Deterministic policy: a policy at a given state will always return the same action.
- Stochastic policy: outputs a probability distribution over actions.
We need to find the optimal policy , which maximizes the expected return.
- Policy-based methods: by training your policy directly: the agent learns which action to take given a state
- This function will define a mapping from each state to the best corresponding action
- Value-based methods: by training a value function that tells us the expected return the agent will get at each state, and use this function to define our policy
Observations vs. States
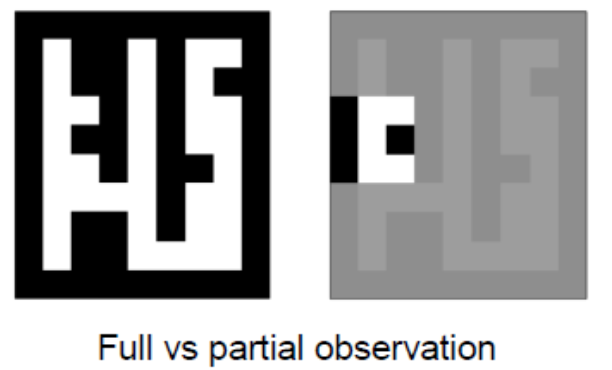
- State: is a complete description of the state of the world (no hidden info).
- Observation: is a partial description of the state.
- History: is the sequence of observations, actions, and rewards.
Discrete vs. Continuous Action space
- Discrete Space: finite number of actions
- Continuous Space: infinite number of actions
kinda intuitive
State values functions
Two typologies of value-based functions:
- state-value function (denoted with ): it calculates the value of a state
- For each state, the state-value function outputs the expected return if the agent starts at that state s and then follows the policy forever afterwards (for all future timesteps, if you prefer).
- action-value function (denoted with ): calculate the value of the state-action pair .
- for each state and action pair, the action-value function outputs the expected return if the agent starts in that state, takes that action, and then follows the policy forever after.
To calculate EACH value of a state or a state-action pair is redundant.
Bellman Equation simplifies the state value or state-action value calculation.