Related to Value Based Methods.
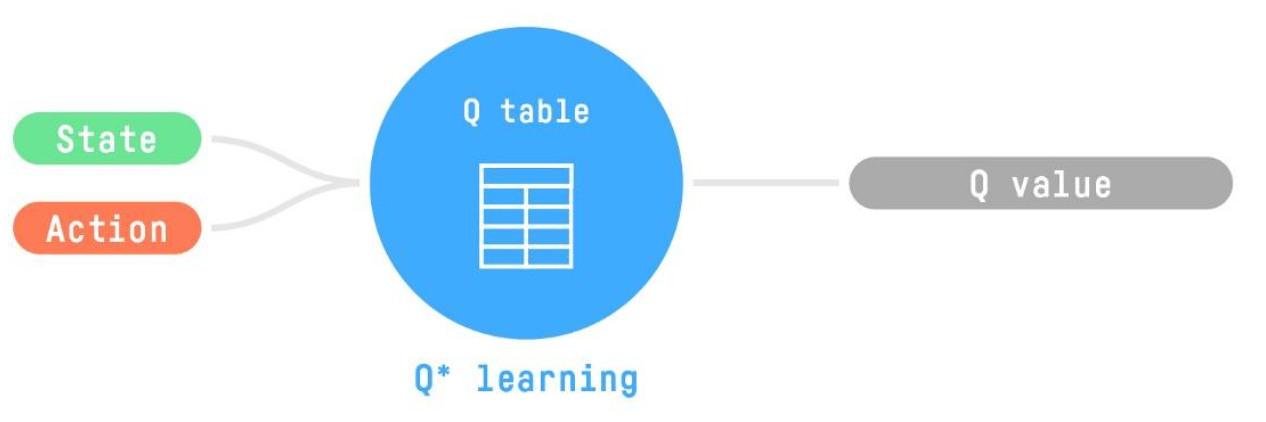
Q-Learning is an off-policy value-based method that uses a TD approach to train its action-value function.
DQL is for the continuous state case. instead of using a table, uses a Neural Network that takes a state and approximates Q-values for each action based on that state
Tabular Q-Learning
- Consider off-policy learning of action-values
- Next action is chosen using behavior policy
- But we consider alternative successor
- We let
- And update towards value of alternative action
Q-Learning Properties (Off-policy learning)
Q-Learning converges to optimal policy — even if it’s acting suboptimally
Q-learning generally uses the 1-step bellman optimality backup
Q-learning can produce excellent results for relatively small environments because each state space is discrete and small. For comparison, the state space of a simple video game could contain few billion states, making it practically useless
- Sarsa is the on-policy version of Q-learning
Off-policy Control with Q-Learning
- We now allow both behavior and target policies to improve
- The target policy is greedy w.r.t.
Q-Learning control algorithm:
- is the off-policy target aspect: this is what makes Q-learning “off-policy”. Instead of looking at the action the agent actually chooses next, it looks ahead to the next state and assumes it will select the absolute best possible action () available there.
