Off-policy and Value Based Method.
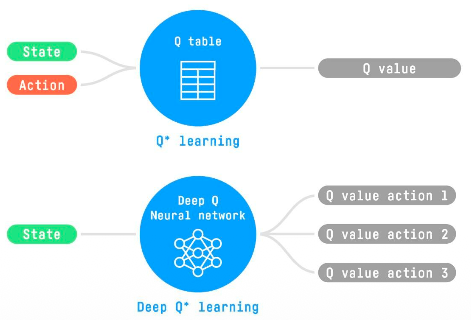
Deep Q-learning or DQN (Deep Q-Network) is exactly the same as Q-Learning, except that instead of using a Q-table, we use a function approximator (i.e. NN) with to approximate .

Why was the
tabular methoda problem in the first place?Because it’s not scalable. It works best for state and action spaces that are small enough to be represented efficiently by arrays and tables.
Think of the
Atari environmentswhere we have an observation space with a shape of containing values ranging from 0 to 255.
- that would give us possible observations
- more than Atoms in the Universe.
Workflow Example
- Input: 4 frames that go through the NN.
- the size of the input is fundamental to reduce the complexity and the processing time of the training.
- a common practice in Atari is to use
grayscale. - stacking four frames together helps us handle the problem of temporal limitation.
- Output: vector of Q-values (a couple of fully connected layers) for each possible action at that state.
- so it’s dense CNNs?
- The DQN architecture uses dense (fully connected) layers on top of convolutional layers, so it’s a hybrid CNN + MLP.
- Conv layers (3 of them) — extract spatial features from the stacked frames
- Dense/FC layers — take those flattened features and map them to Q-values for each action
- The DQN architecture uses dense (fully connected) layers on top of convolutional layers, so it’s a hybrid CNN + MLP.
- so it’s dense CNNs?
Been thinking about this. Do we optimize for the time as well? As in, the faster you reach the goal; the better, no?
In many environments, you give a small negative reward per timestep, which incentivizes the agent to reach the goal faster.
It’s more environment-specific, not something DQN introduced.
DQN Training
It’s split in 1) Sampling and 2) Training.
- The network is updated by minimizing the TD error between predicted and target Q-values
- Q-prediction: what the network currently outputs
- Q-target: what it should output
- same Bellman equation we know from Q-Learning
- The loss is the squared difference between them:
- A gradient descent is used to update the weights of our DQN
- The Target Neural Network is not trained and remains fixed
- At the end of the batch, Q Neural Network weights are copied to the Target Q network… and a new iteration begins.
| Symbol | Meaning |
|---|---|
| Current network weights (being trained) | |
| Frozen target network weights (updated less often) | |
| Preprocessed current state (stacked grayscale frames) | |
| Q-value estimated by the target network | |
| Pick the best action in the next state | |
| | The TD target — treated as a fixed label during the update |
We can write the loss term in another form to understand even better:
- is the
Done flag. 1 ifterminal stateor 0 if not. - is the replay buffer — stores past transitions to sample from
- masks out future value when episode has ended
Why , why not just use as the target?
That’s what we do in the Tabular Q-Learning case, because every time we update the Q-table, only 1 entry changes.
In the continuous case, when we do a gradient update on , any parameter change can drastically alter the function landscape. If we set the target with the same and do a gradient update, this target will shift as fast as your weights do. This feedback loop causes divergence and instability.
Sampling
Basically the buffering process. It starts with arbitrary Q-value estimates and explores the environment using the -greedy policy. It gets
Rewardandnext State.
We train on the replay buffer, which makes of past observed experience tuples. So basically we train on the test set. I guess RL is the only field where you can do this.
Stabilize the training
We need to stabilize the training mainly due to the combination of a non-linear Q-value function approximator (NN) with bootstrapping (where we update targets with existing estimates rather than the actual complete run).
Three different solutions were therefore implemented.
- Experience Replay efficient use of experiences
- The replay buffer concept from before. Reuse past experience during training.
- Reduce correlation between experiences (how??) and avoid forgetting bottlenecks.
- Apparently we remove correlation by randomly sampling the experiences. It helps with preventing oscillation and divergence.
- (e.g. frames from the same game sequence) are highly correlated — random sampling mixes them up so the network doesn’t overfit to recent trajectories.
- Apparently we remove correlation by randomly sampling the experiences. It helps with preventing oscillation and divergence.
- Fixed Q-Target stabilize the training by chasing a fixed target, not a moving one.
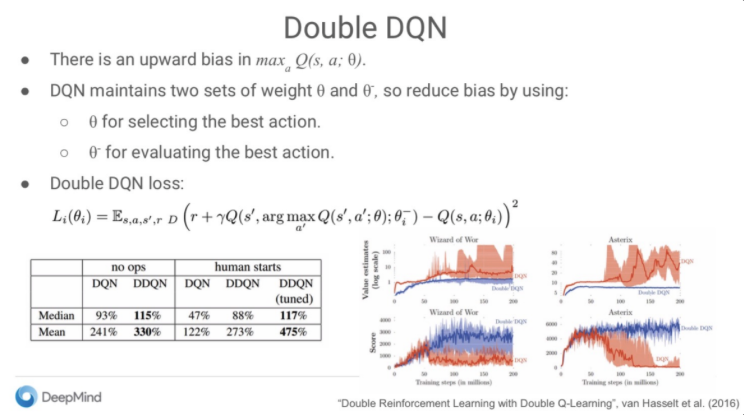
- Double Deep Q-Learning (DDQN) handle overestimation of Q-values.
DDQN is the norm now. It’s simply better.
In standard DQN, the same network both selects and evaluates the best action, which inflates Q-values. DDQN helps decouple the action selection from the target network and therefore reduces the overestimation of Q-values and, as a consequence, helps us train faster and with more stable training.