The point of actor critic is to decouple the gradient update from the Q-function update.
- Policy-based methods directly optimize the policy but have high variance
- Value-based methods estimate values but don’t give a parametrized policy.
Unlike Q-Learning (value based), which directly attempts to learn the optimal Q-function, actor-critic methods aim to learn the Q-function corresponding to the current parametrized policy , which must obey the equation:
Methods
Definition
Actor-Critic is a hybrid architecture combining value-based and policy-based methods that helps to stabilize the training by reducing the variance using two elements:
- actor controls how our agent behaves (policy-based)
- critic measures how good the taken action is (value-based)
Needless to say, the two learn in parallel. The actor learns the policy and the critic assists the policy update by measuring the performance of the action that we take .
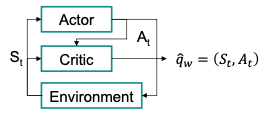
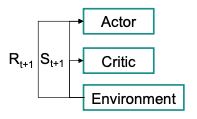
The workflow is straightforwards:
Step 1: At each timestep t, we get the current state from the environment and pass it as input through our Actor and Critic the policy takes the state and outputs an action .
Step 2: The Critic takes as input and, together with , it computes the value of taking that action at that state (i.e. the Q-value).
Step 3: The performed action outputs a new state and a reward .
Step 4: The Actor updates it policy parameters using the Q-value.
Step 5: The Critic then updates again its value parameters .
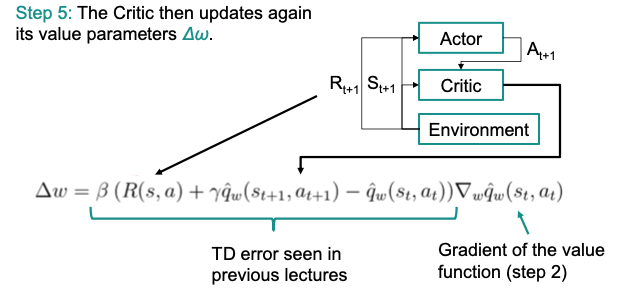
Note that the policy and value have different learning rates (i.e. and )
Improvements — Advantage function
Advantage function
calculates the relative advantage of an taking an action compared to the average value of the state.
- is the average value of that state.
Therefore is the TD Error.
We use instead of since acts as a baseline, centering the updates around 0, which directly reduces variance without introducing bias.