Related to Actor Critic Methods.
SAC is an off-policy actor-critic algorithm but adds an entropy term to the reward, encouraging the policy to explore more by remaining stochastic during training.
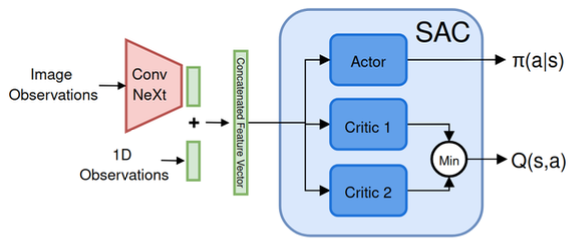
It uses two critic networks like TD3 to reduce overestimation in bias and improve stability.
SAC qualities:
- stable training by reducing overestimation
- exploration: entropy regularization prevents early convergence.
- sample efficiency: off-policy learning (replay buffer) improves data usage.
- automatic tuning: learns to balance exploration and exploitation.
- continuous actions: naturally handles high-dimensional action spaces.