I have an assignment in my laser scanning class that involves training a PointNet++ model. However, I wanted to understand what PointNet even is, because the slides are just too bad.
Source: paper
First of all, I need to explain the following term
Invariant to permutations
Point Clouds are 3D points defined by their coordinates in space plus extra feature channels such as color, normal etc. However, they are natively unordered. I cannot tell you anything about two points other than that they are at different positions. If we’re talking about images, pixel order matters. So, point clouds are unordered sets (no reason why point #1 comes before #47. Therefore, their implementation respects this property by applying max pooling.
So, if I feed a point cloud to a NN, I pass it as an array "". But if I shuffle this array in any way I want, it’s still the same object!
So, invariant to permutation equals something of the sort:
Max Pooling: a symmetric function which collapses many values into one like this
Ok but why max-pooling?
Because it’s symmetric by definition, and it helps with picking the most prominent features from any point in the cloud. The result is a single global fixed-size feature vector that summarizes the entire point cloud, regardless of how many points there were.
Claude says the dropped points simply get dropped.
I see it as a PCA of Point Clouds.
The resulting vector then gets fed into a MLP. This solved unnecessary voluminous transformation techniques such as 3D voxel grids or collections of images. In the sense that it’s much faster and performed on par / even better than state-of-the-art solutions at that time.
PointNet misses local structure (clusters). That's where PointNet++ comes into play.
- Farthest Point Sampling — pick N “center” points that are spread out across the cloud
- Ball query — for each center, grab all points within a radius r
- Apply PointNet to each local cluster get one feature vector per cluster
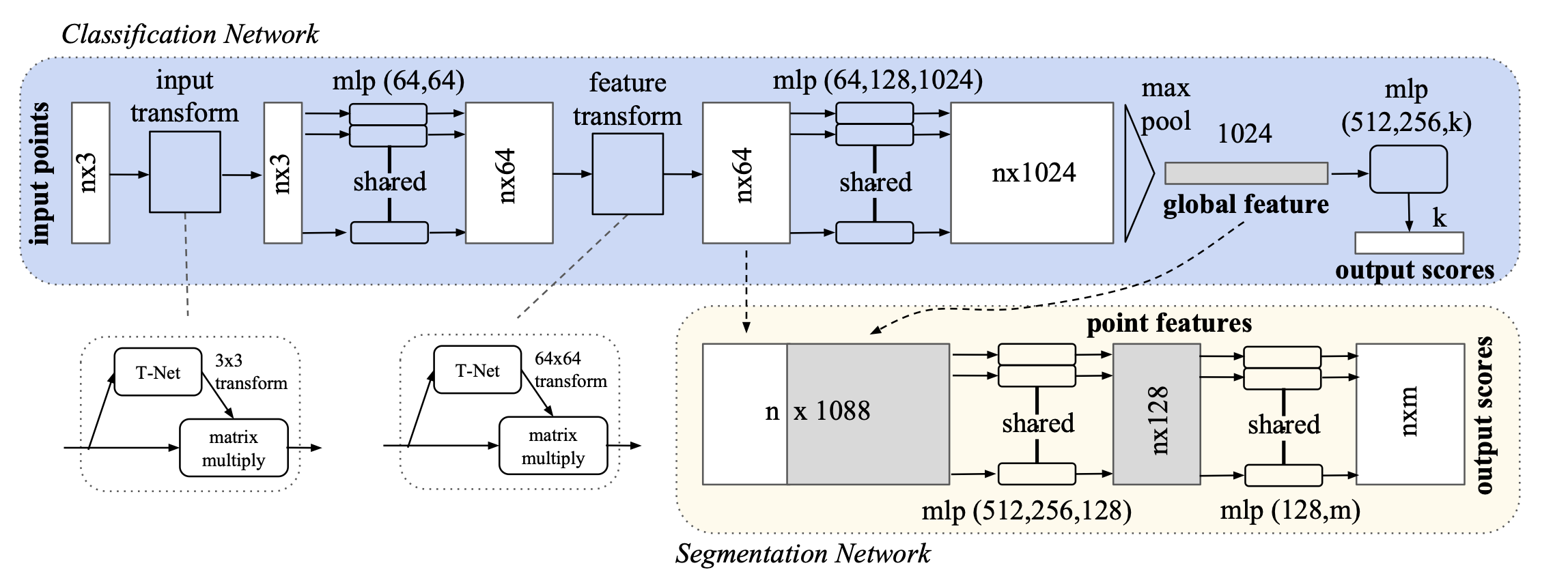
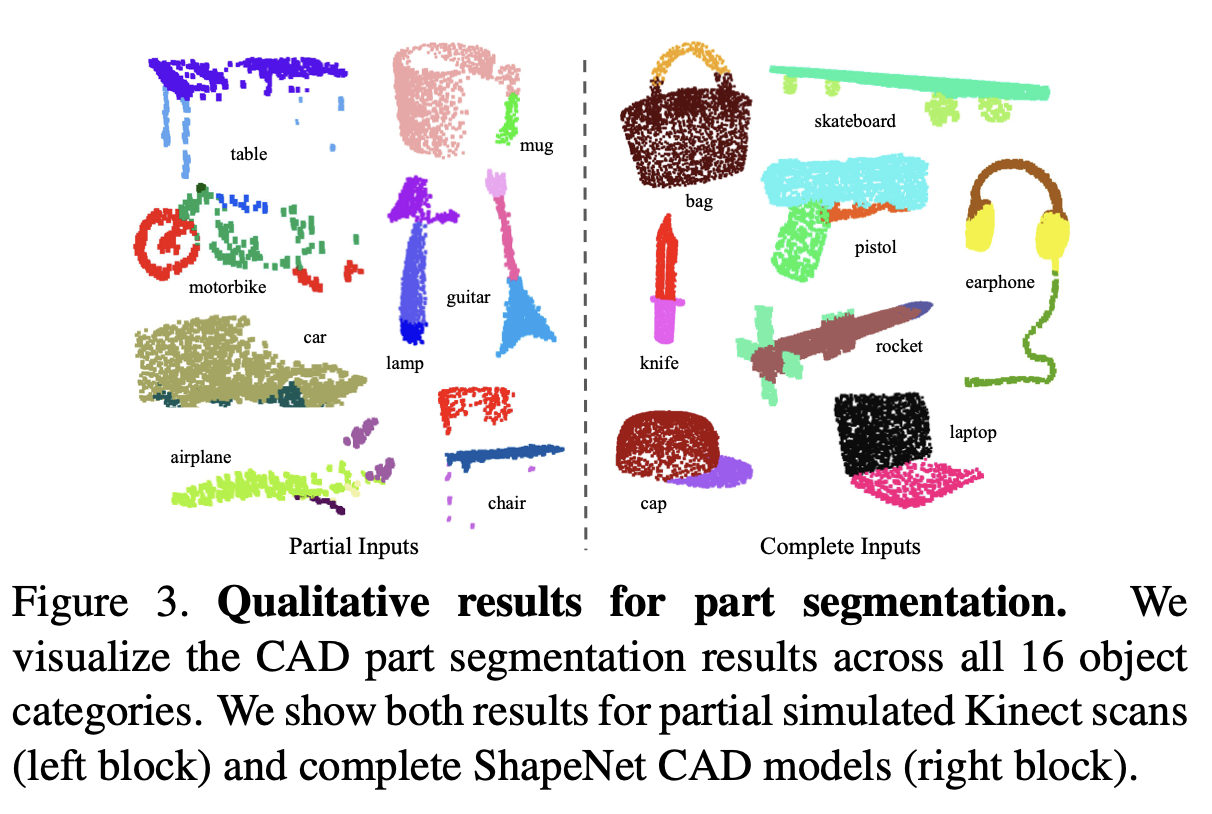
For the object classification task, the input point cloud is either directly sampled from a shape or pre-segmented from a scene point cloud. Our proposed deep network outputs scores for all the candidate classes. For semantic segmentation, the input can be a single object for part region segmentation, or a sub-volume from a 3D scene for object region segmentation. Our model will output scores for each of the n points and each of the m semantic sub- categories.
Honestly, I struggled a bit to understand the Figure above and this part.
- From Claude: PointNet takes a point cloud, passes each point through an MLP independently, then max-pools across all points to get one global feature vector. For classification, that vector gets mapped to class scores. For segmentation, that vector gets concatenated back with each point’s local features, and every point gets its own label. The max-pool is the key trick that makes it order-independent.
The Classification and Segmentation share the same MLP. They only differ in what comes after the global vector — classification just maps it to class scores, segmentation feeds it back to each point.