This lecture covers 4 families of pretext tasks for self-supervised pre-training.
The big picture is that, instead of labels, we invent a pretext task that forces the network to learn useful representations from raw data alone, then transform those features to real downstream tasks.
invariance-based methods = apply a bunch of augmentations to the original image, and make sure the embeddings generated from those images are very similar (invariant to augmentations)
Pretext task 1: Vision-language score — CLIP SigLIP GLIP
- CLIP: encode image and text in the same space. The similarity between two normalized vectors simply comes down to their cosine similarity, which is what CLIP maximizes. The temperature is a hyperparameter which helps with numerical stability (controls how peaked the softmax/exponential output is).
- Dividing by a small , we get a sharper and more confident distribution, as small similarity differences get amplified into big probability differences
- Dividing by a big , we get a softer distribution; where differences get washed out.
- So basically, scaled so gradient are informative rather than mushy. In DINO, the teacher temperature is smaller so its output is sharper/more confident than the student’s.
- SigLIP: an improved version of CLIP which introduces sigmoid-based contrastive loss instead of the traditional softmax-based contrastive loss. This training loss eliminates the need for a global view of all pairwise similarities between images and texts within a batch. It transforms the problem into independent binary classifications. Since we don’t need to gather everything onto one device before computing the loss ⇒ much easier to scale to huge batch sizes across many GPUs .Consequently, it enables more efficient scaling to larger batch sizes while also delivering superior performance with smaller batch sizes.
- also introduces a learnable bias () to offset the huge negative-to-positive ratio. Because out of pairs per batch, only are positive. That’s what is for — a learned bias that shifts the decision threshold so the sigmoid isn’t just trivially predicting negative for everything to minimize loss.
- is the ground-truth label.
- TL;DR: Cheaper, scales better.
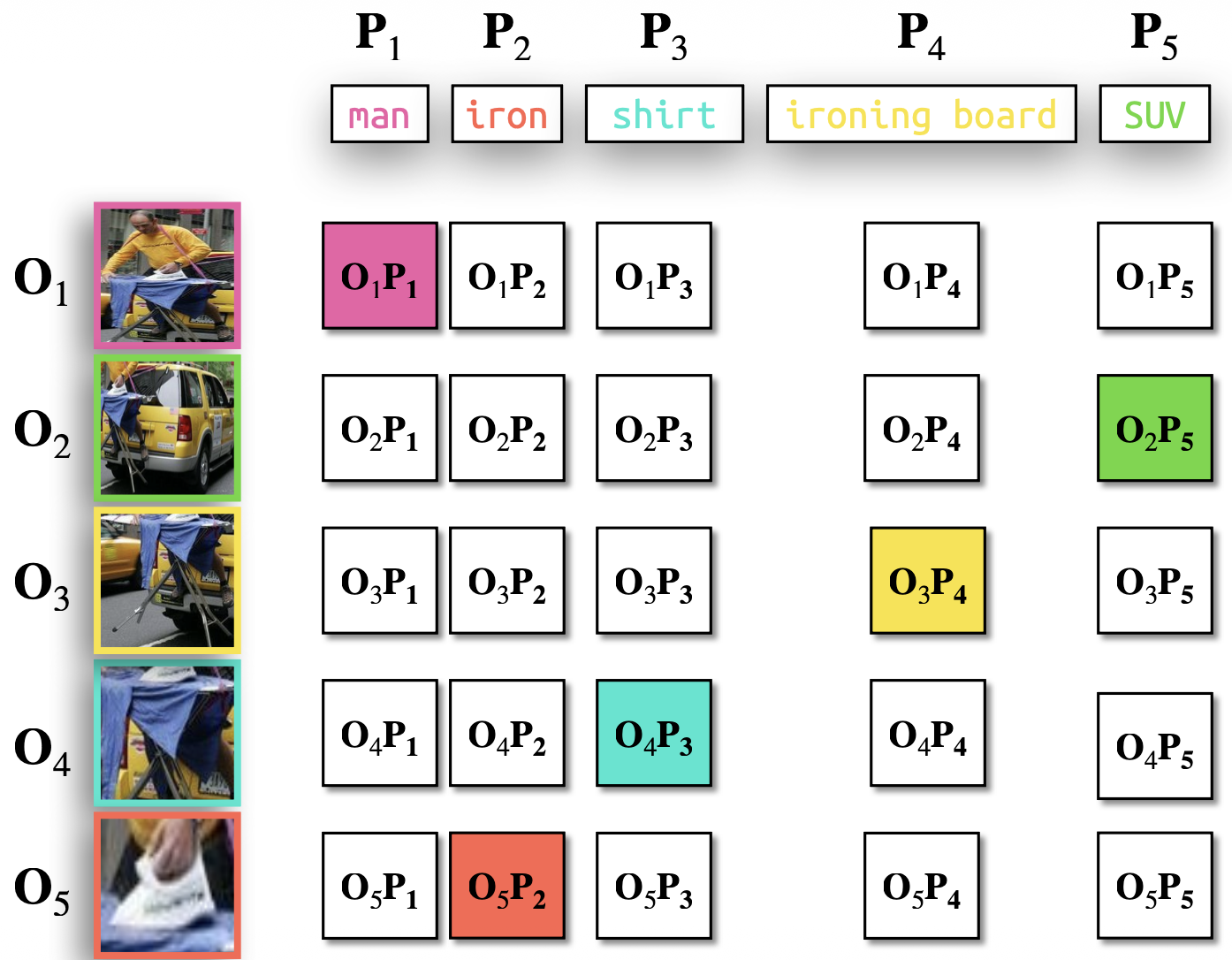
- GLIP (Grounded Language-Image Pre-training): unifies object detection and text-image grounding. It extends alignment from whole-image/whole-caption to region phrase grounding
- compute a similarity matrix between detected object regions (O) and text phrases (P), add a localization loss on top of the classification loss.
Phrase Grounding
the process of mapping specific words or textual phrases to their representations within an image or video
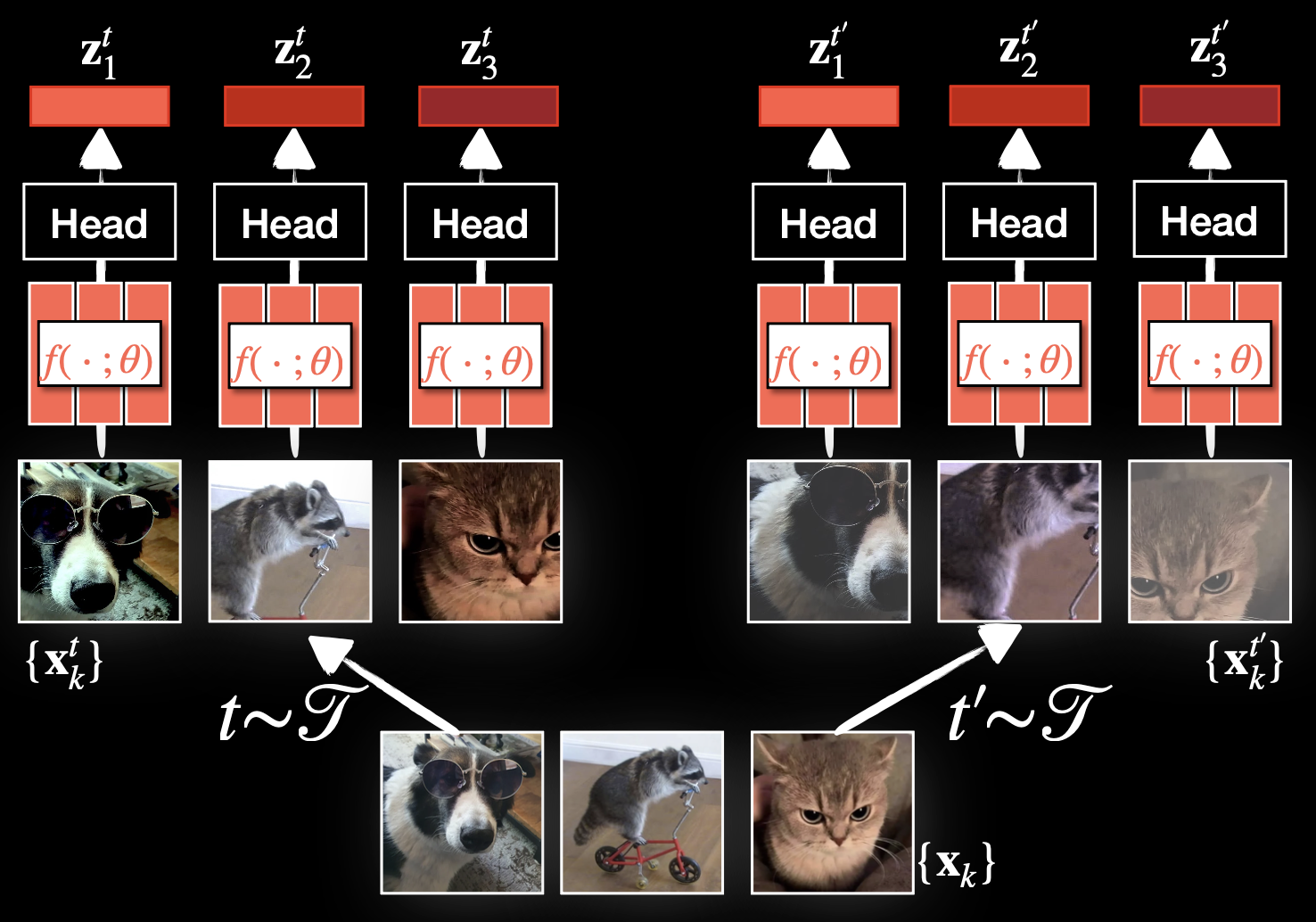
Pretext task 2: Negative samples (Contrastive) — SimCLR MoCo
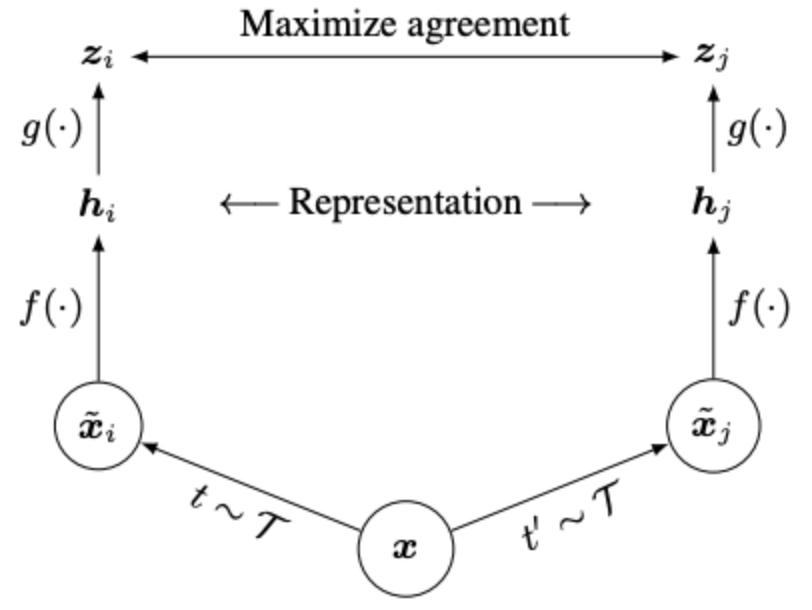
- SimCLR (Simple framework for Contrastive Learning of visual Representations): Two separate data augmentation operators ( and ) are applied to each data example to obtain two correlated views. A base encoder network and a projection head are trained to maximize agreement using a contrastive loss. After training we throw away and use encoder and representation for downstream tasks.
- The pipeline:
- is the augmentation distribution (random crop + color distortion + Gaussian blur + invert + flip .. etc. first three I think are crucial)
- is where the contrastive loss is applied. Representation is trained to be invariant under augmentation — that collapses useful signal (e.g. color, orientation). sits one MLP away, so it keeps information that had to throw out. Linear eval on beats linear eval on consistently; SimCLR ablation table shows non-linear projection head points better than no head.
- Minibatch algorithm: For a minibatch of images:
-
- Draw , apply both to every image ⇒ augmented views
-
- Encode with shared encoder + projection .
-
- Build affinity matrix — cosine similarity, shape . .
-
- For each row , the positive is at position or (partner view of the same source image); all other entries are negative.
-
- InfoNCE per row:
- Total loss averages over all source images. Quality scales with number of negatives, which scales with batch size compute, which makes it infeasible at scale. That’s where MoCo comes in.
-
- The pipeline:
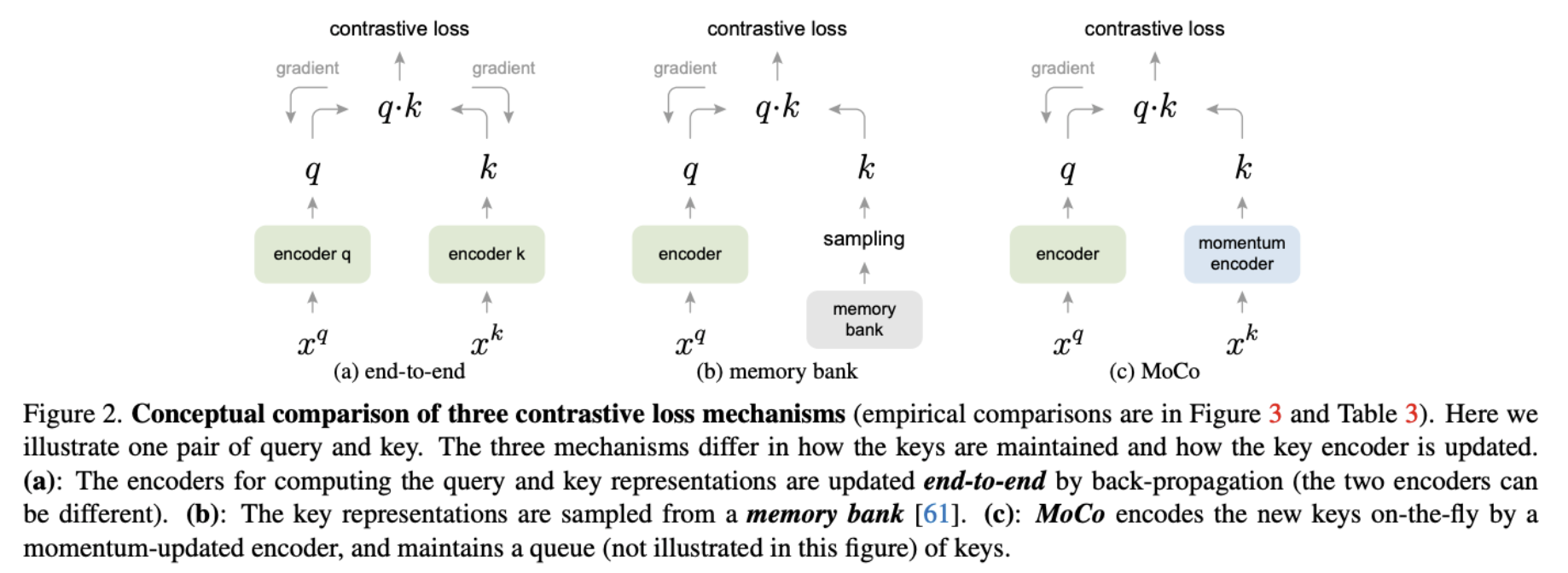
- MoCo (Momentum Contrast for Unsupervised Visual Representation Learning): In SimCLR, to get lots of negatives you need a huge batch ( TPU pods). MoCo sidesteps this by decoupling negative count from batch size(key difference to SimCLR) by keeping a momentum-updated key encoder (EMA of the query encoder, no gradients), and a queue of past keys as negative dictionary ⇒ instead of . Only the query encoder gets backprop; the key encoder is updated via
- Queue mechanics: Maintain a dictionary of size (e.g. 65536). Each iteration:
- Encode curent minibatch’s key view with the momentum encoder enqueue.
- Dequeue the oldest minibatch’s keys
- The queue acts as a large, slowly-evolving dictionary of negatives. No gradients flow into it.
- Momentum update:
- Let be the query-encoder params, key-encoder params: changes slowly — essential for queue consistency, because the keys in the queue were encoded by slightly older and a fast-moving key encoder would make them stale.
- MoCo v2 — hybrid with SimCLR: pulls SimCLR’s two best ideas into MoCo’s framework
- Non-linear MLP projection head (SimCLR’s ).
- Strong data augmentation (+Gaussian blur).
- MoCo v3: adapts MoCo to ViT backbones, studies training stability.
- Queue mechanics: Maintain a dictionary of size (e.g. 65536). Each iteration:
MoCo vs SimCLR
| SimCLR | MoCo | |
|---|---|---|
| Source of negatives | other samples in current minibatch | FIFO queue of keys from many past minibatches |
| Key encoder | shared with query encoder | momentum encoder (no gradients) |
| Gradient flows | through both views | only through the query |
| Practical | needs batch 8192 on TPU | works at batch 256 on 8 V100s |
MoCo Pseudocode
for x in loader:
x_q, x_k = aug(x), aug(x)
q = f_q.forward(x_q) # N x C
k = f_k.forward(x_k).detach() # N x C, no grad through key
l_pos = bmm(q.view(N,1,C), k.view(N,C,1)) # N x 1
l_neg = mm(q.view(N,C), queue.view(C,K)) # N x K
logits = cat([l_pos, l_neg], dim=1) # N x (1+K)
labels = zeros(N) # positive is at index 0
loss = CrossEntropyLoss(logits / tau, labels) # InfoNCE
loss.backward()
update(f_q.params)
f_k.params = m * f_k.params + (1 - m) * f_q.params # momentum update
enqueue(queue, k); dequeue(queue)
Pretext task 3: Self distilation — DINO
- DINO: no negatives at all. Student and teacher share architecture. teacher = EMA of the student. Both produce a softmax distribution over prototype dimensions on different crops of the same image; student is trained to match the teacher’s distribution (cross-entropy), gradient only flows through the student.
- here just complete with equations explanations and size of variables for pseudocode.

Pretext task 4: Low-level targets — MAE, BEiT, I-JEPA
TL;DR: Split image into patches, mask most of them, encode the visible ones, try to recover what’s missing.
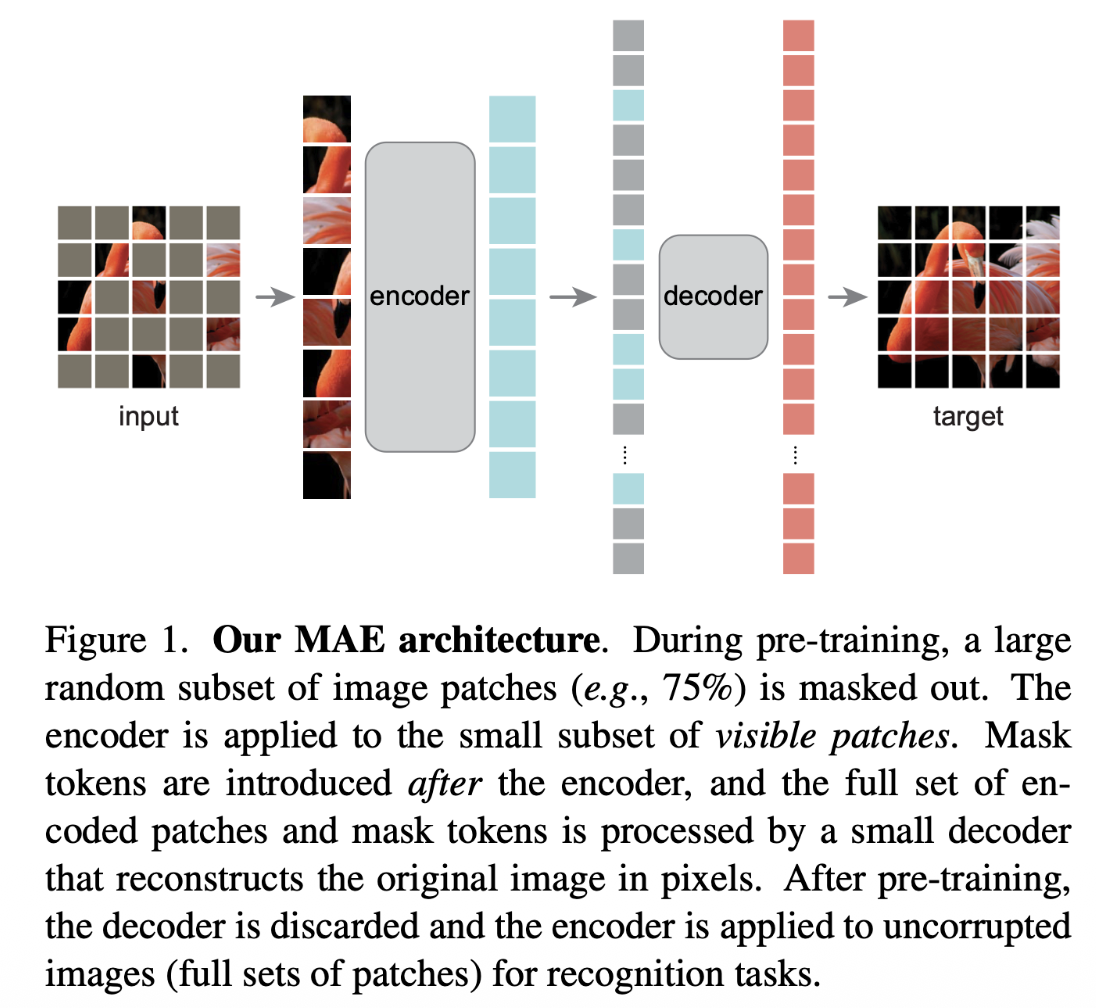
- MAE (Masked Autoencoders): reconstruct raw pixels of masked patches, L2 loss .
- asymmetric encoder-decoder architecture.
- encoder operates only on the visible subset of patches
- lightweight decoder that reconstructs the original image from the latent representation and mask tokens. Decoder is much lighter than encoder. After pre-training, throw the decoder away.
- masking a high proportion of the input image (e.g. 75%) yields a meaningful self-supervisory task.
- i.e. split image into patches select a random set of patches Linear Project:
- results are quite blurry, because it sort of learns the mean.
- asymmetric encoder-decoder architecture.
How can masked autoencoding work so well without diffusion? -- Steven
MAEs don’t need to generate an image pixel-by-pixel from pure noise (like diffusion).
They start with a partially observed image: a small set of visible patches already gives a huge amount of structure (object shapes, colors, layout).
The model’s job is to fill in the missing patches so the whole image is coherent — this is a much lower-entropy task than unconditional generation.
- BEiT (BERT Pre-Training of Image Transformers): reconstruct a discretized visual token (codebook index) instead of raw pixels.
- I-JEPA (Image-based Joint-Embedding Predictive Architecture): don’t reconstruct pixels/tokens at all — predict the embedding of the masked patches, produced by an EMA target encoder, using a separate predictor network.
- pixel-level reconstruction wastes capacity on irrelevant low-level detail; predicting in latent space is more efficient. This is the bridge between “low-level targets” and “self-distillation” (it borrows the EMA-teacher trick from DINO but applies it to masked prediction). JEPA never tries to reconstruct pixels, nor to model the full joint distribution of natural images. It only tries to predict representations of masked parts of the same image.
- context encoder encodes context latents
- EMA update:
- ”we leverage an asymmetric architecture between the x- and y-encoders to avoid representation collapse.”


- — predicted latents for target
- — targets . because targets should be fixed, so do not compute gradients.
- — sum over all targets and predictions, is target blocks.
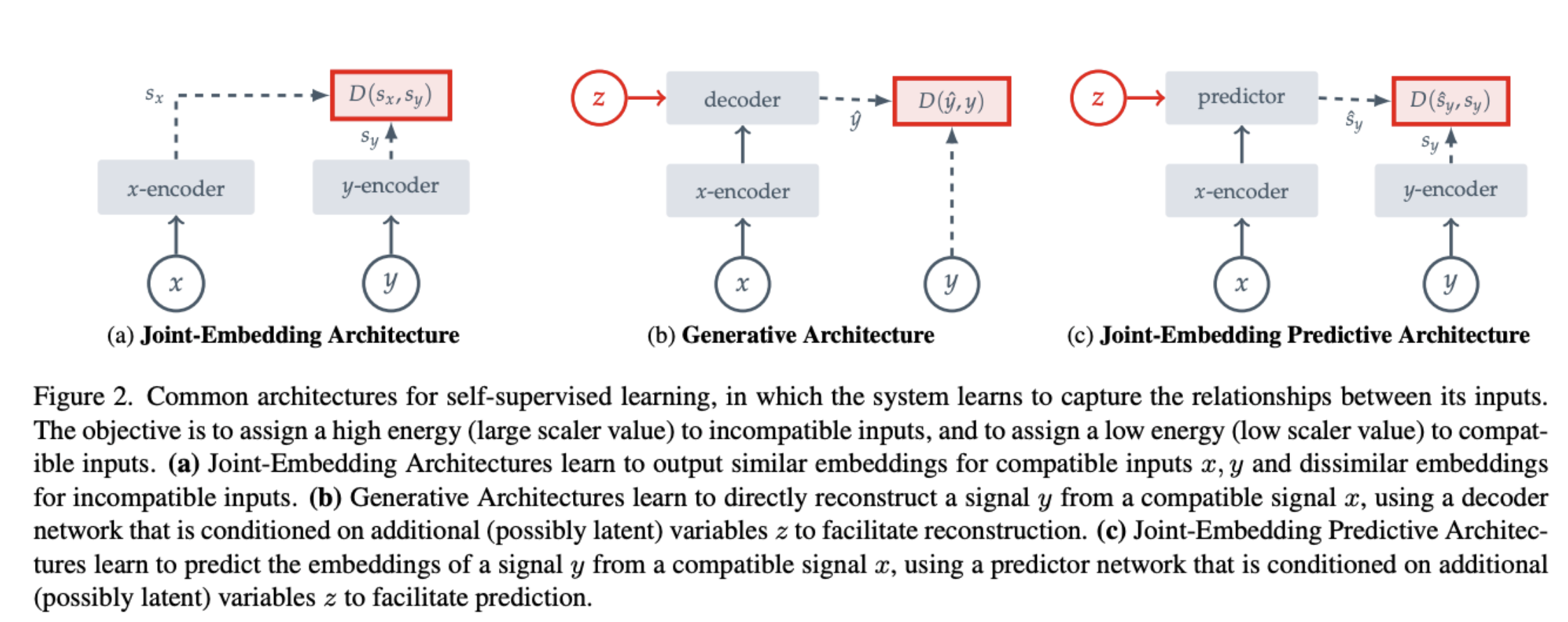
Each architecture
Joint-embedding architecture
- A big limitation is representation collapse.
- Collapse-prevention based on architectural constraints leverage specific network design choices to avoid collapse, for example, by stopping the gradient flow in one of the joint-embedding branches, using a momentum encoder in one of the joint-embedding branches, or using an asymmetric prediction head
Generative architecture
is a copy of , but with some of the patches masked. corresponds to a set of mask and position tokens to specify to the decoder which image to reconstruct. Representation learning is not an issue
JEPA
In contrast to Joint-embedding architectures, JEPAs do not seek representations invariant to a set of hand-crafted data augmentations, but instead seek representations that are predictive of each other when conditioned on additional information .
- still suffer from representation collapse