Basically downstreaming the FoMo on a specific task. Nicola offered this lecture.
PEFT library so I don’t have to reinvent the wheel
Alignment Gap
Modality alignment: the two encoders from CLIP (one for text, one for images). such that the corresponding samples are close in the embedding space .
The problem with alignment gap: the pre-training phase covered in Self-Supervision Objectives for FoMo Pre-training is general, and not focused on a specific task. So the objectives (loss functions) are also very general.
- i.e. alignment gap is the mismatch between the training objective and user objective.
Fine-tuning / Adaption
The traditional fine-tuning is based on distribution shift i.e. test/evaluate on “Dataset for task X”. It involves a generalization gap.
Generalization Gap
performance difference between a model’s high accuracy on training data and its lower accuracy on unseen, out of distribution (OOD) data.
Applying fine-tuning on FoMo means tuning models that are already extremely large (billions and trillions of params) so there’s significant hardware requirements for computation (GPUs, Gradient maps). Switching between tasks requires unloading and loading the model in memory (switch latency).
- e.g. fine-tuning ChatGPT3.5 requires to set 175B parameters.
So we make use of PEFT — Parameter-Efficient Fine-Tuning
The idea is to freeze the weights of the large FoMos, and insert smaller trainable networks in between its layers. These are also called adapters. Also covered in Improving the Generalization of ViTs for Action Understanding with VLM Pre-Training.
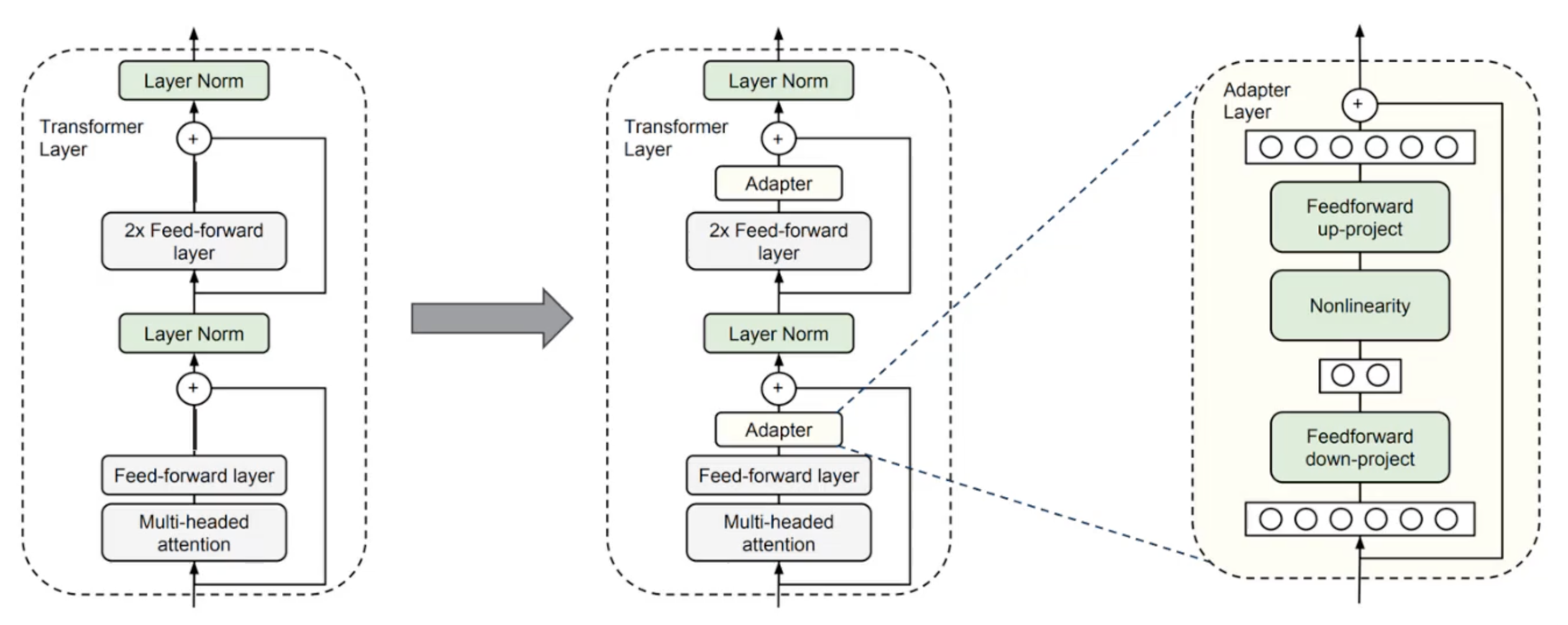
However, you do increase the number of computations the model has to compute to give you the output i.e. an added latency to the process.
LoRA: Low-Rank Adaptation
Large models are over-parametrized and their fine-tuned versions (on tasks) have a low intrinsic dimension. Basically the number of dimensions we need to solve that task is much lower than the no. of dimensions used to pre-train that model. So we don’t need to adapt all the dimensions or all the parameters, but we can do an update of the weights that also have a low rank.
Low-Rank Decomposition: Instead of updating all parameters of a pre-trained model, LoRA introduces a small set of trainable low-rank matrices that adapt the weights of specific layers.
in other words: we can learn low-rank matrices to adapt the pre-trained weights.
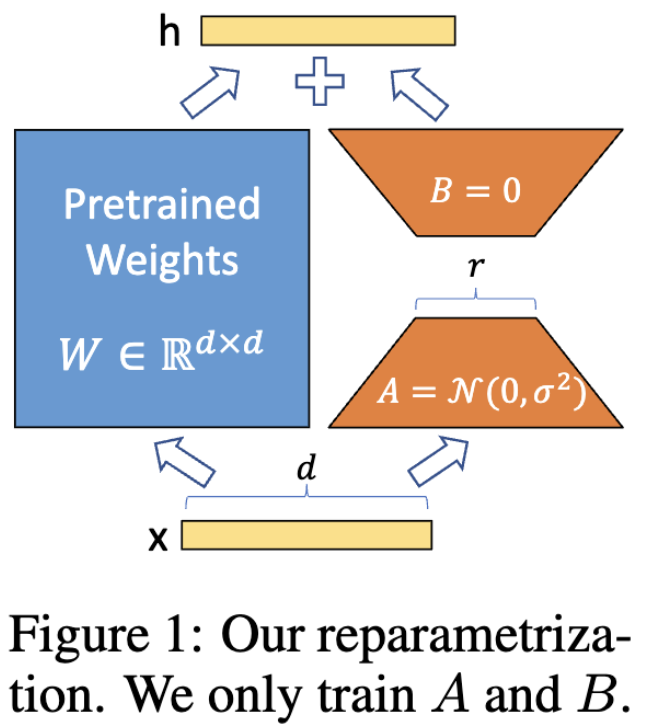
and with . and are from the original model.
During training, is frozen and we learn only and with much less parameters to learn, because of .
So the benefits of LoRA include, of course, storage saving + faster loading into memory since we only load and , it’s easy and practical since we simply compute and add it to .
Difference to Adaptors: Adapters require extra computations for the added network modules in the architecture, while LoRA does not add computations to the original model.
In-Context Learning / Chain-of-Thoughts
i.e. a paradigm to allow LLMs to learn tasks given only a few examples in the form of demonstration.
isn’t this just few-shot learning?
It’s bascially prompting the LLM by first providing some examples (conditioned on the demonstrations).
- no weight updates
- results are highly dependent on the format of the prompt
- good only for rapid prototyping
Including ICL in pre-training increases the model’s reasoning abilities by quite a lot apparently.
There’s also Visual ICL, where they basically do inpainting (asking a model to fill missing parts of an image). or ask it to do a segmentation map, colorizations, edge detection, etc etc.
Chain-of-Thoughts
is a technique meant to improve a model’s performance by generating intermediate reasoning steps (not only final answer examples).
it merges at scale: it enables models to overcome (supervised) SoTA results in solving many tasks.
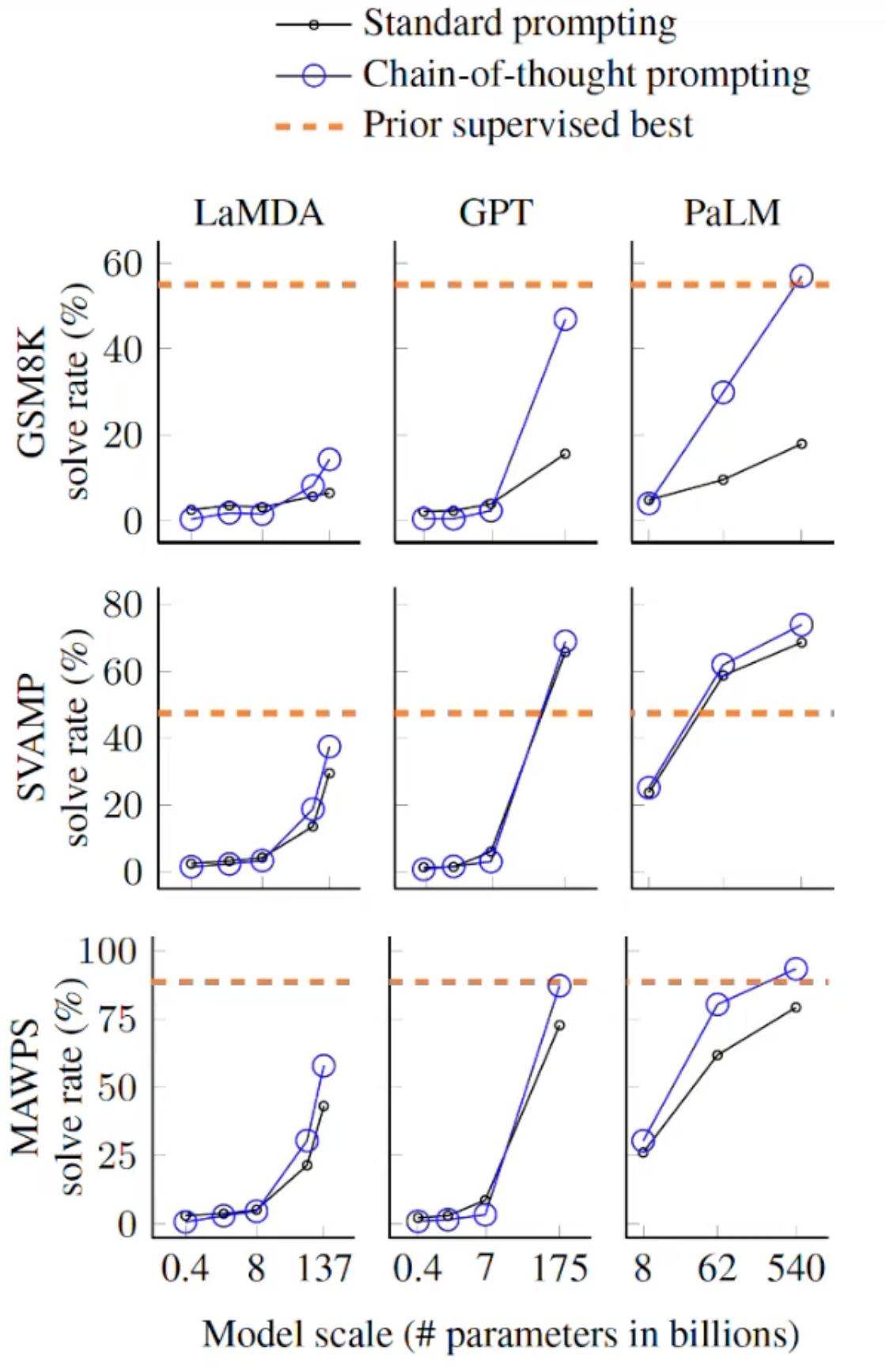
ICL vs CoT:
- in ICL, answers are provided in the prompts, counting on the model to learn the expected behavior.
- in CoT, we explicitly induce reasoning steps within the prompts to induce the model to learn-replicate the intended reasoning.
Visual CoT improves performance by enabling the models to perform deeper visual reasoning (explain the multimodal answers).
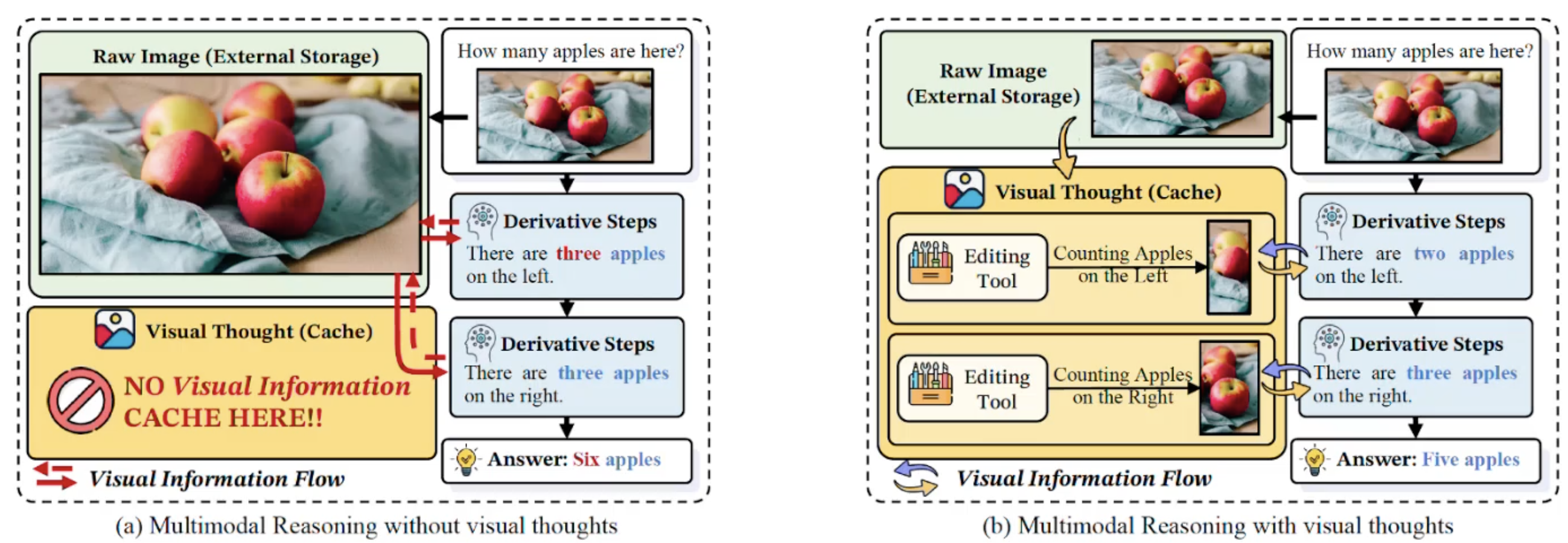
- Through visual thoughts, the model comes to the conclusion that there are 5 apples in the image.
Prompt Learning
Crafting specific inputs to guide the models to align with the human intent (solving a task).
golden rule: the better the input prompt, the better the results.
Prompt Learning
idea: model prompt context words with learnable vectors (all other params are frozen). instead of prompting static text, we prompt learnable vectors.
- we do it by maxmizing the score of the ground-truth class. So we need some data to do the learning.
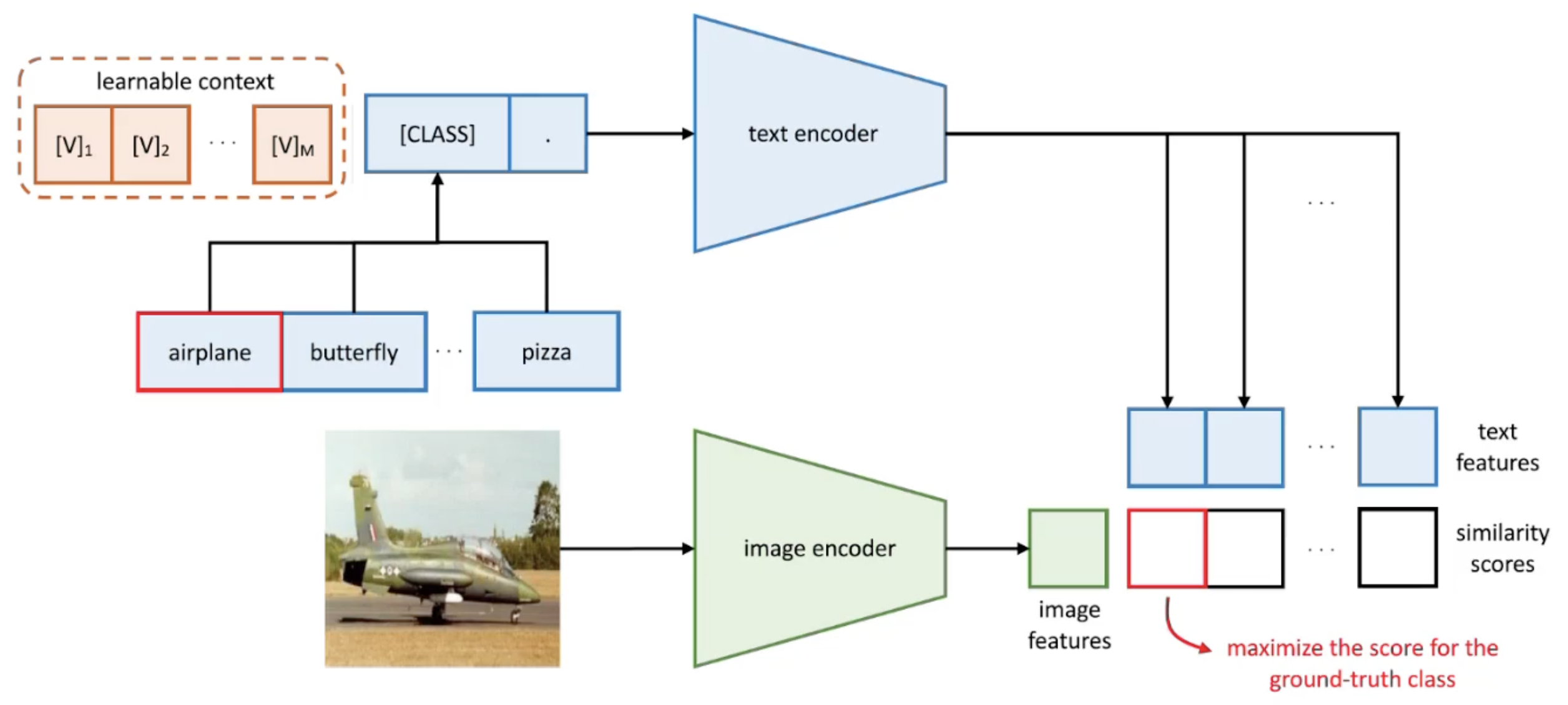
two ways of learning — Context Optimization
- Unified context — learn global context vectors, usable for and shared by all classes
- Class-specific context — context vectors are learned specifically for each class
Learning the prompts yields MUCH better results.
Limitations
- CoOP is NOT effective for fine-grained classification
- prompts are not interpretable — maybe develop on this idea
- low generalization on unseen classes
- this is where Conditional Prompt Learning (CoCoOP) comes in. Prompts are conditioned to each input, and adaptable to new inputs (w/ a lightweight NN). It results in more generalizable prompts and better results on unseen classes.
Instruction Tuning
aims at enhancing capabilities and controllability of FoMos, by further training them using
[INSTRUCTION, OUTPUT]pairs.
basically fine-tune on maany tasks and do inference on unseen task types.
- shows rapid adaptation and computational efficiency
- crafting high-quality
[INSTRUCTION, OUTPUT]pairs is difficult and costly - it’s possible to result in focusing on surface relations (shortcut learning)
FLaN: Finetuned Language Net
it shows that tuning a 137B parameters pre-trained language model on
[INSTRUCTION, OUTPUT]pairs improves the performance on unseen tasks (zero-shot).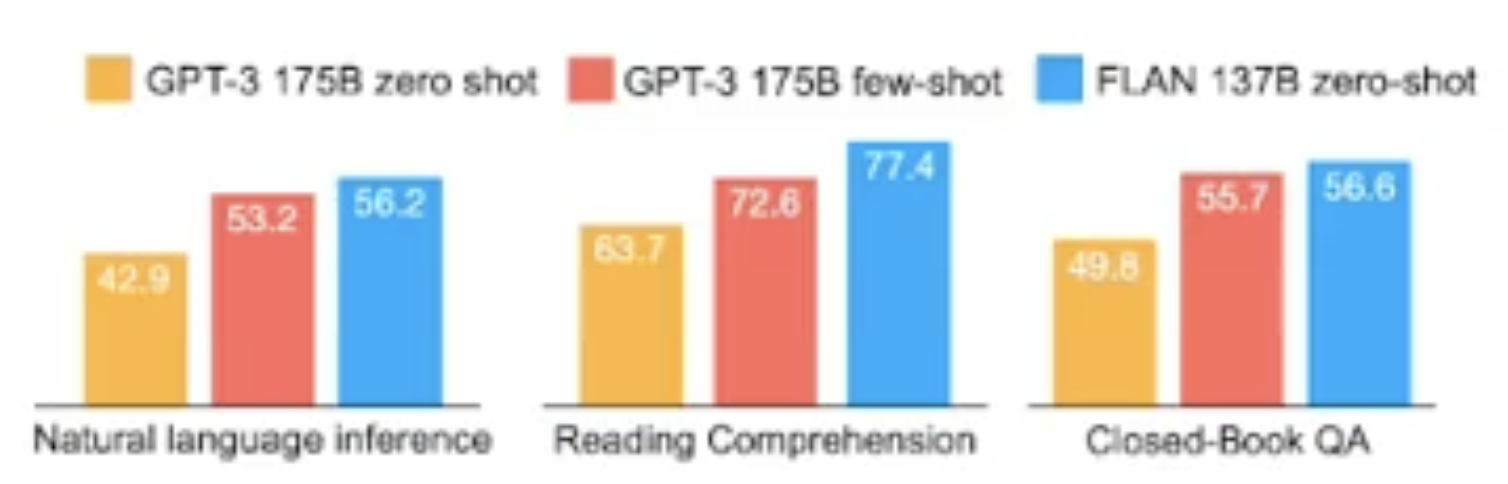
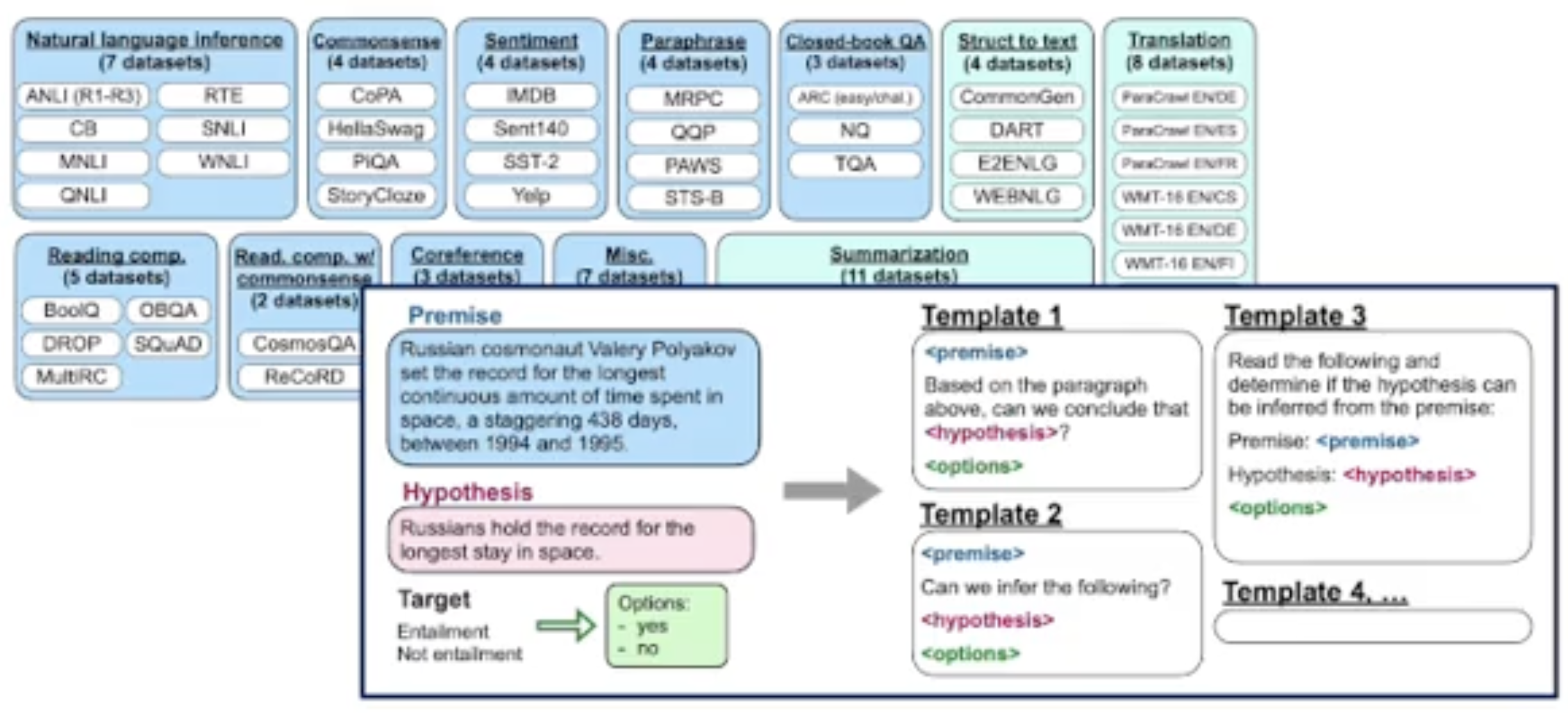
- the innovation stands in the dataset, not in the model itself. The authors combined and curated 62 datasets (different tasks) with instruction templates.
- they did it by extracting the premises and hypotheses and creating multiple templates based on them.
Instruction tuning was also extended to visual — LLaVa. They extended a Language Model (Vicuna) with the Visual Encoder from CLIP and project its features onto the word embedding space, matching their dimensionality through a trainable linear layer.
- LLaVa does multimodal instruction tuning, and builds new large multimodal models (LMM).
How is Visual Instruction Tuning (VIT) different to Visual Prompt Tuning (VPT)?
VIT improves the model’s instruction following abilities, while VPT improves the parameter-efficiency in model adaption.


- looks more like making the model explain what’s wrong in a certain image or asking it to reason what kind of object it sees inside a bounding box.
RLHF (Reinforcement Learning Human Feedback)
Train AI systems to align with human goals, fine-tuning FoMos using reward signals based on human preference.
AI Alignment
process of encoding human values and goals into AI models to make them as helpful, safe and reliable as possible.
Some questions we need to ask: how do I make sure my model is inclusive, not racist?, per example. And basically it’s through including the human feedback in the loop.
Of course, the idea is to train a policy (Agent) that takes actions, given the state of an environment, to maximize a reward.
- The policy is learned and it maps the states to a probability distribution over actions.
- usually learned through PPO (Proximal Policy Optimization)
- policy is randomly initialized
- We seek to train a reward model directly from human feedback
- switch from reward function to reward model of human preferences where we have more control over the results.
- no state transition: the action itself is not the generation of the next token; but the completion of a prompt.
- response-level reward: reward computed for a series of actions, namely full completion of several token generation
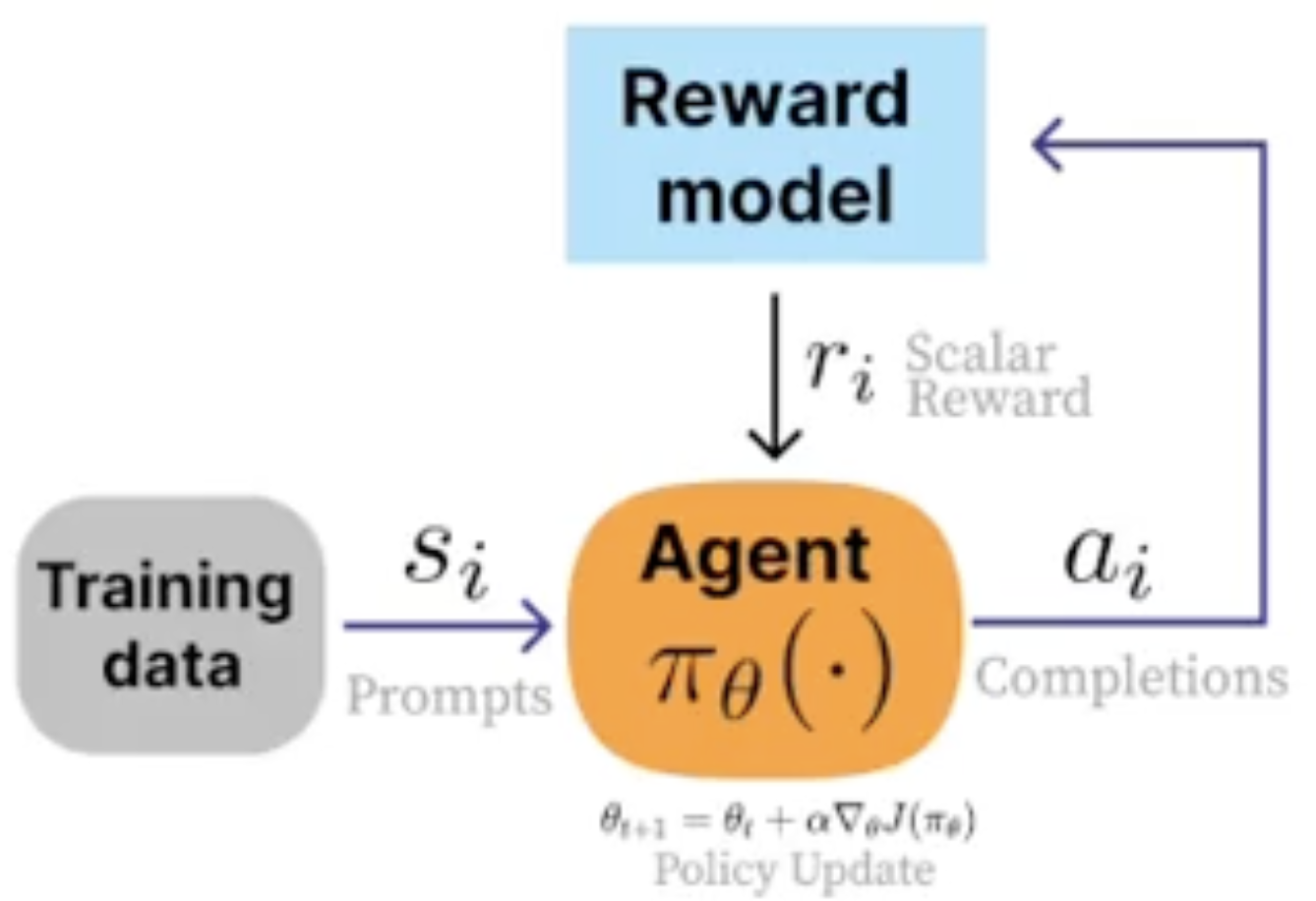
This is the architecture of InstructGPT — one of the first RLHF solutions
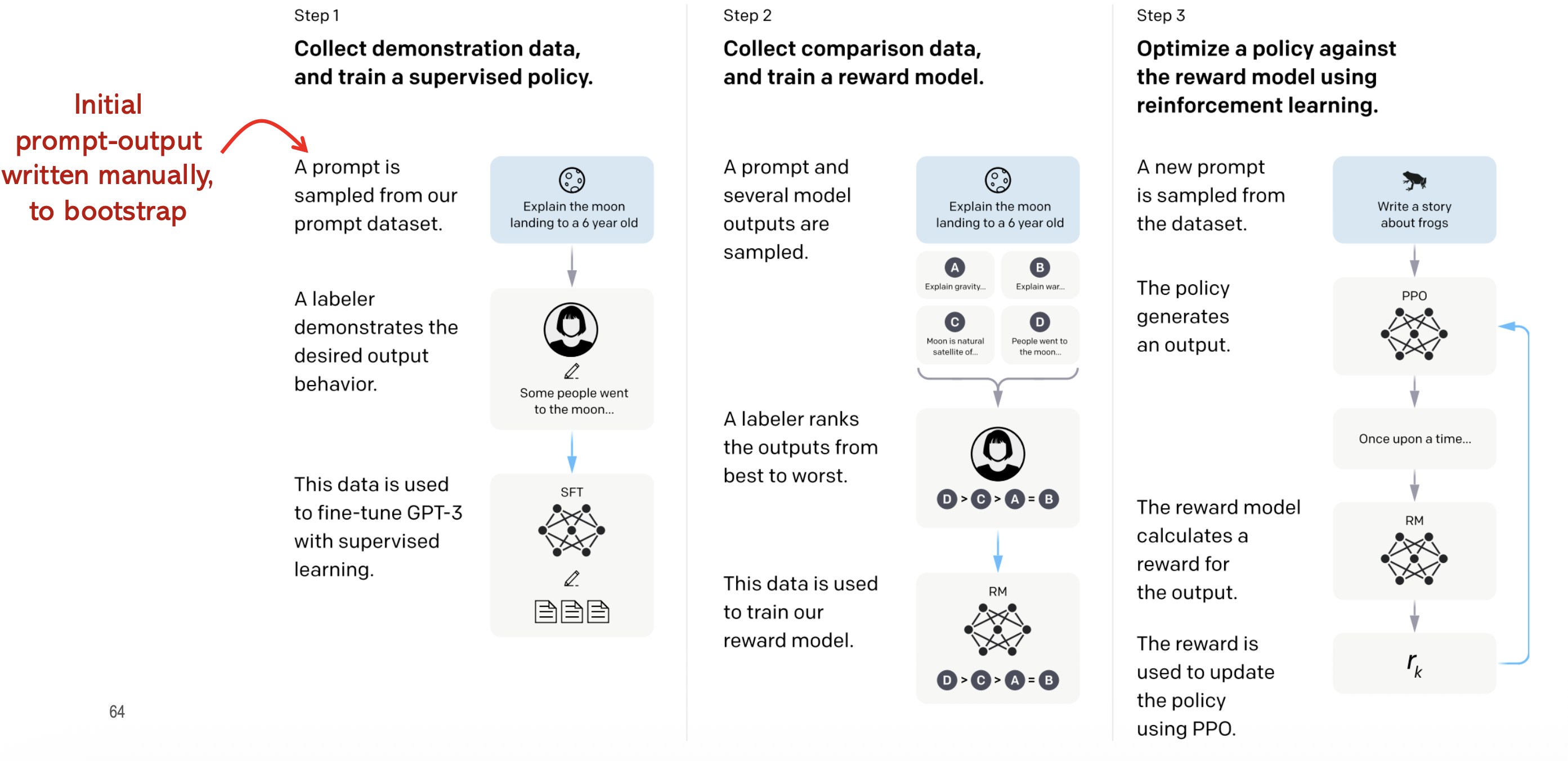
It yielded incredible results, rated by human users:
- attempts correct instruction
- follows explicit constraints
- uses appropriate language for customer assistant
- less hallucinations