Used it first in my Visual-Language Models for Object Detection and Segmentation project that I did for a startup (THEKER) and now I encountered it again in my Generative AI in Robotic Applications course at Twente.
Resource: Original paper, this blog on medium
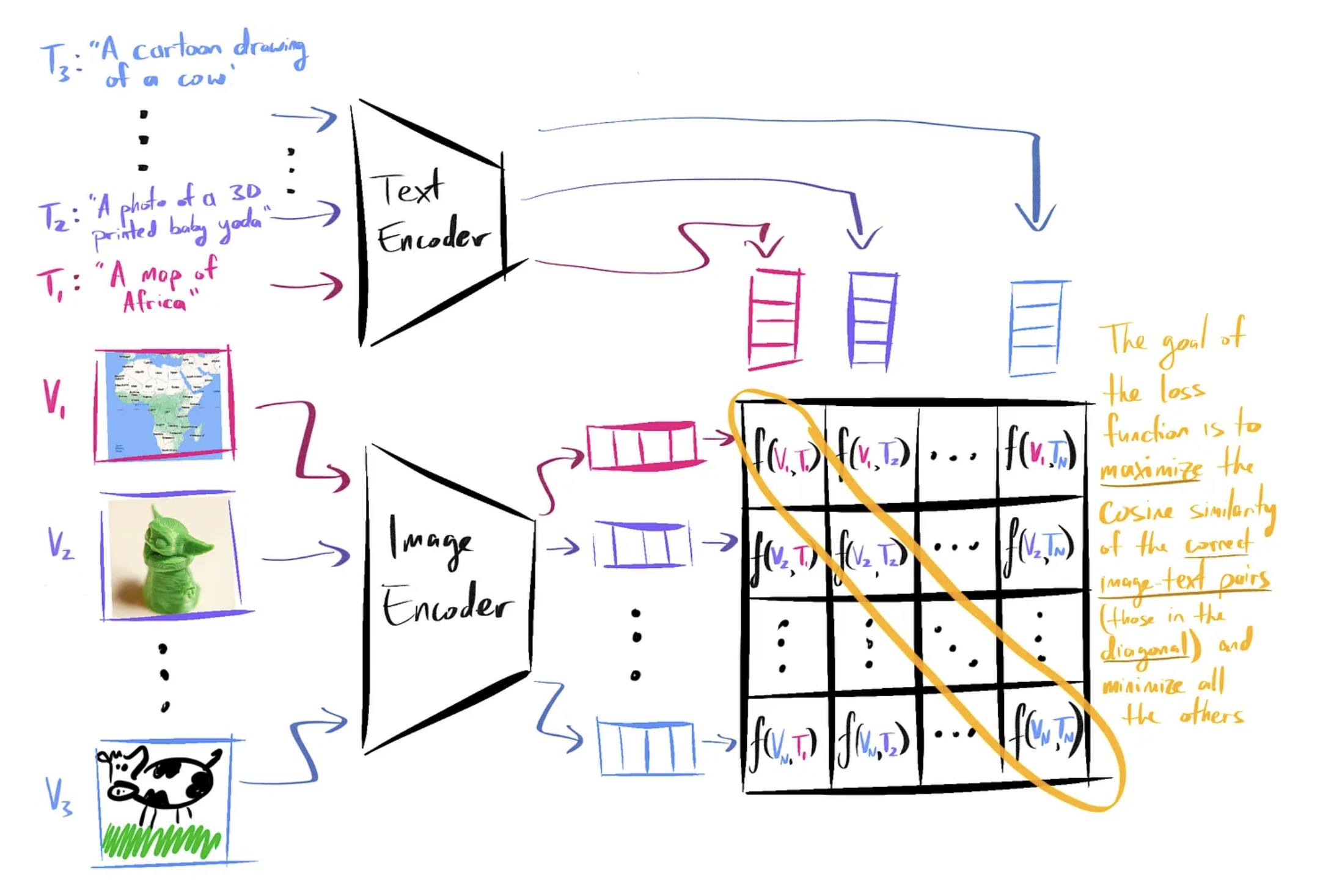
CLIP was trained on 400 million (image, text) pairs collected from the internet.
CLIP is a pretrained model for telling you how well a given image and a given text fit together.
- In training CLIP, the similarity scores of the correct image-text pairs are found on the diagonal of the similarity score matrix for the current batch.
In training, it tries to maximize the cosine similarity between correct image-caption vector pairs, and minimize the similarity scores between all incorrect pairs.
In inference, it calculates the similarity scores between the vector of a single image with a bunch of possible caption vectors, and picks the caption with the highest similarity.
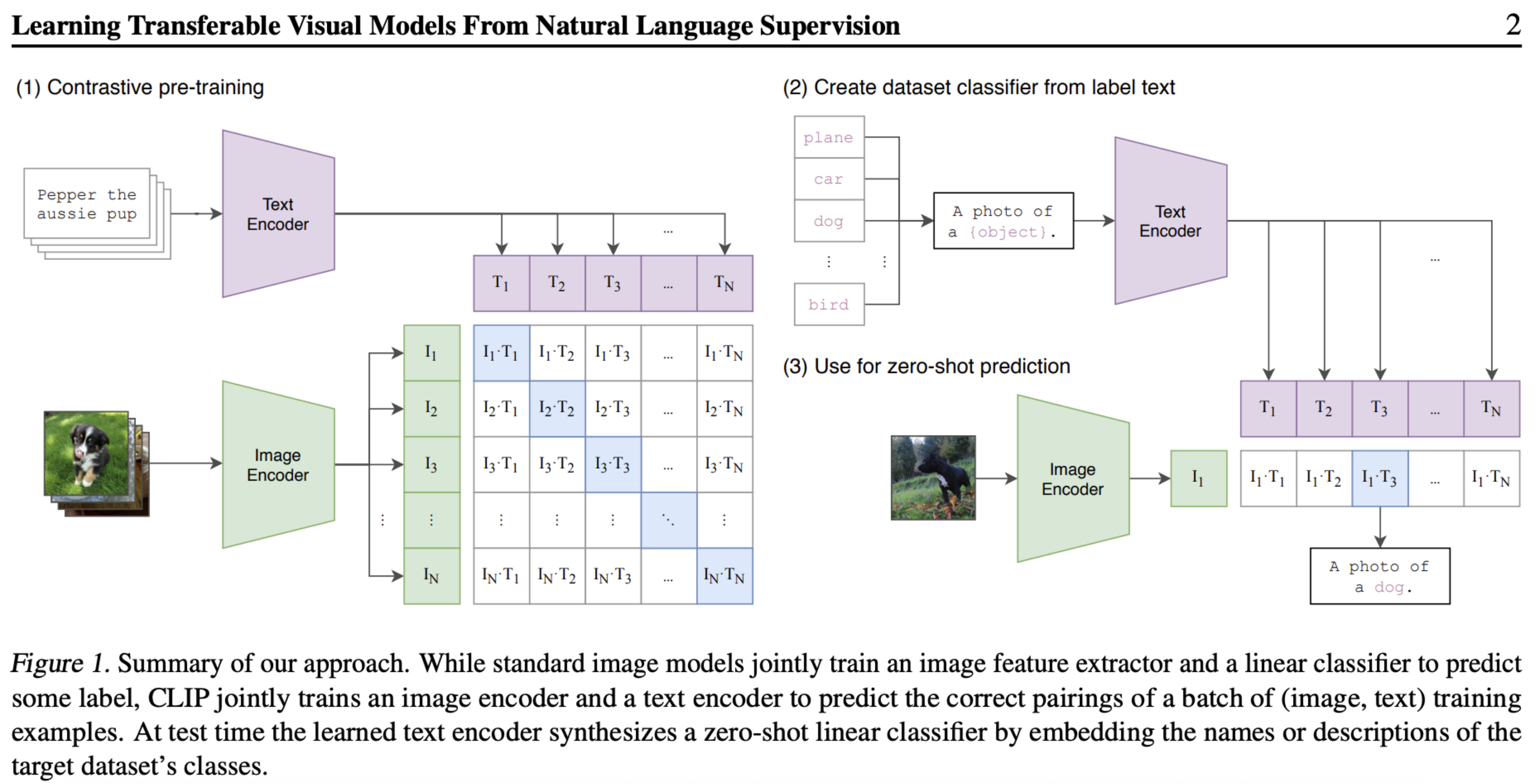
The training method mentioned above is called contrastive loss: a contrastive function that will modify the weights of the model such that correct image-caption pairs get a high similarity score, and incorrect pairs get low similarity scores. It’s extremely similar to the Skip-gram loss function from Word2Vec.