youtube video, official github repo
Used DINO in the foundation models project. since the dataset size is really limited and it is imbalanced, the idea of using foundation models is the main motivation since it can extract good general information for downstream tasks. We need to show how, with zero-shot, few-shot, and light fine-tuning, we can achieve acceptable performance on this dataset.
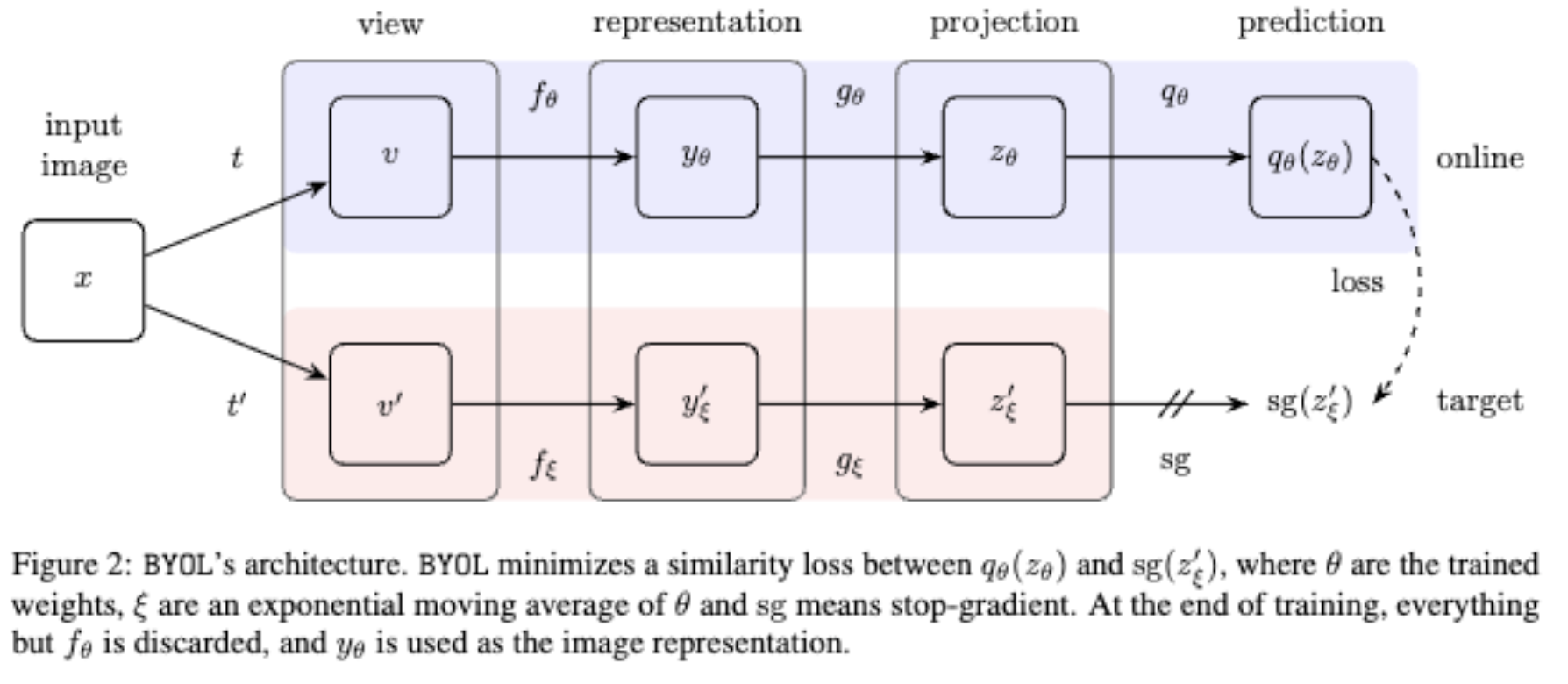
It has the exact same architecture for student-teacher as BYOL (Bootstrap your own latent)
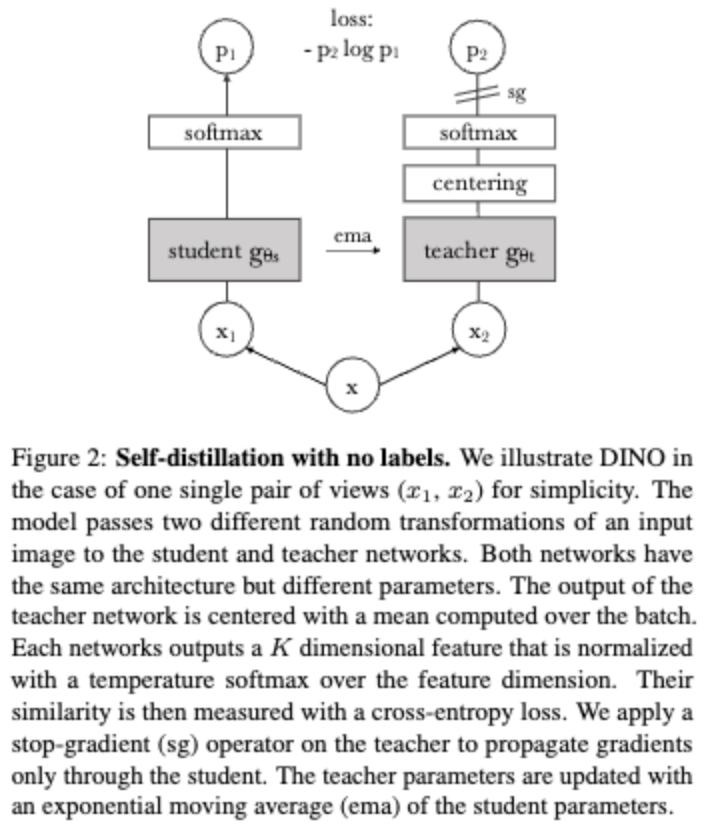
DINO = “self-DIstillation with NO labels”. No explicit negatives, no contrastive loss — a teacher-student setup where the student learns to match the teacher’s output distribution on different views of the same image.
Related to Representation Learning.
For example, SimCLR learns features using contrastive loss as in CLIP by creating a pair-wise similarity matrix of all pairs using vector dot product. The yellow boxes are positive pairs and blue ones are negative pairs. And during training, the model learns to increase the similarity for positive pairs.
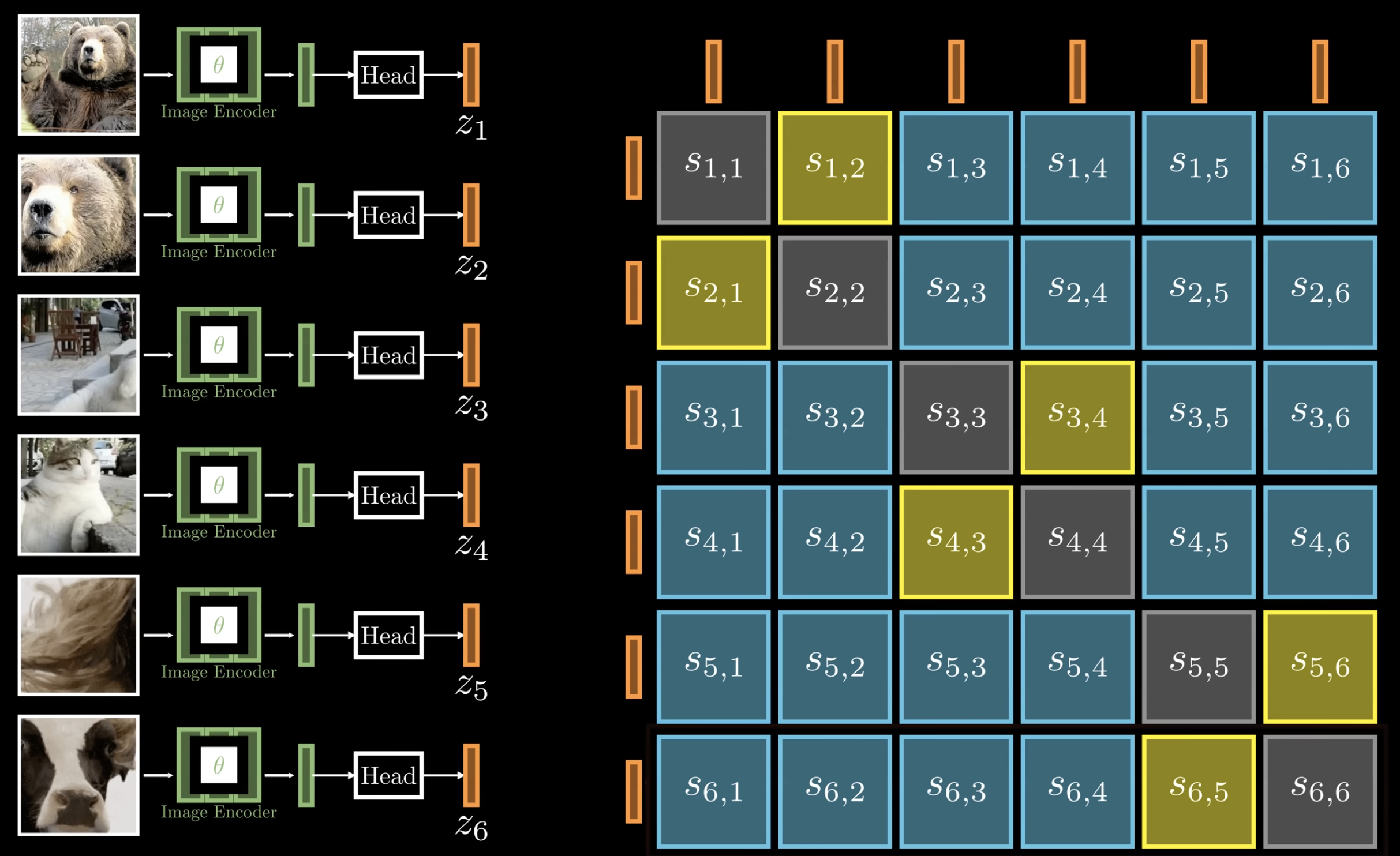
However, to avoid learning trivial representations, it need a large number of negative samples. So it’s computationally expensive, and this is where DINO shines with its self-learning approach.
The logic of DINO (v1) is to extract features, feed them into a projection head to obtain logits and then apply a softmax function to produce probability distributions (since the probabilities will sum up to 1). With this setup, we train a student model to match the teacher’s predictions by minimizing the cross-entropy between them.
Knowledge Distillation
A key details is to stop the gradient from flowing into the teacher network during training so only the student is learning (
detach()in PyTorch).i.e. distill knowledge from a powerful large teacher model to a smaller student model, making inference more efficient.
- Student and teacher — same architecture (ViT), different parameters.
- Teacher is an EMA of the student i.e. no backprop into the teacher (stop-grad on the teacher branch) —
- Both produce a K-dimensional output that gets softmaxed into a probability distribution over K “prototypes” (no classes — the K dimensions are just a learned codebook).
Why does it not collapse?
The student can collapse to outputting a constant (matching a constant teacher trivially). DINO prevents this with two tricks on the teacher:
- Centering. Subtract a running mean from teacher logits which prevents any single dimension from dominating:
- Sharpening. Use a low teacher temperature which makes the teacher’s output peaked ⇒ pushes the student toward sharper, non-uniform distributions.
Centering alone uniform collapse. Sharpening alone one-dim collapse. Together they balance.
Final result: Unsupervised segmentation
The headline result: the [CLS] token’s self-attention on the last layer of a DINO-trained ViT produces clean object segmentation masks — without any segmentation supervision. ViT patches trained with DINO attend exactly to the object in the scene. Supervised ViTs don’t do this.
DINO v2
- expanded output dimensions to 128k from 64k
- better centering (Sinkhorn-Knopp), KoLeo regularizer
- bigger model, bigger curated dataset
- additional property: better understanding since, before feeding the image, they first split it into smaller patches with a respective
[CLS]token which summarizes the whole image. It helps the student model to learn fine-grained patch-level features.
DINO v3
- scaled up the model size, data, and compute
- additional property: improved quality of dense visual features (spatial structures become much cleaner and more defined i.e. you can see how it highlights only what’s similar to the object under the red dot).
- Gram anchoring: enforces the cosine similarity between all pairs of patch token embeddings of the student model to match that of the teacher model.

