Lecture 2 from my GenAI Models and Robotic Applications course. Nice explanatory video. Video to explain what ELBO is — also explains the KL Divergence term.
Encoder
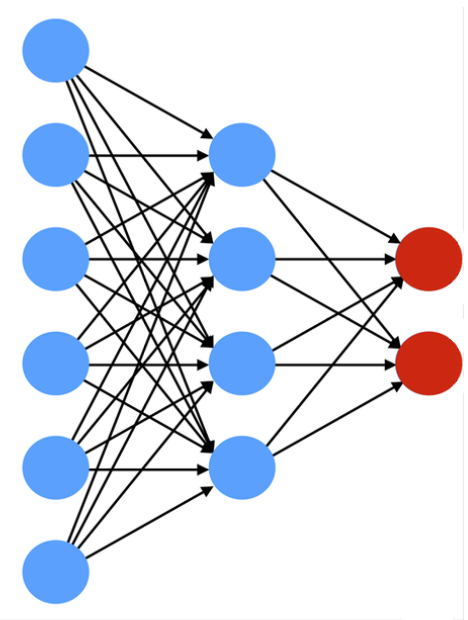
- From high dimensions to low dimensions
- A function that encodes an input sample into a lower-dimensional code
- Fully-connected
- Convolutional
- Sparse
Decoder
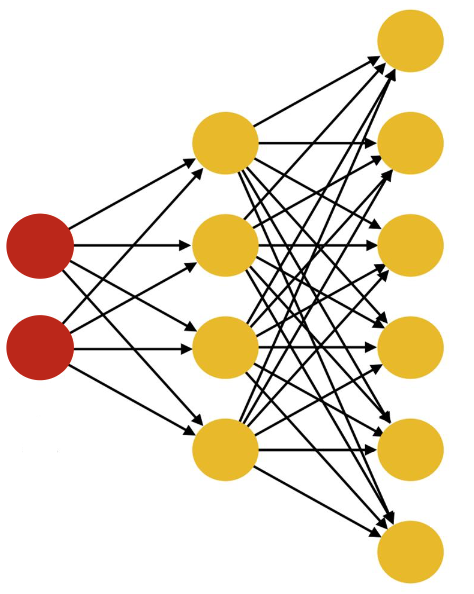
- From low dimensional space to higher dimensional space
- A function that encodes an input sample into a higher-dimensional code
- Fully-connected
- Convolutional
- Sparse
- Convolutional decoders perform transposed convolutions or upsampling and convolutions to reverse the downsampling of the decoder.
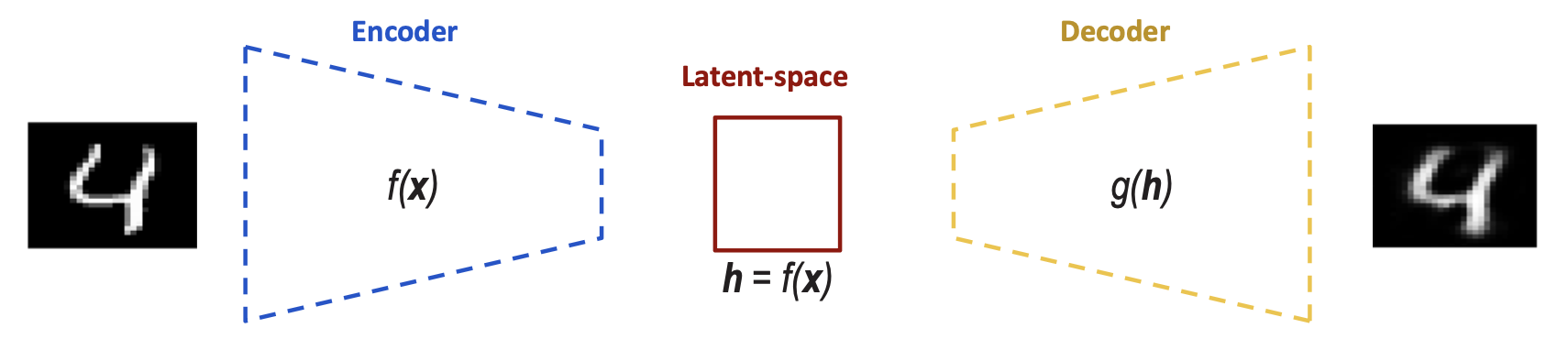
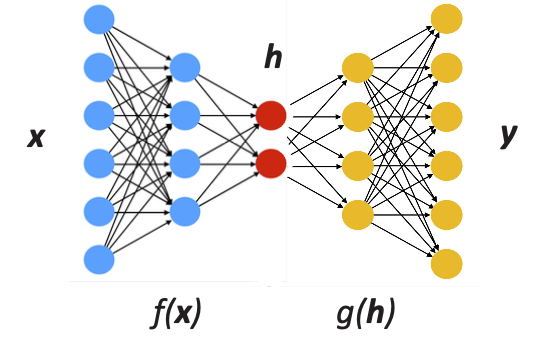
Autoencoder (AE)
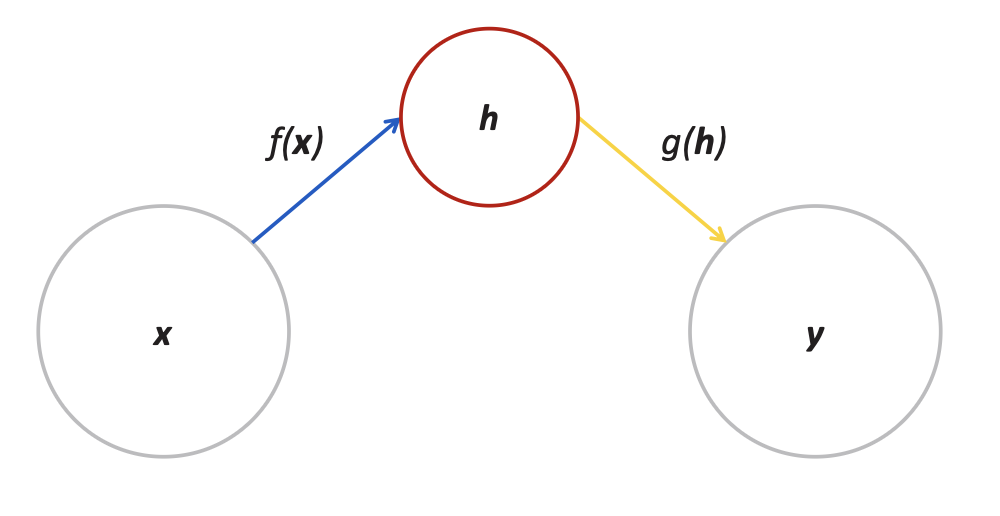
- f(x) is the encoding function
- g(h) is the decoding function
- h is the latent space. Here we can use it to learn more about the information (extraction and probably compression or even manipulating this data e.g. features for classification)
- the learning process is described as minimizing a loss function
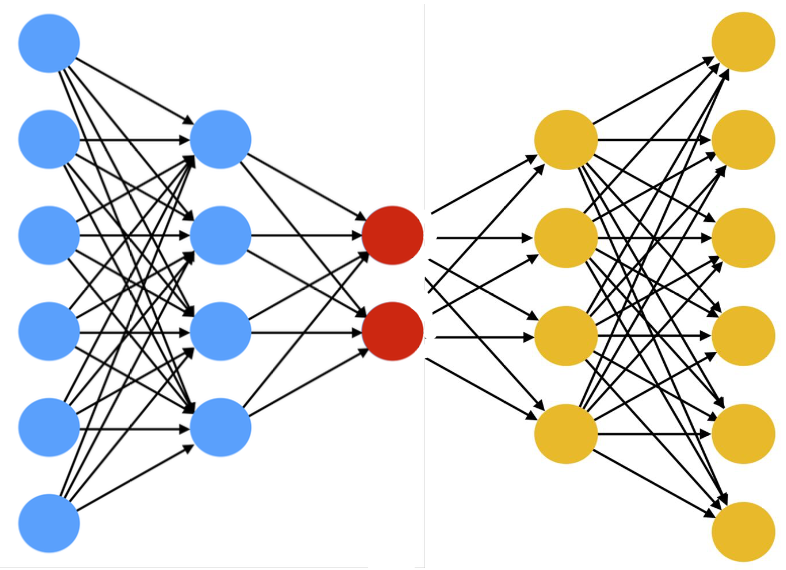
- A neural network with the task of copying the input to the output (difference between x and g(f(h)) is 0)
- Trained to minimize the dissimilarity between the original input sample(s) and the reconstructed output
- Convolutional decoders perform transposed convolutions or upsampling and convolutions to reverse the downsampling of the decoder.
it’s a way to learn features in an unsupervised way.
Visualizing the latent space of an AE
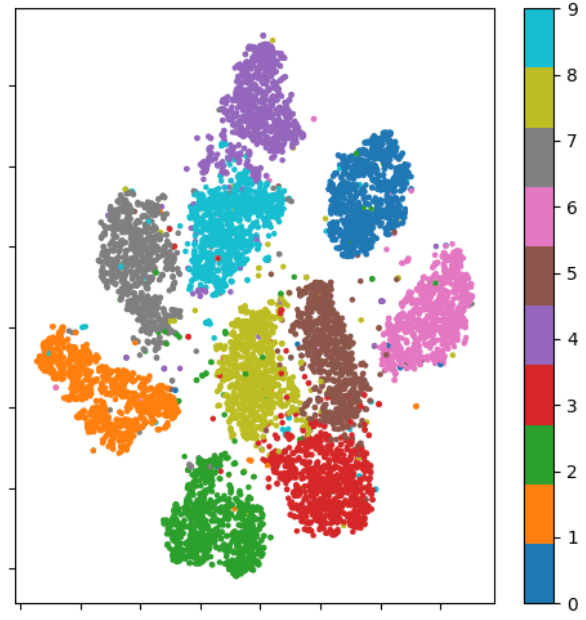
- An AE maps the input samples to points into the latent space, building large mutually independent clusters (no relations between the 'neighbor' clusters)
- The mapping is optimized to reconstruct the input samples only.
Problems
- When the hidden layer h has the same dimension as input x, the network can cheat by just copying the input. If the encoder/decoder are too large, they memorize training samples instead of learning meaningful patterns.
Solution: Undercomplete Autoencoders
Undercomplete AutoEncoders
- The hidden layer h is deliberately smaller than the input x (|h| << |x|). This forces the network to compress the input, learning only the most important features for the training distribution.
- Main Application: Dimensionality Reduction
- Benefits: Prevents trivial identity learning, creates useful compressed representations,
- Limitation: The learned features are optimized for the training distribution and may not generalize to diverse inputs,
- The encoder and decoder must have limited capacity. If they're too powerful (even with a 1D bottleneck), the decoder can still memorize by mapping each training example to a unique integer index, defeating the purpose of compression.
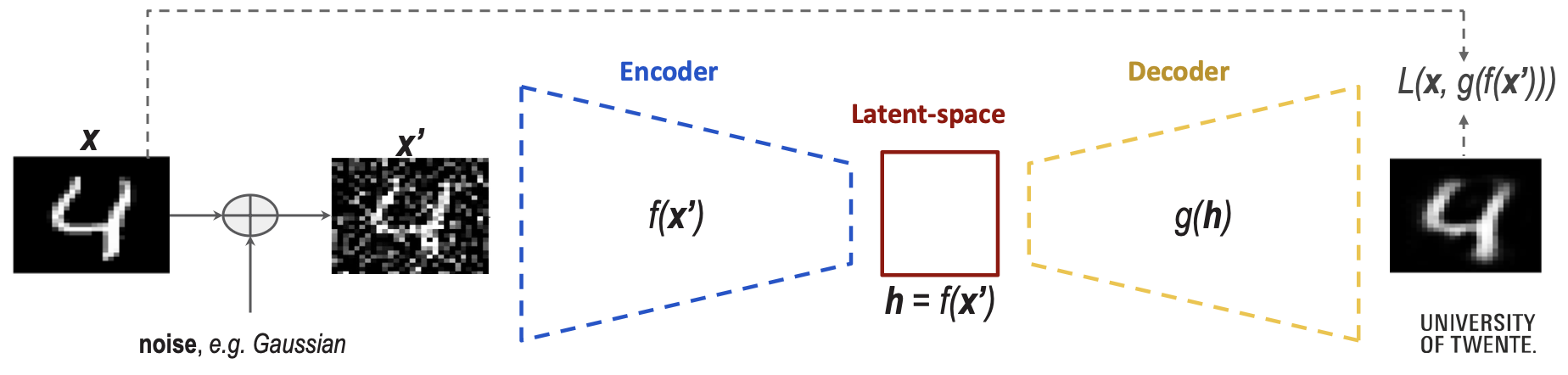
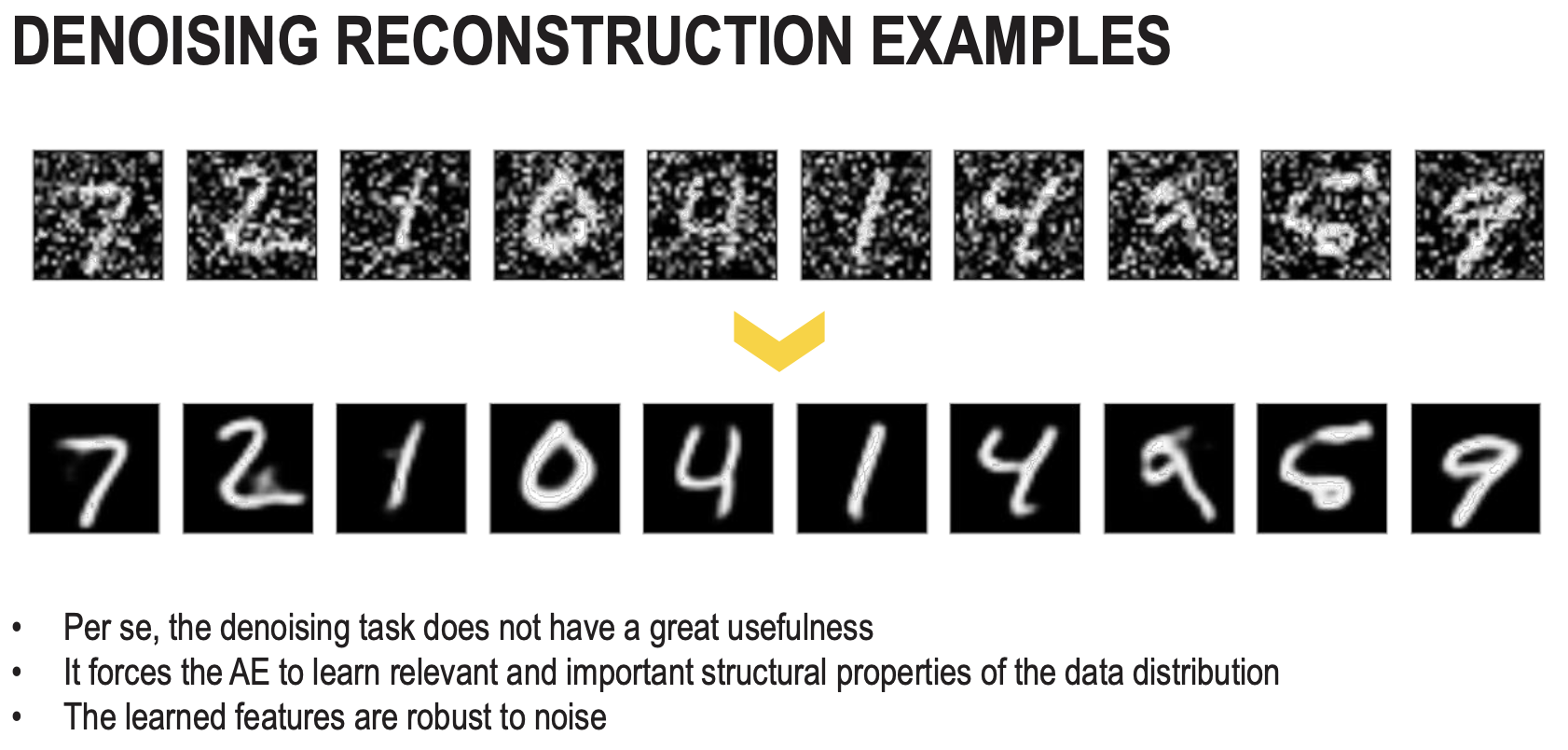
Denoising AutoEncoders (DAE)
- Trained to remove noise from the image. DAEs are trained to take a (partially) corrupted input and recover the original undistorted input.
- We take the input(x), we corrupt it with noise(x’) and it becomes the input for the encoder. Train by minimizing the MSE loss between original and reconstructed samples.
- DAE learns features that catch important structures in the input distribution of the training data.
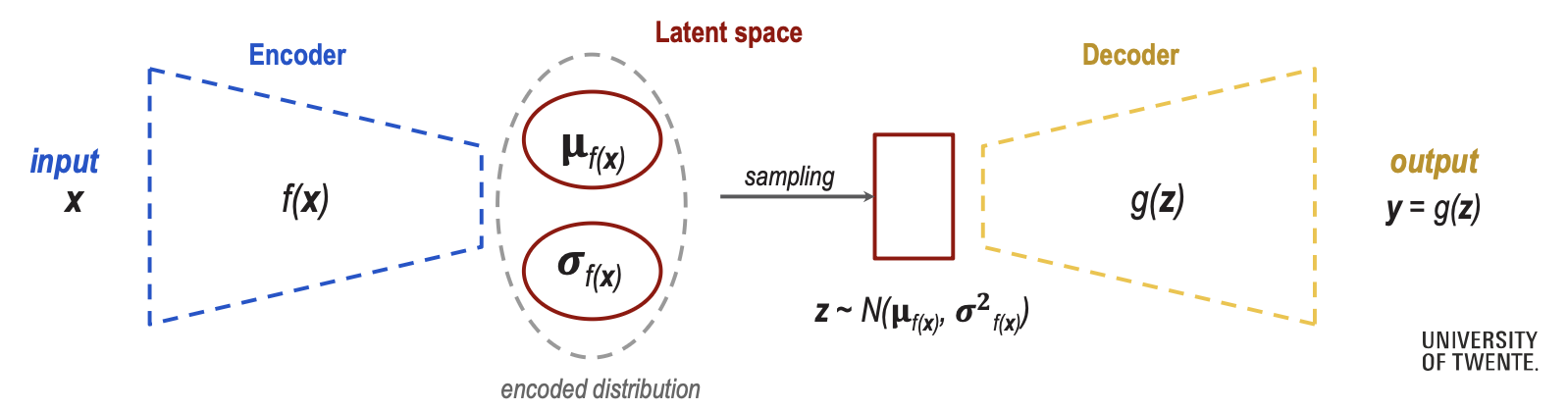
Variational AutoEncoders (VAE)
Really nice blog on this topic.
- Enforces the learning of a regularized latent space (with a probabilistic twist)
- Does not encode inputs as points, but as a distribution over the latent space.
- The latent code is sampled from the learned distribution
- The decoder reconstructs the sampled distribution points
The mean and standard deviation are now in high dimensional space (variance is the covariance matrix and the mean is also a matrix).
Process
Forward Pass (Encoding Sampling Decoding)
- Encoder: Input data , outputs parameters (mean and variance) of latent distribution :
- Reparametrization trick: Differentiably sample latent variable :
- Decoder: Reconstruct data from sampled latent vector :
Loss Function (ELBO)
- E[] is the entropy loss.
- is a measure of difference between distributions.
- Aim is to reconstruct the input accurately and enforcing a known distribution to the latent space
Sampling does not flow back (Backpropagation through randomness is not possible). That’s why we have to do a reparametrization trick: Separate the randomness from the learnable (and differentiable) parameters , where , instead of
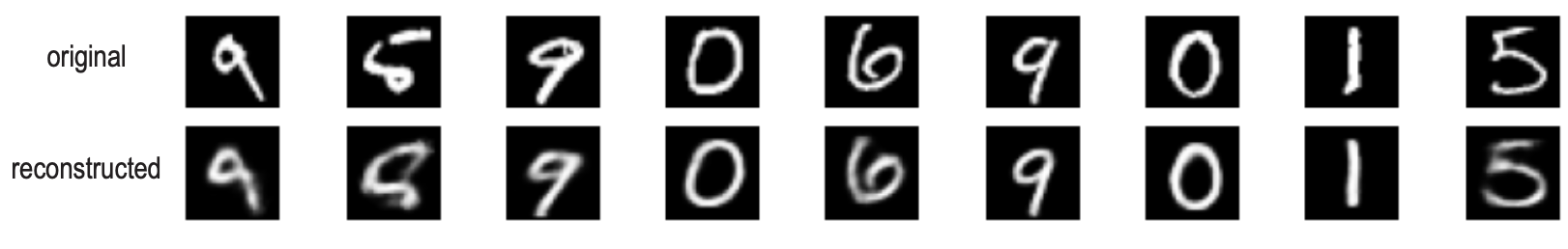
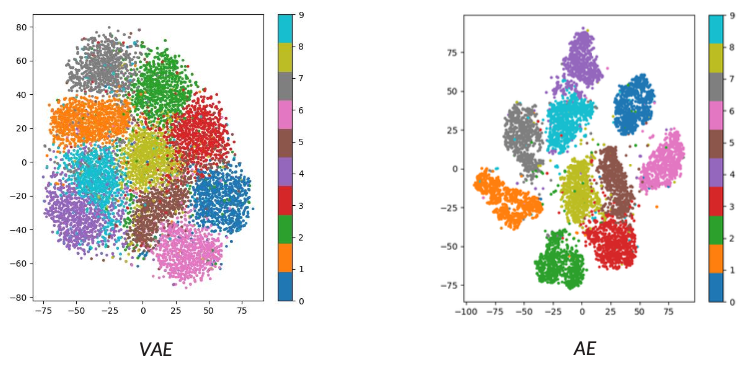
VAE vs AE: latent space
It's basically an Autoencoder but we add gaussian noise to latent variable z?
Key difference:
- Regular Autoencoder
- Input Encoder Fixed latent representation Decoder Reconstruction
- VAE
- Input Encoder Latent distribution Sample from distribution (adds Gaussian noise via reparam. trick) Decoder Reconstruction
- In the AE latent space, the clusters are not correlated in any way. It’s just a visualization.
- In the VAE latent space, the clusters are correlated through the prior. The KL divergence term pushes all encodings toward , which:
- centers all clusters around the origin
- Keeps variance controlled
- Forces the network to use the latent space efficiently
- Creates semantic relationships — similar digits tend to be closer because they share similar distributions that get pulled toward the same region of the prior. For example, digits 4 and 9 will always sit close to each other when semantic relationships matters.
Generation with VAE
- The latent space is encoded as a (Gaussian) distribution.
- Sampling a latent variable ( from ) and let the decoder generate (reconstruct) an image. VAE produces recognizable digits while AE generates blurry/unclear outputs when sampling randomly.
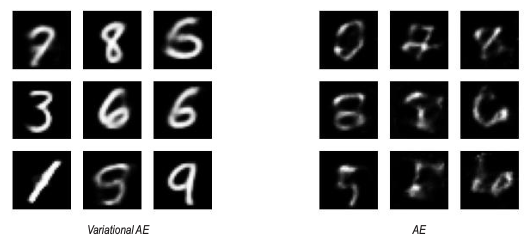
Latent Space Arithmetic
- Interpolation: Encode two samples (e.g. digit ‘2’ and ‘4’), compute and , then interpolate: where and .
- This results in smooth morphing between digits (2 4) for VAE. In the AE case, we have abrupt jumps with artifacts — the irregular latent space means intermediate points don’t decode meaningfully.
Attribute Manipulation
- Compute mean latent vectors for each attribute cluster
- Calculate attribute direction vectors in latent space
- Add/subtract these vectors to/from an encoded image
Some examples include prompts like “make blonde” or “add glasses” which add or substract the respective vector.

Generative Adversarial Networks (GANS)
Really nice introductory video about GAN Tutorial on how to train a GAN
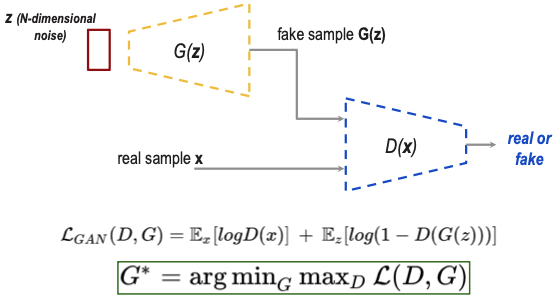
- GANs are generative models based on game theory,
- A generator network G generates fake samples,
- A discriminator network D discriminates between real samples and fake generated samples.
Adversarial Training
- The two networks compete in a game:
- G minimizes: Makes , fooling the discriminator
- D maximizes: Correctly identifying real () and fake ()
Conditional GANS (cGANS)
Conditional GANs
- Learning a generator G to reconstruct meaningful samples only from noise z can cause mode collapse(G generates few samples only, D is in a local minimum). Mode Collapse means that the training of the network is stuck.
- The solution implies conditioning: Both G and D receive an additional input c (condition) such as a class label, text description, or another image. This guides generation toward specific outputs.
The loss function stays the same but we take c into consideration.
- Generator: — takes noise and condition
- Discriminator: — evaluates if is real given condition .
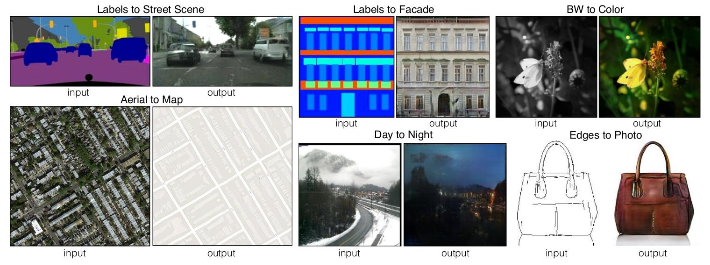
One condition for cGANs in computer vision: ALLIGNMENT (or PAIRED) (the objects are always in the same place). cGANs excel at paired image translation tasks.
Cycle GANS
- Cycle GANs perform unpaired image-to-image translation: given two unpaired image sets (domains) X and Y, learn a mapping function between the two domains that transforms images from X into images from Y (and vice versa).
- Based on the concept of cycle consistency.
- Paired training samples are difficult to obtain (and scarce).
