The mean-field particle perspective
We started with a small recap on Neural ODEs. The concept is basically an extension of the mathematics covered in Normalizing Flows and Change-of-Variable Formula.
The goal is to plan a path (via K and ) such that the initial data can be linearly separated. It happened automatically in NNs and Neural ODEs show that. It’s called gradient flow. See Deep Neural Networks Motivated by Partial Differential Equations, J Mathematical Imaging and Vision, 2019. Also Neural Ordinary Differential Equations, Neurips, 2018.
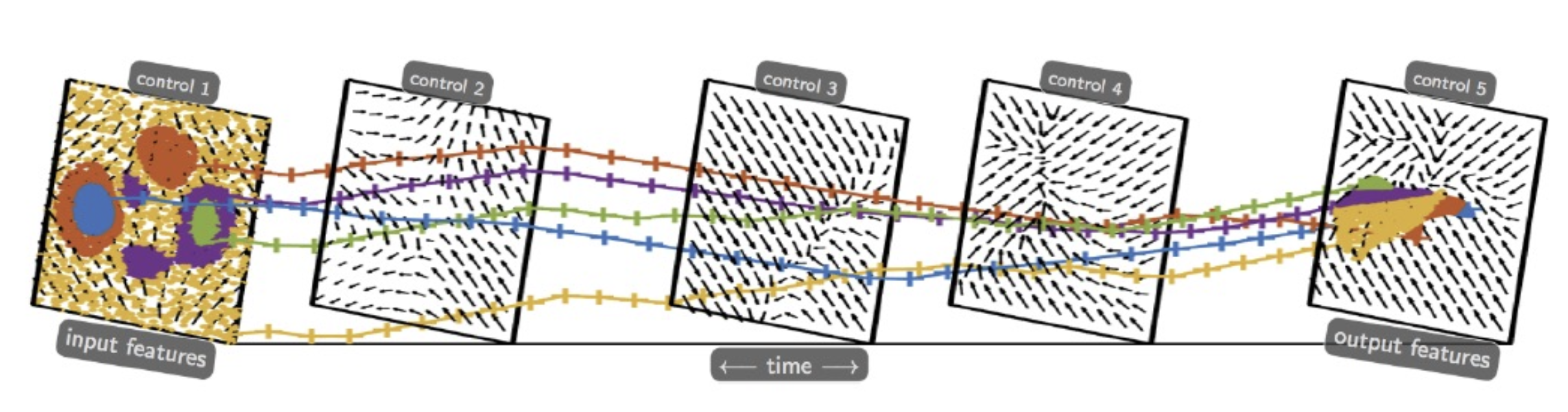
From Discrete Layers to Continuous Dynamics
The idea is that a deep Transformer with many layers can be viewed as a continuous-time dynamical system. We treat the layer index as a time variable , and each token is a particle evolving over time. The standard self-attention update is:
where is the product of query and key matrices, computes how much token should influence token . The softmax ensures the sum is 1 so is a proper probability over all tokens.
The full self-attention layer (including the residual connection from before) is:
Each token is updated by adding a weighted mixture of all other tokens, transformed by the value matrix . We assume or (which keeps the gradient flow structure — meaning the system minimizes a well-defined energy).
Layer Normalization
RMSNorm is moving the current distribution to a sphere. It constraints all tokens to have unit norm, up to a learned rescaling.
- are learned parameters
- The projection restricts dynamics to the sphere .
So after each attention step, we project back to the sphere:
This means: at every layer, each token moves in the direction of the weighted average of all other tokens, then gets snapped back to the unit sphere. K plays with depth (how many layers = how long time runs).
Discrete Continuous Time
Now we go from discrete layers to a true ODE. Call an artificial “time” and a small step. Moving from layer to :
This looks exactly like Euler’s method. Now subtract and divide by , then take :
The inner product here means: project the attention-weighted sum onto the tangent plane of the sphere at . In the continuous limit , it becomes a Neural ODE.
So the Transformer is literally an ODE solver for token dynamics on a sphere. “Going to infinite time” means running many layers until the dynamics converge.
From Particles to a Distribution
Instead of tracking each of the tokens individually, we can describe them collectively as a probability distribution. The empirical measure is:
So basically it’s just a sum of Dirac point masses — one at each token’s location at time . The sum is then an integral w.r.t. . For a generic measure on the sphere, the velocity field each token experiences is: something too terrible for the normal eye to see…
It’s the continuous version of softmax attention — instead of a sum over tokens, it’s an integral over the full distribution .
Once we have a velocity field that tells each token how to move, the distribution itself evolves according to the continuity equation (also called the transport equation):
If you take the entries of the gradient and sum them up, you get the diversion . Here comes the nice idea of the trace of the Jacobian Matrix from Flow Matching. This is how the Transformer comes to its answer. ufffff…
In other words: if probability mass is flowing with velocity field , this equation says “mass is conserved” — whatever flows in equals what flows out. The (divergence) is the sum of partial derivatives of in all directions — it measures whether the flow is compressing or expanding at each point. The Transformer arrives at its final output distribution by solving this PDE.
Interaction Energy and Gradient Flow
The continuity equation is a mean-field PDE. There’s also the energy it dissipates:
This interaction energy measures how “aligned” all token pairs are (via the kernel , which is large when and point in similar directions). The dynamics monotonically increase along trajectories — tokens are being pushed toward mutual alignment. This is a gradient flow with respect to a modified Wasserstein (optimal transport) distance. Optimal transport of token distributions directly links to Flow Matching and Diffusion models.
Rank Collapse
The picture below is what rank collapse or mode collapse looks like in Transformers. And it can happen very easily apparently. So the eigenvalues of provide concrete explainability of issues like this (rank collapse). If changes in time, then we have Neural PDEs.
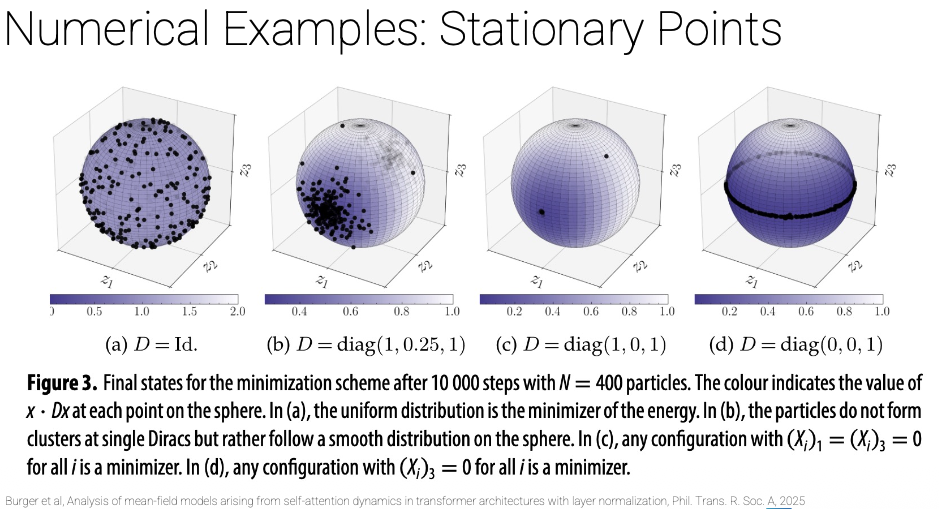
The stationary states of the dynamics depend entirely on the eigenvalues of
- (all eigenvalues equal 1): tokens spread uniformly on the sphere — no collapse.
- : tokens cluster but don’t collapse to a single point.
- : any configuration with the 1st and 3rd coordinates zero is a minimizer — collapse onto a great circle.
- : full rank collapse — all tokens collapse to a ring in a single direction.
Rank collapse is when all tokens converge to the same (or a low-dimensional) representation, destroying the diversity of information. It’s the Transformer analogue of Mode Collapse in GANs. The eigenvalues of directly predict when and how this happens — zero eigenvalues in are the danger signal. If changes over time, we get Neural PDEs as a natural extension.
Final pipeline
- tokens are particles on a sphere attention is a velocity field running layers is solving an ODE in the limit we get a PDE for the distribution the eigenvalues of explain why collapse happens.
Learning Paradigms: Supervised, Unsupervised, Self-supervised
With Un-supervised learning we apply SVD and PCA to see the clusters that form in the data (cats that have similar faces sit together etc). One application is reconstruction: mask a patch of an image, encode the rest, decode to fill it back in. The reconstruction error acts as a self-generated training signal — but note, these models are not trained to be good at reconstruction as a final task; reconstruction is just the learning signal.
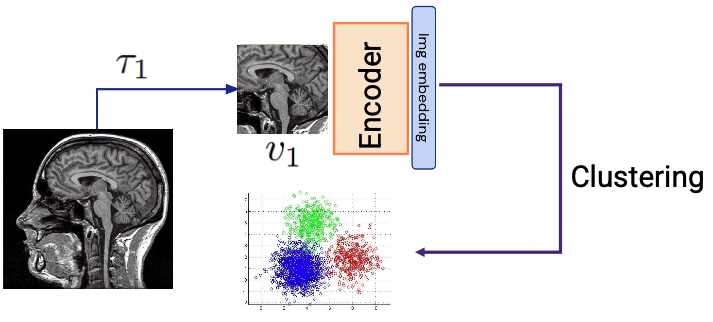
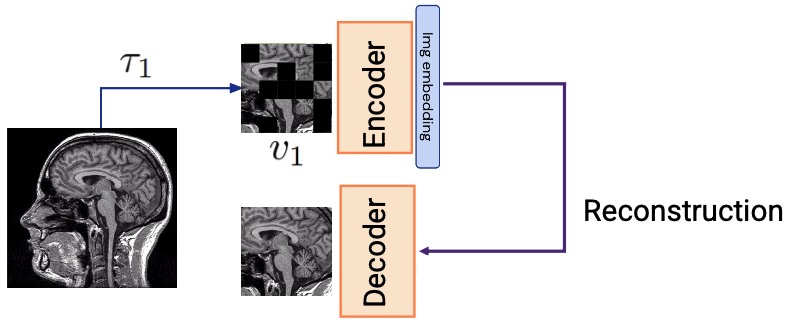
Self-supervised learning(SSL) is done through similarity or dissimilarity. You look at a patch for two different POVs (features) and compute how similar they are ⇒ there’s learning involved.
Consistent View Alignment
Take the same image and create two different augmented views (crops, flips): and .
Compute their embeddings and train the model so representations of the same image are similar, and representations of different images are dissimilar. This gives me the (Dis-)Similarity signal.
The difference from unsupervised: in unsupervised you find structure that already exists (PCA clusters); in SSL you define a task (are these two views of the same image?) and the network learns features to solve it. Distillation (student-teacher) falls here: the teacher generates supervision signals for the student without human labels.
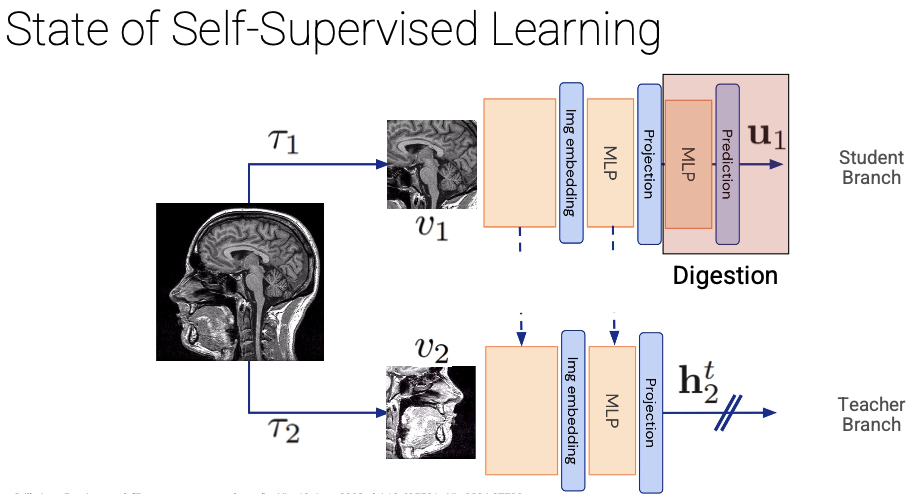
- First layer is on (dis)-similarity and feature extraction. This is the shared backbone (both student and teacher have it, with shared weights via the dashed arrows).
- Second layer is for “Disentanglement” of the learnt representations — the projection head separates the representation into independent factors (e.g. “shape”, “texture”, “position” become separate dimensions rather than entangled).
- Third layer is for “Digestion” (Prediction head, student only) — this is the extra MLP that only the student has. Its job is to predict the teacher’s representation from the student’s projection . This is the clever trick that prevents collapse: the asymmetry between student (with prediction head) and teacher (without) means the network can’t trivially output the same constant for everything and still minimise the loss.
Why doesn't this collapse to all-constant features?
Because the teacher’s weights are an exponential moving average of the studen’t weights — so the target is always slightly “ahead”.
Self-supervised learning allows us to see what the heads are learning.
Golden rules of Self-supervised learning:
- Don’t let your features collapse (make it stable) through contrastive loss (CLIP), teacher-student asymmetry (DINO).
- Don’t make your features random. The similarity signal enforces this: two views of the same image must produce similar features, so the network is forced to learn something meaningful about the content.
Foundation Model
Anything that gives you meaningful re-usable features.