Lecture from the GenAI Models and Robotic Applications. Related to Normalizing Flows.
Resources: Flow Matching for Generative Modeling paper, this blog from Cambridge
Flow matching is a training method used to learn a mapping from a source distribution to a target distribution by approximating the underlying vector field.
Diffusion Flow Matching Generative Models
Velocity Fields and Continuous Normalizing Flows (CNF)
In NF, we had and . The transformations are independent.
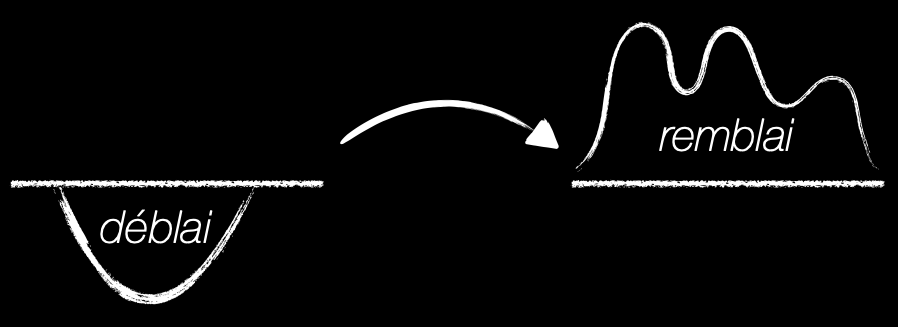
- Deblai: base probability density (to sample from)
- Remblai: target probability density (images, videos).
Time-Dependent Velocity Field
We have a trajectory from the noise to a realistic output …
Different definitions use different steps. We use .
We can now consider the rate of displacement in time with help of derivatives.
The velocity is essentially a model that given an input, time step, and parameter, it’s able to approximate the velocity with a neural network.
We have a ordinary differential equation (ODE).
Which velocity fields are relevant?
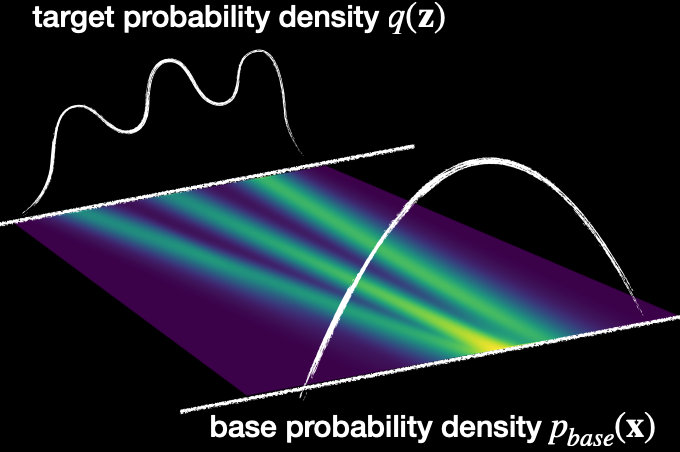
We already covered in Normalizing Flows that with the help of Change-of-Variable Formula we can go from one Density Function to another with the following formula:
- which is the same as
- where training is done via Maximum Likelihood Estimation
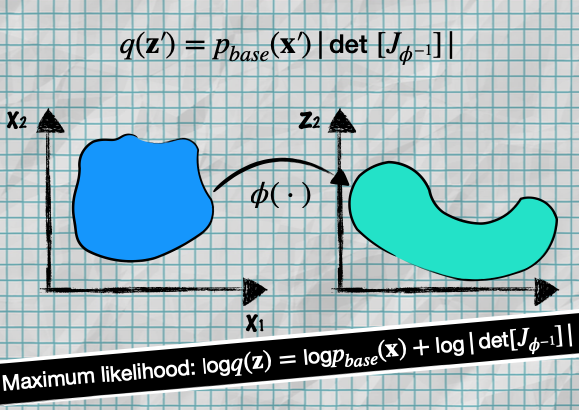
- don’t forget that to go from target distribution space to latent space , we define
The logarithmic compression of a volume element equals the time-integrated expansion rate along its path
Jacobi’s formula
At this moment, we have complexity because the Jacobian Matrix has elements. If we want to compute the determinant of that, we actually have complexity.
So using Jacobi’s formula, we show that we only need the Trace of the Jacobian Matrix (sum of the diagonal)
This reduces the complexity from to .
So now, considering the equations from before, we can express the end location as the start the accumulated displacement over :
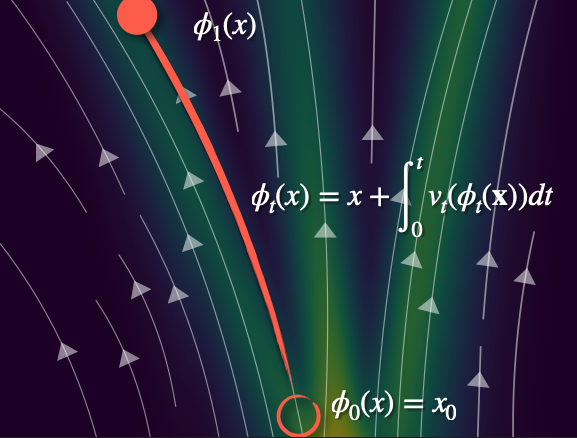
ODE numerical simulations are very expensive
Since we want to train a ODE NN with max likelihood. This is where Euler’s Method comes in.
For ordinary differential equations (ODEs) we can approximate their solution by taking small sequential steps using a tangent
Euler’s Method
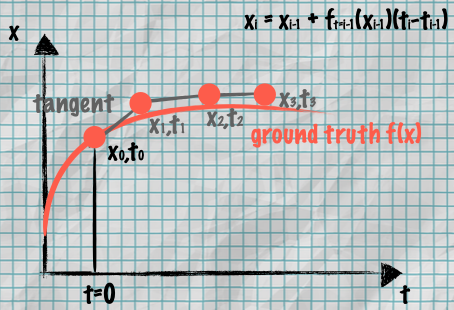
So I hope it’s clear that we approximate the velocity field with an ODE solver (e.g. Euler’s rule).
Now we can define the Loss Function of Flow Matching based models which is based on MSE (Mean Squared Error):
where
- is the probability path
- is the velocity NN with params
- is the velocity field from solver (Euler)
So I covered the fact that CNFs are slow due to the ODE integration at each iteration. CFMs are a very nice solution!
(Conditional) Flow Matching (CFM)
Can be CLIP as the condition(the label). They use the Euler approximation which gives those cartoonish effects in most generative models’ output. So it’s basically always sampling through an enormous database (400 million) in case of CLIP.
But what should the probability path be?
The CFM loss function learns a velocity field conditioned on target samples from , where is a path distribution.
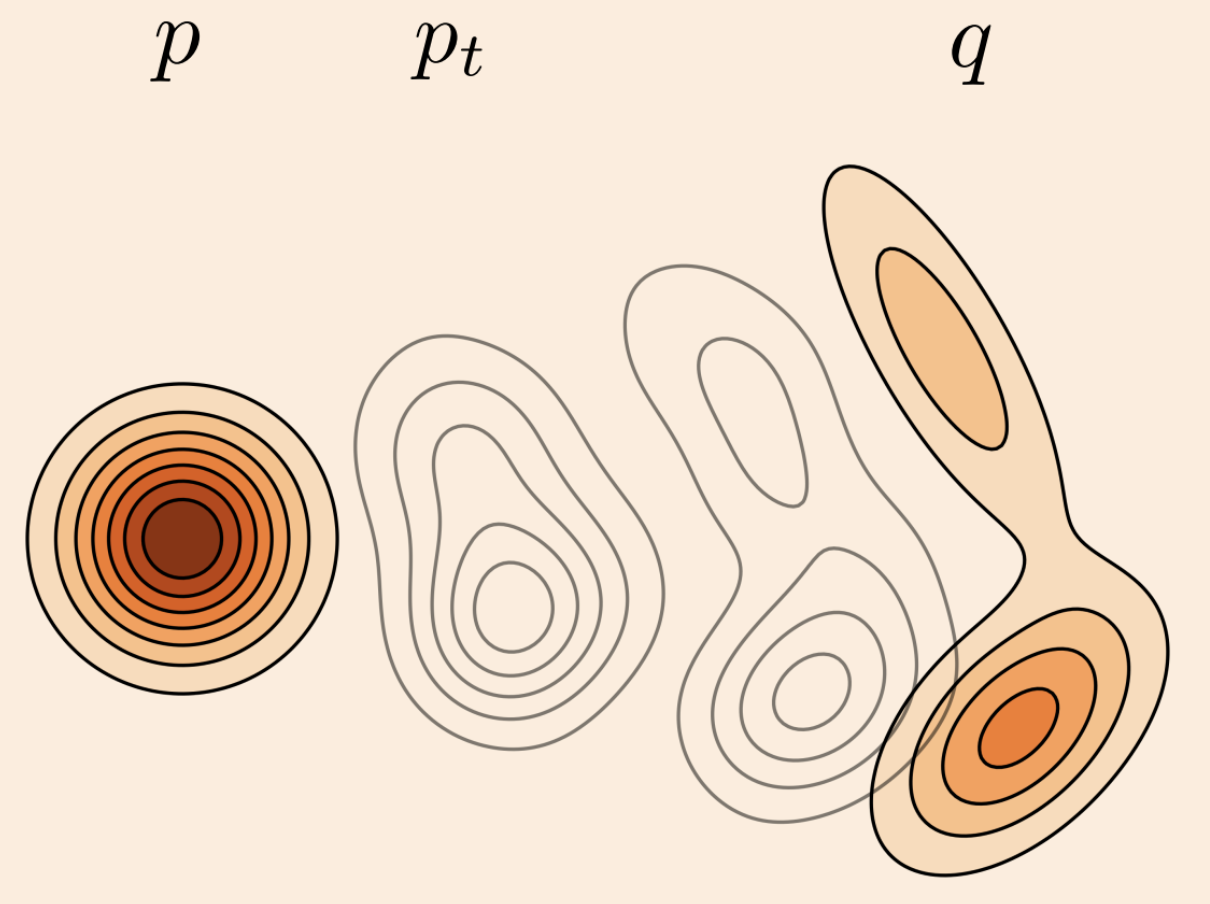
The key difference: CFM conditions on individual data points from the target distribution , making training easier by decomposing the problem into simpler conditional paths.
- is the image in the database
- is the noise sample.
- c is the constraint from CLIP (text) or any other VLM.
CFM inference: find a image in the database based on the constraint (c = labels(i)).
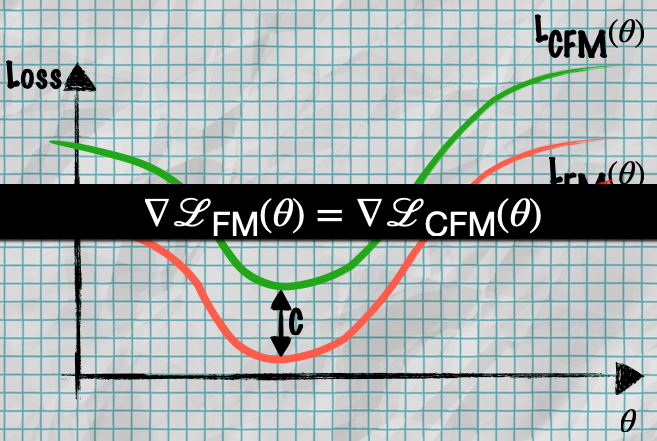
- Key Insights:
- Their gradients are identical. The two loss functions only differ by a constant offset C
- Optimizing CFMs is equivalent to optimizing FMs (same optimal parameters)
- So you can train using CFM and get the same results as the harder-to-compute FM
Reminder: velocity is the rate of change between random noise and the image from the database.

You use the conditional flows to define your loss function (left) during training, but what emerges from that training is a network that predicts the marginal flow(right).
Conditional flows are the individual velocity fields for specific conditioning pairs . They are used to construct the training objective but aren’t directly what the network predicts.
Marginal flows are what you get when you average all those conditional flows together. This is the actual velocity field the network learns to predict.
Mean Flows
Resource: Mean Flows for One-step Generative Modeling
Code implementation: this blog
The core idea is to introduce a new ground-truth field representing the average velocity , whereas the velocity modeled in Flow Matching represents the instantaneous velocity .
Flow Matching essentially models the expectation over all possibilities, called the marginal velocity given a marginal velocity field
Given the actual data and the noise , a flow path can be constructed as
By setting and , we can instantly generate outputs from inputs (1-step only). So the “core idea” is we can generate with less steps, since the model already averages over . If , then it reduces to standard Flow Matching.
The bigger the step, much farther away we are from the actual image. I want to not be constrained by where I am. I want to start at r and stop at t. I’ll take the average velocity accumulated. is the new timestep. It works best for bigger steps.

The ultimate aim will be to approximate the average velocity using a neural network . The approach is much more amenable to single or few-step generation, as it does not need to explicitly approximate a time integral at inference time, which was required when modeling instantaneous velocity.
Mean Flow Training
The Mean Flow Identity:
And therefore we can finally express the average velocity as:
Training with Average Velocity:
We now introduce a model to learn (denoted as )
And in the end, the loss function for Mean Flow models is represented as
From the paper: The term uses the instantaneous velocity as the only ground-truth signal; no integral computation is needed. While the target should involve derivatives of (), they are replaced by their parametrized counterparts (. In the loss function, a stop-gradient (sg) operation is applied on the target because it eliminates the need for “double backpropagation” through the Jacobian-vector product, thereby avoiding higher-order optimization.

The loss function is as in FM, but they take the mean velocity. Understand the highlighted part from the paper (). You mix the mean flow and the normal flow (In some steps you do one, in some you do the other). I mentioned above that if , then it reduces to standard Flow Matching.