stands for activation functions in this lecture. stands for weights . is bias? The subindex of each hidden layer represents the hidden layer of the neural network.
Convolution assumes weights sharing. Which means it always goes with the same parameters over the image. Each layer is a filter. We only have width and depth. The connections are sparse (between the hidden layers), but we have the same information in the layers, if I understood that correctly. Equivariant features (i.e. due to the parameter sharing used in CNNs, the feature maps are equivariant w.r.t. translations. so in my own words, if i rotate the image; the filter also rotates with it?) — see Convolutional Properties.
- smartass, when you say translation you understand rotation?? This is just a self-roast. The idea is that if the image gets shifted a bit to the right or whatever, that won’t change the way the Convolutional Layer observes it, since the feature map will simply shift by the same amount.
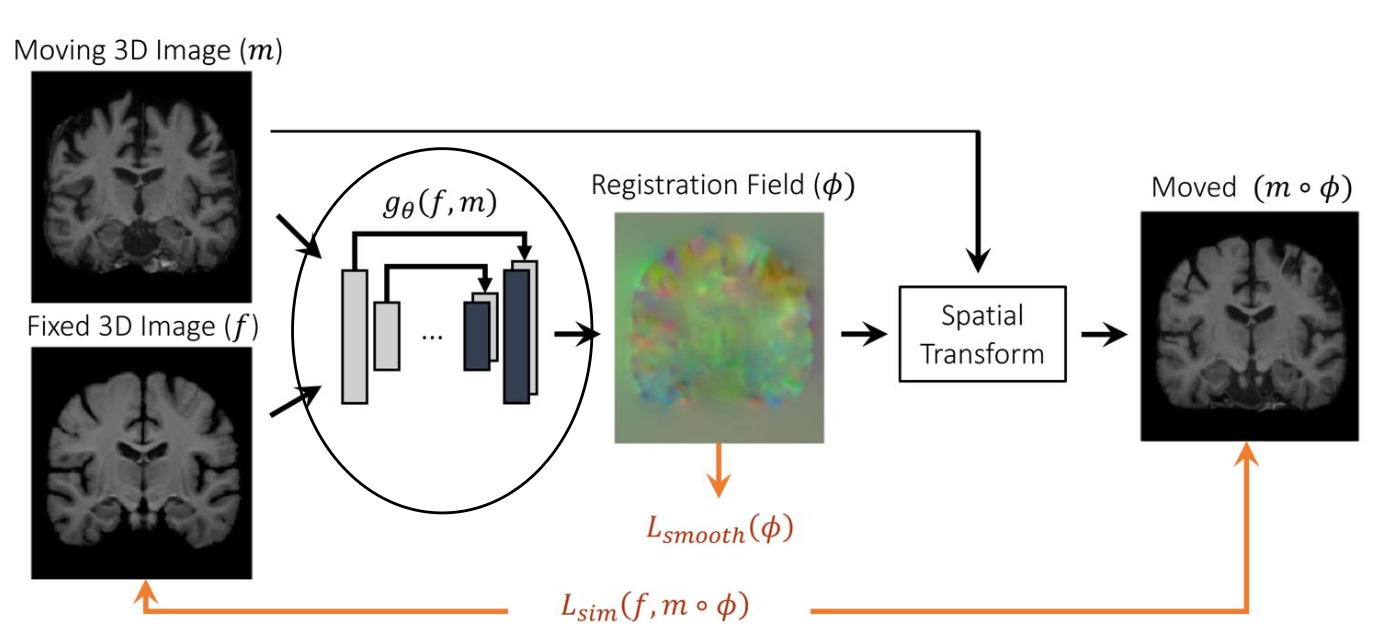
Deep Learning in Imaging: Image registration aligns two images into the same coordinate space. You use a neural network to compare a moving image with a fixed target image. The network learns the registration field, which acts as a dense mathematical map of movement instructions.Then, you apply this vector field to the moving image using a spatial transform. This step warps and pushes the moving image so that it perfectly matches the anatomy of the fixed image.
In NLP it’s different because the input size usually fluctuates. You embed each word, and it’s kind of challenging to relate every word to every word (ofc with Transformers).
Apparently, Attention is NOT all you need (look at the paper, lol. it’s exactly this name).
With Transformers, a token is a unit of data. In NLP, tokens represent words or syllables. The motivation was the need of a model where parameters don’t increase with input length.
How to handle a sequence of tokens?
- In CNN, token features depend on those of neighboring tokens
- Stack many layers or use large kernels to consider more context
- RNNs maintain a hidden state of past data.
- Vanishing gradients for long-term dependencies
- Struggle with parallel processing
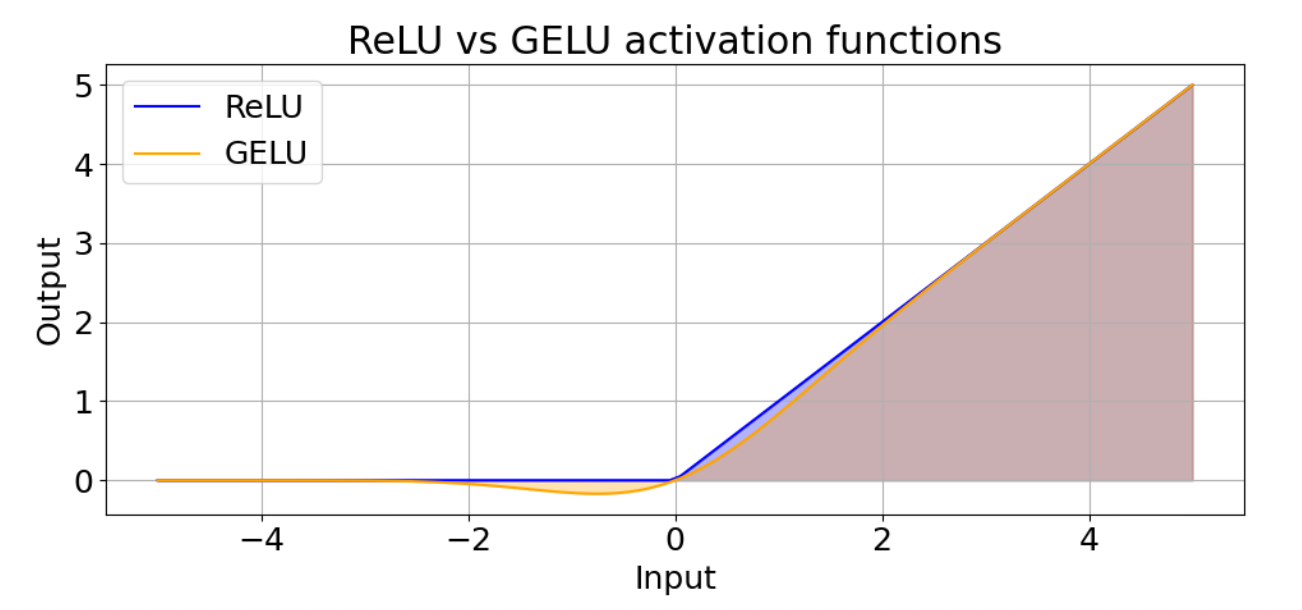
GeLU is generally considered more stable and statistically meaningful than ReLU, particularly in deep architectures like Transformers.
- it helps prevent the “dead unit” problem. ReLU strictly outputs zero for all negative values, which can cause the gradient to drop to zero and neurons to permanently stop updating during training. GeLU, as shown in the graph, has a smooth curve that dips slightly below zero for small negative inputs. This ensures there is a continuous gradient everywhere, allowing the network to always receive feedback and keep learning.
- it incorporates probability. Instead of a hard mathematical threshold at zero like ReLU, GeLU multiplies the input by the cumulative distribution function of a Gaussian distribution. This means the activation acts like a smooth, probabilistic gate, weighting inputs based on their statistical likelihood rather than a simple cutoff.
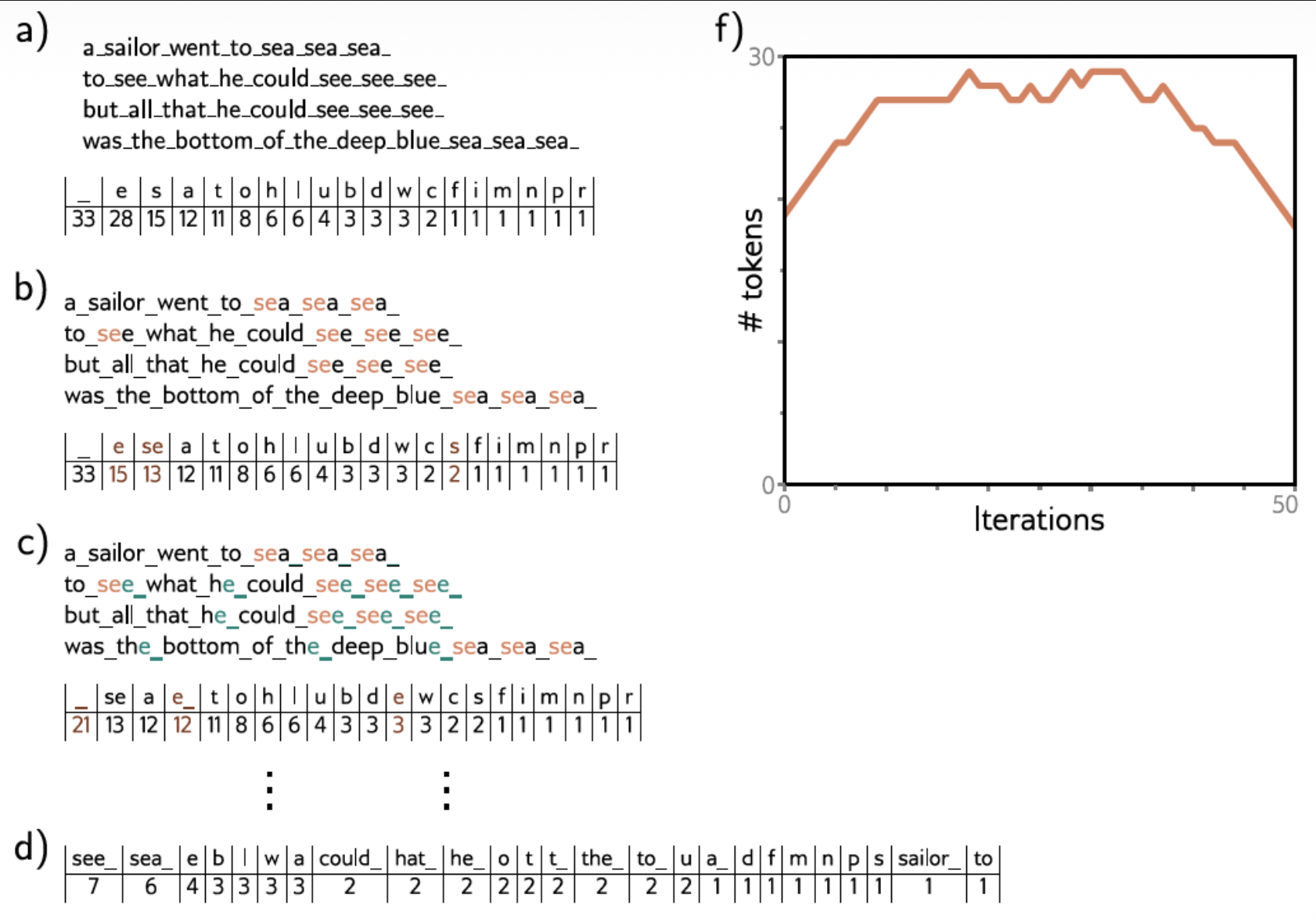
Sub-word Tokenization
He mentioned byte-pair encoding (BPE) for reduction of the tokens (see, sea example). Familiar concept from NLP. The original issue was that the vocabulary would need different tokens for versions of the same word with different suffixes (e.g., walk, walks, walked, walking) and there was no way to clarify that these variations are related.
Three types of Transformer Layer
- Encoder Models (BERT)
Encoder architectures process the entire input sequence simultaneously to build a deep understanding of the context. Encoders are typically used for tasks that require analyzing text, such as classification or extracting information, rather than generating new text
- Decoder Models (GPT-3)
Decoder models are built specifically for generation. Their primary job is to predict the next word in a sequence by building an autoregressive probability model. A key feature of decoders is “masked” self-attention, which ensures the model can only attend to past words and cannot “cheat” by looking ahead at words it hasn’t generated yet.
- Encoder-Decoder Models
These models combine both structures for sequence-to-sequence tasks, such as machine translation. In this setup, the encoder processes the source input (e.g., an English sentence) into a mathematical representation, and the decoder then relies on that representation to generate the target output (e.g., a French sentence) step-by-step.
Positional Encodings
solves the problem with self-attention not distinguishing between the positions of tokens.
- “The dog bit the man”
- “The man bit the dog”
Self-attention can not figure out who bit whom without positional information. Attention is permutation invariant because it is only a weighted sum of values. That’s where the positional encoding comes in and makes it clear that “The dog bit the man” and not the inverse.
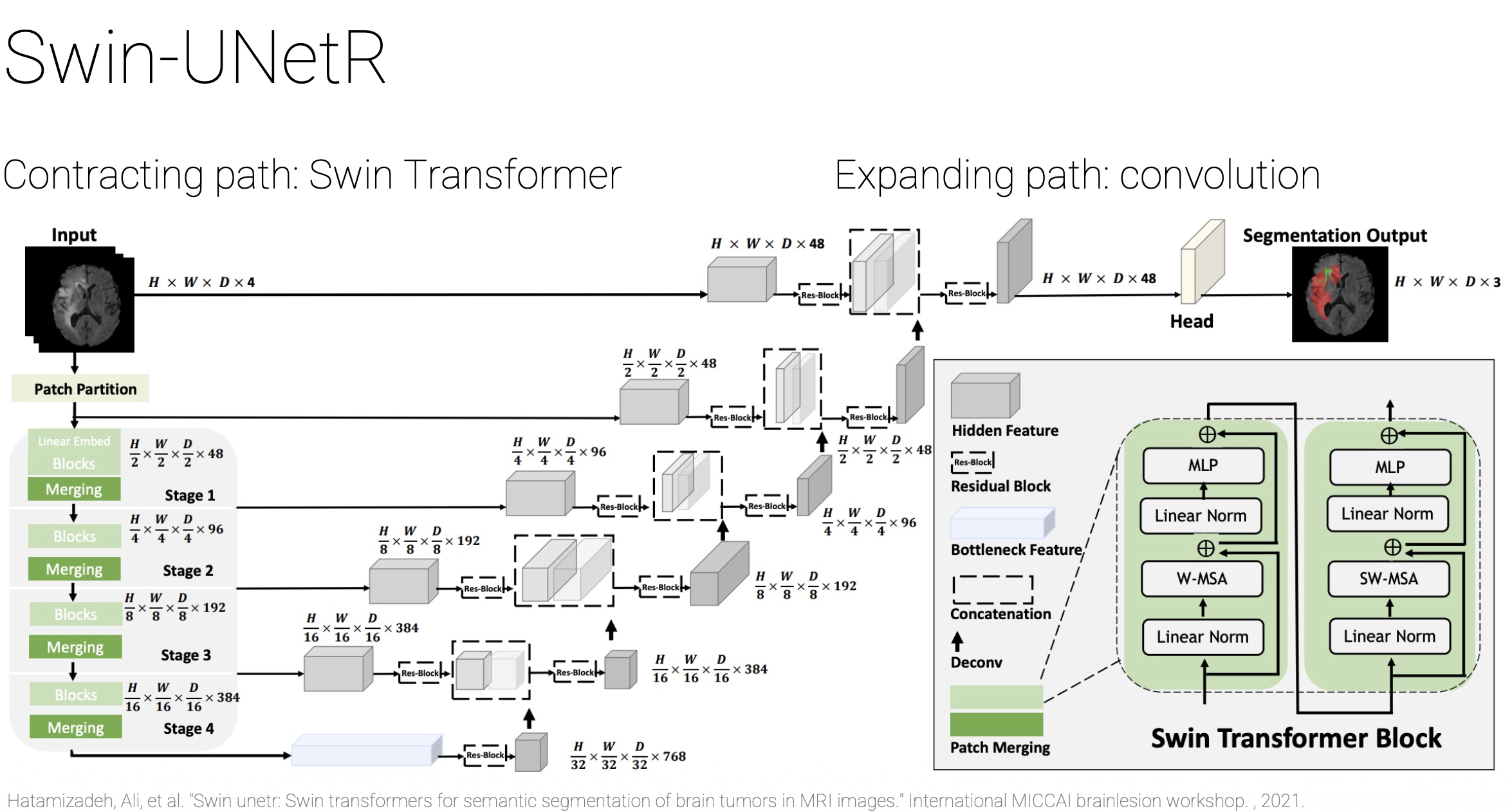
Look into Swin (Shifted Window Transformer)?
From Gemini
Standard Vision Transformers are computationally heavy because they analyze the entire image globally at once. Swin Transformers solve this by restricting their focus to small, local windows and calculating attention only within them. To ensure the network still understands the big picture, the windows are shifted in the next layer so information can flow across the boundaries.
I saw something with Swin U-Nets. Gray is patches and Red is windows
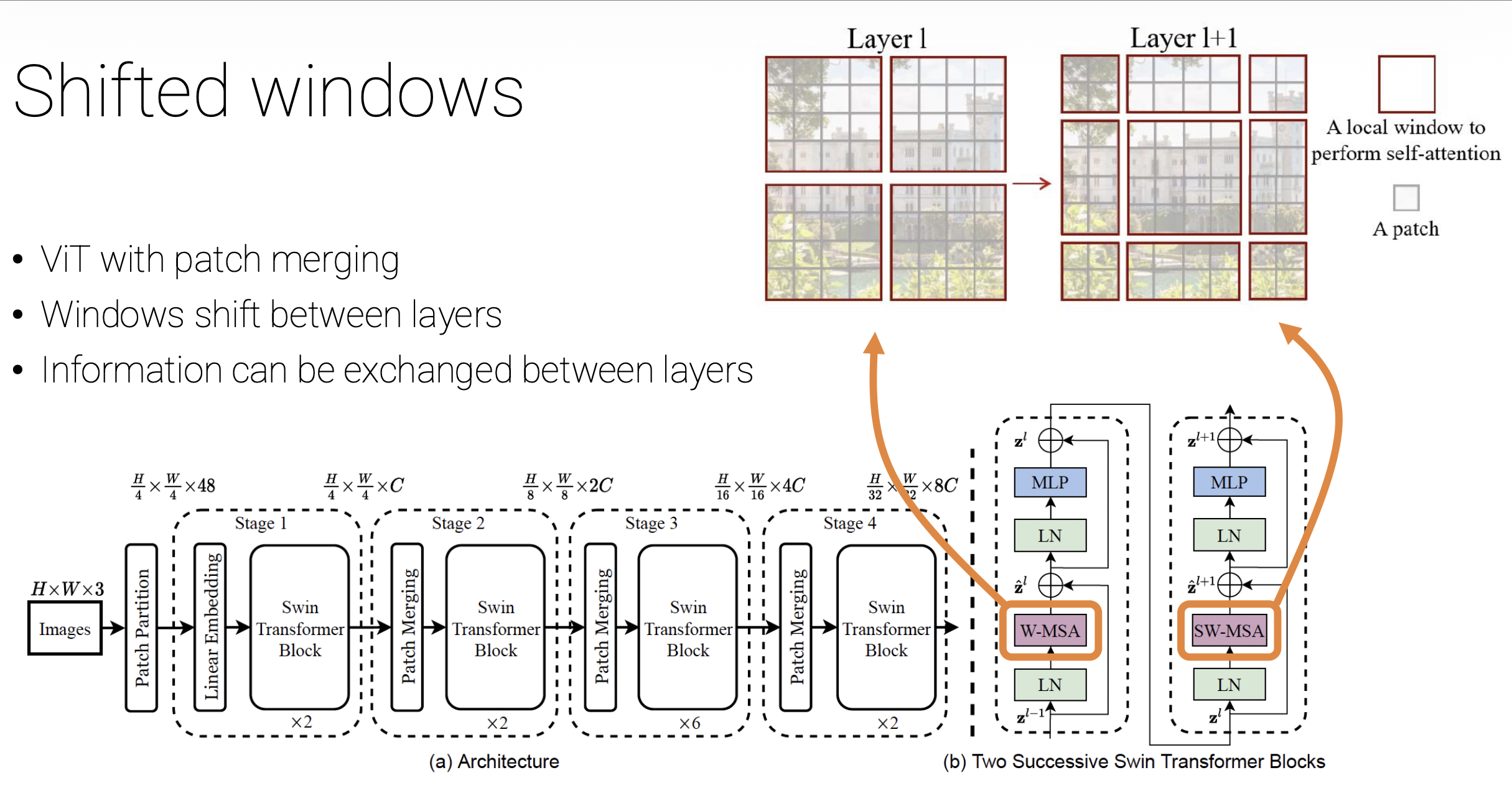
Shifted Window (SWIN) Transformer brings back 2 inductive biases from CNNs:
- Locality (attention only within blocks)
- Hierarchy (aggrating smaller patches into larger ones)
Also see
nnU-Net revisited: is it actually worth it to use Transformers for e.g. in medicine applications when CNNs already do the job so well? It’s actually useful to understand the distribution of the data you’re working with. Is it Gaussian or something else? Do you even need transformers? See ViT.
What exactly prevents the heads from learning the same thing?
To prevent the multiple heads from learning the same thing, you could set different activation functions (if I understood correctly) + ensure the initialization is different.