Specifically, Lidar-Inertial SLAM.
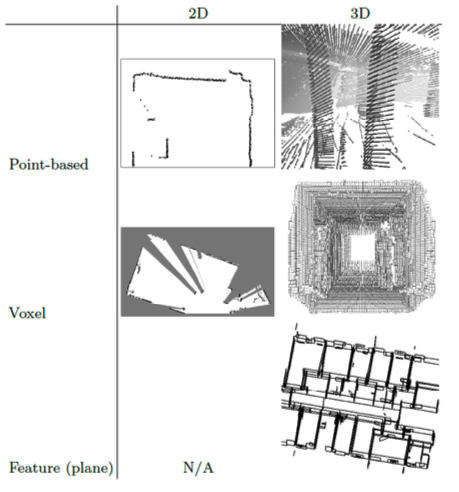
The basic idea is you build a map and then localize the robot on that map. I discussed in Lidar-Inertial Perception the types of map representations and also the scan matching methods.
GraphSLAM
“Given all sensor measurements and motion constraints collected so far… What is the most probable set of robot poses and map variables?”
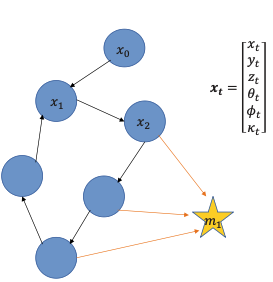
- In graph representation, all robot states are discretized into nodes
- Nodes are robot poses (circles) or observed features (stars)
- Link indicate
- transformations (𝑹, 𝒕) between consecutive poses (i.e. spatial constraints)
- observations of features, i.e., perception measurements
This means that this factor graph is a topological map.
Since every edge corresponds to a spatial constraints between two nodes, we need to optimize the graph:
- Minimize the error introduced by the two constraints (alter nodes and change links)
STATE SPACE
We consider the position and orientation as the states:
If we consider a 2D graph, then one robot state is equivalent to
How to discretize the trajectory so that the problem is computationally sound?
We use the key frames concept from Lidar-Inertial Perception. We discretize the trajectory w.r.t. time , or by saying that there can be only one state per traveled distance (e.g. )
Motion Constraint
Since we are talking about Lidar-Inertial SLAM, the IMU tells us how the robot moved or the control input .
We denote as the motion constraint.
To complete the update from one state to the next, we also need to take noise into consideration:
where we define as the Process noise covariance matrix.
Measurement Constraint
This is mainly about finding the landmarks and making use of the information from them. For this, we define a measurement model h which relies on landmarks with signatures and observer position .
Therefore, we can define the measurement against the previously known landmark position of .
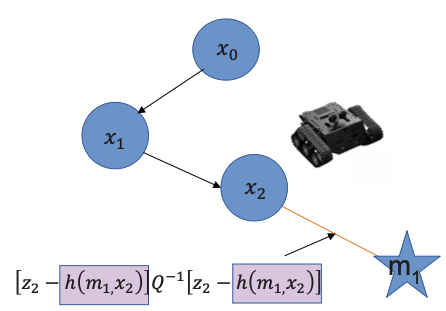
Since for this we use the Lidar, the measurement vector contains the range and the viewing angle (against robot orientation ) with signature :
where we define and as the Measurement noise covariance matrix.
The basic SLAM problem
These two constraints together describe a basic SLAM problem: given with the noisy control input and the sensor reading data, how to estimate (localization) and mapping problem?
So the 4 important variables:
- the pose of the robot in body frame
- the motion constraint using the IMU data in body frame
- the measurement constraint in body frame
- the measurement model which is the pose of the landmark in body frame (LiDAR)
Graph Construction
After constructing the graph, we have a cost function J to minimize. The graph contains all the measurements between time and
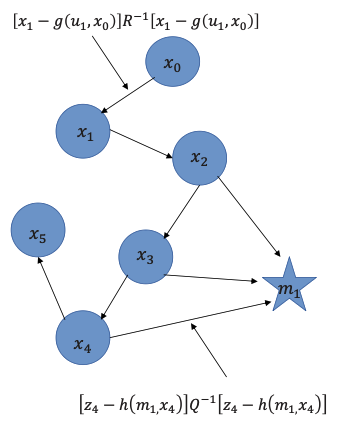
To construct the cost function, we first define the information matrix where graph links are represented in a matrix.
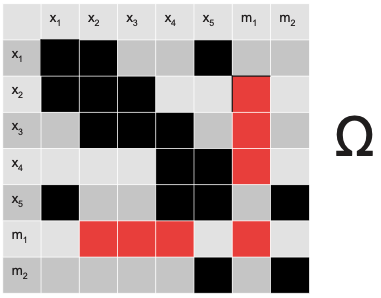
Therefore, we define:
Took from Section 11.4.3 of the Probabilistic Robotics book by S. Thrun:
We define to be a vector composed of the robot poses and the landmark positions , whereas is composed of the momentary pose at time and the respective landmark:
Linearizing the Motion Model:
The various terms in the loss function above are quadratic in the functions and , not in the variables we seek to estimate (poses and the map). Thus, we have to linearize g and h via Taylor expansion around the current estimate :
- Here is the current estimate of the state vector .
- is the Jacobian of g at
We define the motion residual:
Then:
Linearizing the Measurement Model:
- is the current estimate of state
- is the Jacobian of
We define the measurement residual:
In class, we expand
The Jacobian of w.r.t. the full state vector is:
- it’s a row vector (a sparse matrix row) that:
- is zero everywhere except at the positions corresponding to:
- the current pose (where we have )
- the observed landmark (where we have )
- is zero everywhere except at the positions corresponding to:
Example: If we are at pose observing landmark :
The Full Linearization of the Cost Function:
After linearization, we substitute back into the cost function. For the measurement term:
Let be the correction we want to find. Then:
By expanding this quadratic, we will get the contribution to and
- Information matrix (from quadratic terms ). It tells us which states are connected
- Information vector (from linear terms ). It tells us how much correction is needed in each direction.
Similarly, for the motion model, we have:
Define the Jacobian for motion in the global state space: Where:
- appears at position (for )
- (identity) appears at position (for )
The contribution to :
The contribution to :
Once we have and , the solution is:
where is the correction to apply to the current state estimate:
Some insights:
- we can recover the covariances after solving
- we iterate because linearization is only accurate near the linearization point
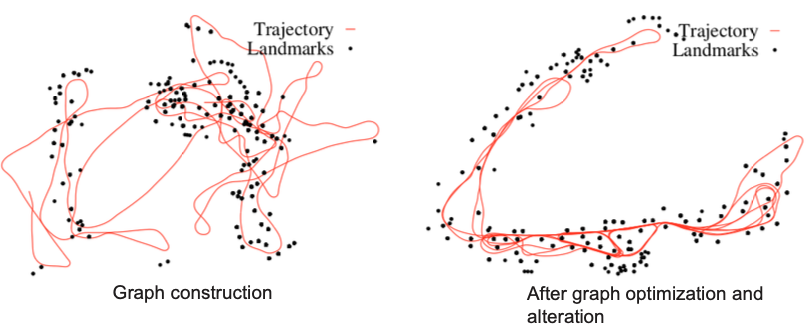
Now we can answer these questions:
Why isn’t integrating all odometry enough?
- Because odometry has cumulative errors (drift) that grow unbounded over time
Consider a factor graph, why is it useful to represent the robot trajectory this way?
- Sparsity (the factor graph represents only the constraints, not all correlations),
- modularity (we can add constraints incrementally)
How do nodes help with scalability when the environment gets large?
- We can discretize using the key frame concept.
- Helps with traceability.
Loop Closure
Covered in Loop Closure.
Impact on the map:
Why can a single loop-closure constraint dramatically reshape the entire map?
because Graph-SLAM solves one global least-squares problem over all poses. By directly coupling two distant poses in the trajectory, the new constraint changes the optimum for the entire problem. Consequently, many poses are adjusted simultaneously to satisfy all constraints, not just local ones
Applications for Graph-SLAM:
For example, in a forest. The tree foliage causes GNSS errors and the acquired trajectory and the point cloud is noisy. Therefore, formulating the trajectory as a graph means the poses are linked from the measured relative transformations between them. Also, the trees would appear circular and so easy to detect and insert in the Graph. Also, the method is successful only when D>>d. In this scenario, the trees are far enough apart that even with trajectory noise, the system can clearly separate observations from different trees.
Where the Method Fails:
The system breaks down in dense forests. When the distance between trees (D) becomes close to or smaller than the statistical error (d), the observations overlap.
- High Trajectory Noise: Larger drift makes the estimated position of a tree very uncertain.
- Small Feature Distance: When trees are packed together, the robot cannot distinguish if a measurement belongs to “Tree A” or “Tree B”.
Another idea: 3D Point Clouds
- Each point is a landmark
- use ICP for scan matching
- Solve for Rotation & Translation and Correct the Trajectory.
How does each sensor become just another constraint?
Sensor fusion is natural, diverse sensor data is encoded in constraints. New measurements affect only local parts of the graph, so it enables incremental and partial updates.
Data Association Uncertainty:
Often the largest and most dangerous source of error. The robot doesn’t know:
- which landmark it is observing
- which scan feature corresponds to which past feature
- whether scans overlap, or whether a loop closure is correct
Graph SLAM is in post-processing phase, so OFFLINE! It also has the largest sliding window possible: all the states ().
Bayesian GraphSLAM
slides 63-70
Notes from the professor
Why is it so hard for professors to make good materials? WHHYHWQQWRQ$!@#!EWQE!@# ok
Upgrading from Pair-wise ICP to Scan-to-Map (covered in Pen and Paper Exercises SLAM):
- Instead of aligning two individual scans , which causes drift, it’s better to scan to a local map M
- That translates into minimizing the cost function where
- This “sliding window” of recent scans provides a more stable geometric reference.
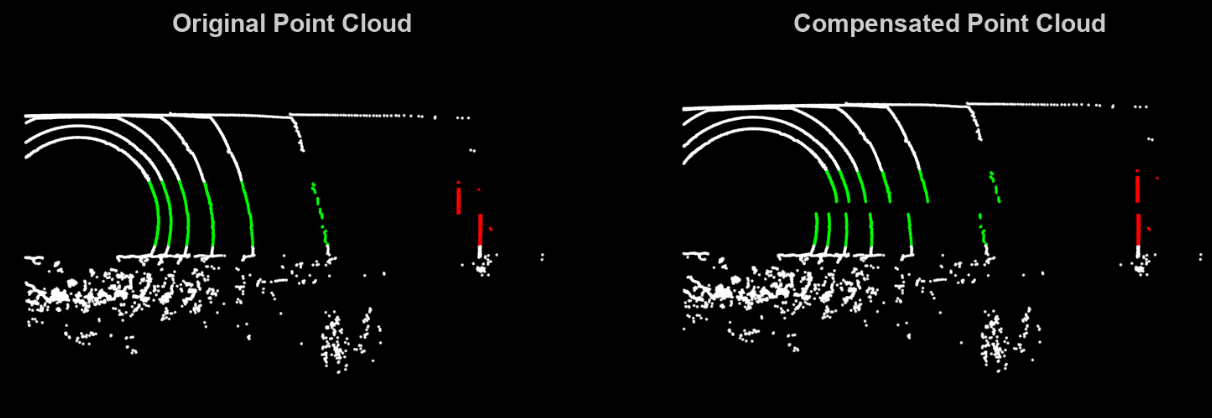
Motion Compensation (“Unwrapping”):
The notes show how we can model the motion and measurement constraints. However, when we want to implement them; we have to take into account that points were taken at different points in time . If we want to align them, we need to “unwrap” them to a single reference time . This actively prevents the warping of geometry (if I scan a wall, I want it to be fking straight, no?).
So the raw points are corrected using:
- The first transformation takes the coordinates to World Frame first, and then we rearrange all of them to the Body Frame back again but w.r.t to time .
Representing Errors in 3D (SE(3)):
We cannot subtract Rotation Matrices directly. It doesn’t really represent anything.
- So we use the Log Map to convert matrix differences into a 6D vector. It’s actually a really smart way of computing errors or optimizations.
- yields a vector where the first 3 components are the rotation error and the last 3 errors are the translation error.
you don’t believe me? I wouldn’t! Let’s see the mathematics
We consider .
The log map is , where is the axis-angle vector satisfying
Hence, the rotation vector expresses a rotation of magnitude about the unit axis . The rotation logarithm is
I’m not gonn’ memorize all this crap. But it’s good to provide some context on how it’s actually done.
The matrix is the left Jacobian of SO(3):
Very similar implementation in Rodrigues Rotation Formula where I implemented using the skew symmetric logic and SO(3) space.
Redefined Global Optimization
If we take sensor fusion into consideration, we need to take all residuals into account. Thus, the trajectory is solved by minimizing a sum of residuals from different sources (IMU, LiDAR, Loop Closures). It helps since it’s how sensor fusion actually happens—by weighting each sensor based on its uncertainty. How we get here is covered in Pen and Paper Exercises SLAM.
Each residual is weighted by its covariance , allowing the system to trust the IMU during fast motion and LiDAR when the geometry is clear. I read somewhere that the covariance is uncertainty, so its inverse is information.
- So intuition tells us that if uncertainty is high, the information is low. This mathematically forces the optimizer to give that measurement less “vote” in the final trajectory.