This is exercise 5/8 from my optimal estimation course. The goal is to implement a discrete Kalman Filter for a radar tracking application.
Context
I consider the same dynamic process from Prediction in a linear dynamic system (ex 4). Again time invariant, since the matrices do not change over time, only the states.
Only in this case, the position of the vehicle is measured by a radar system which is modeled by the following equation:
- is the measurement noise with a set covariance matrix.
sheeeeesh, a lot of context to be provided here. Referenced from Eq 4.25 to 4.27 in the book.
Linear-Gaussian measurement models
According to the book, a linear measurement model takes the following form:
- normally, they denote the noise with , but in this case we use it for velocity. So .
- is called the measurement matrix of size .
- be mindful that
Since the measurement matrix is , that means I should have a matrix. And since the noise only takes position into consideration, I can deduce that only needs to extract the component from .
Therefore, of size will extract only from .
Questions
**1. Determine . Also derive i.e. the expectation of the initial pdf.
Since we consider the same dynamic model, stays the same as in ex 4. The same applies to , only with the new values from the document.
However, to derive the initial covariance matrix, , I already have the standard deviations from the document. I only need to apply the following structure:
And since I have the variances for the initial states, the matrix looks like this:
Since this exercise assumes 2 axes for each variable ( ), each variance will be multiplied by the matrix. While the 0's become the matrix.
2. I have a .mat containing a vector of measurement readings. Create a for-loop that keeps track of the estimate and the corresponding error covariance matrix .
The implementation follows (8.2) from the book. I already have everything I need.
3. Create a plot with the measurements. Using the log, plot in the same Figure the estimated positions, and the predicted positions. Which of the three sequences look most noisy, and which look most smooth?
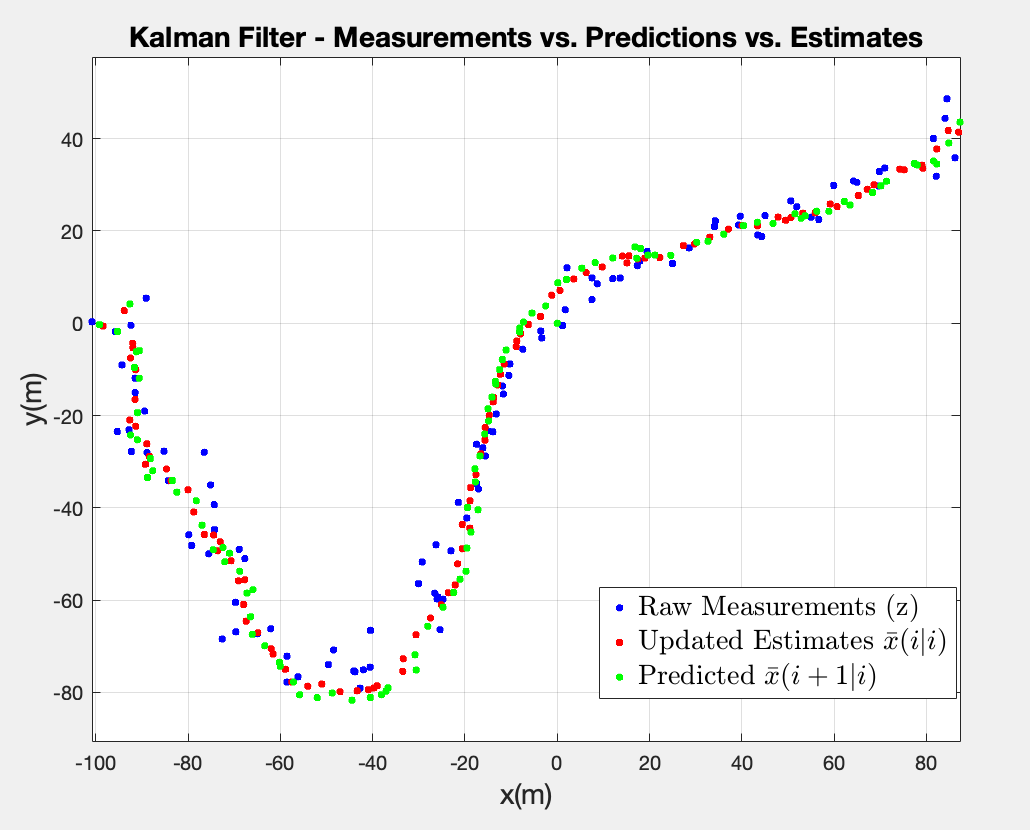
From the Figure above, I can safely say that the raw measurements are the noisiest of the bunch, and it’s expected since they represent measurements with real noise. In theory, the predicted positions should be less noisy but prone to drift since they rely entirely on the system’s kinematic model and the previous state estimate without incorporating current real-world observations and the estimated (updated) positions should be the smoothest sequence because the Kalman Filter optimally weights and combines the noisy measurements with the kinematic predictions.
However, the difference in this plot between the predictions and the estimates is very subtle. I would argue that the predictions have the smoothest shape geometrically since they rely more on the proposed kinematic model and the updated estimations are a little bit more noisy since they take those real-world observations and weigh them in the final results, which slightly contradicts my earlier statement regarding theory. One reason I could think of is the fact that the measurement noise covariance matrix is relatively large when compared to the process noise, so the Kalman Gain K is small and the filter trusts the prediction more than the measurement. This means the update step barely moves away from the prediction, hence they look almost identical in the plot.
4. Add the uncertainty regions. What are your observations w.r.t. the shape and size of the ellipse depending on ? Plot for every 3 iterations.
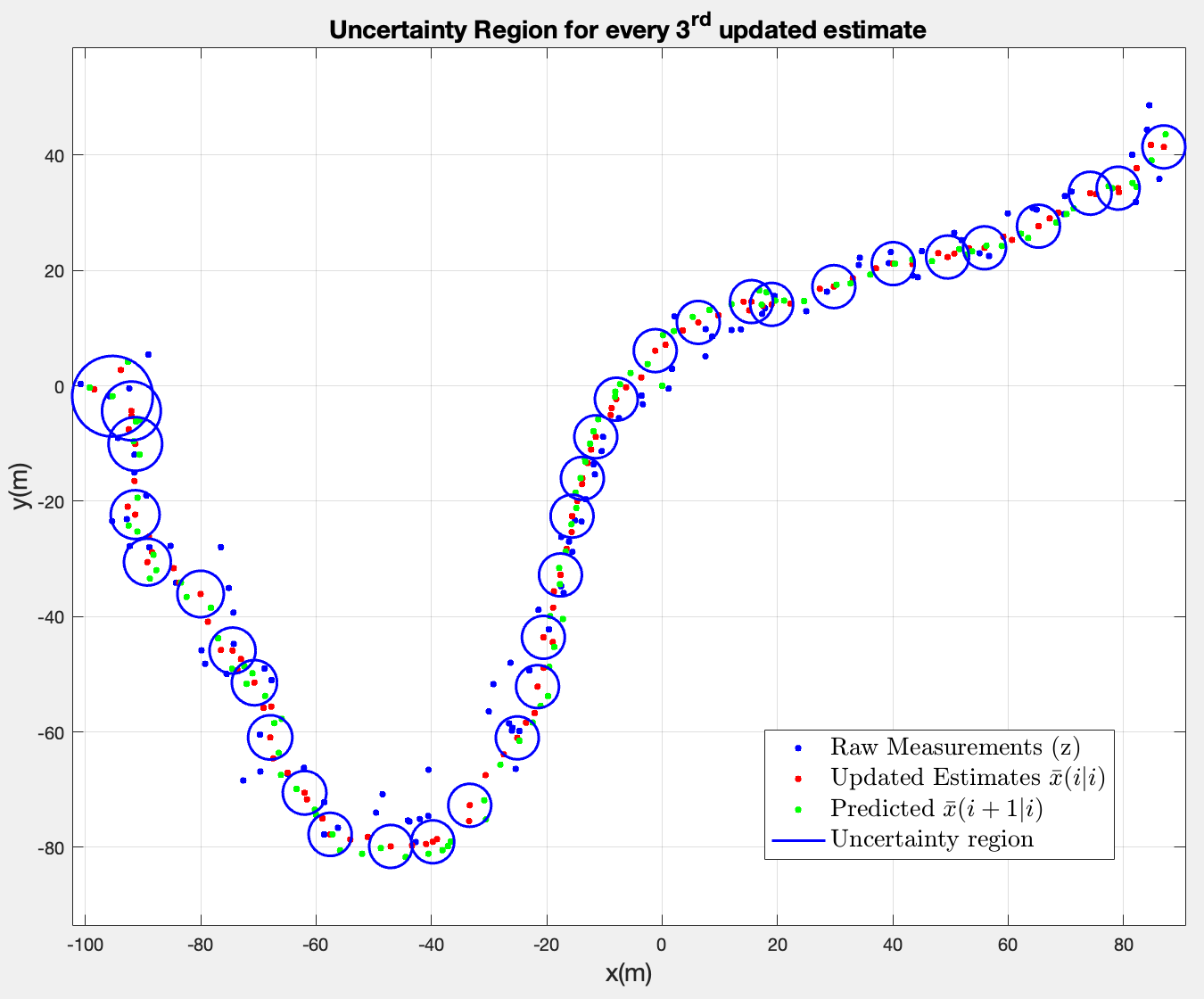
First impression is rather interesting. All uncertainty regions are circles, which corresponds to the diagonal shape of , which suggests that the measurement noise is equal in both and directions i.e. symmetric.
It also seems they converge to a constant size after a few iterations. At the start, is large (high initial uncertainty), so the first few ellipses are big. Since the system is linear time-invariant, the filter progressively reduces uncertainty until the error covariance matrix converges to a fixed value where the uncertainty added by at each prediction step is exactly balanced by the uncertainty removed by each update step.
5. Rerun Questions 2-4 while using the dlqe function to extract the Kalman Gain matrix and the covariance matrices of the steady state solution. Compare the matrices, to what extent to they agree? Compare and explain.
When subtracting the last iteration of my solutions to those from dlqe, the results are on the order of , , which is essentially numerical precision. This would confirm that my Kalman Filter has converged towards the steady state solution.
After rerunning the 3rd and 4th questions, I get the following results:
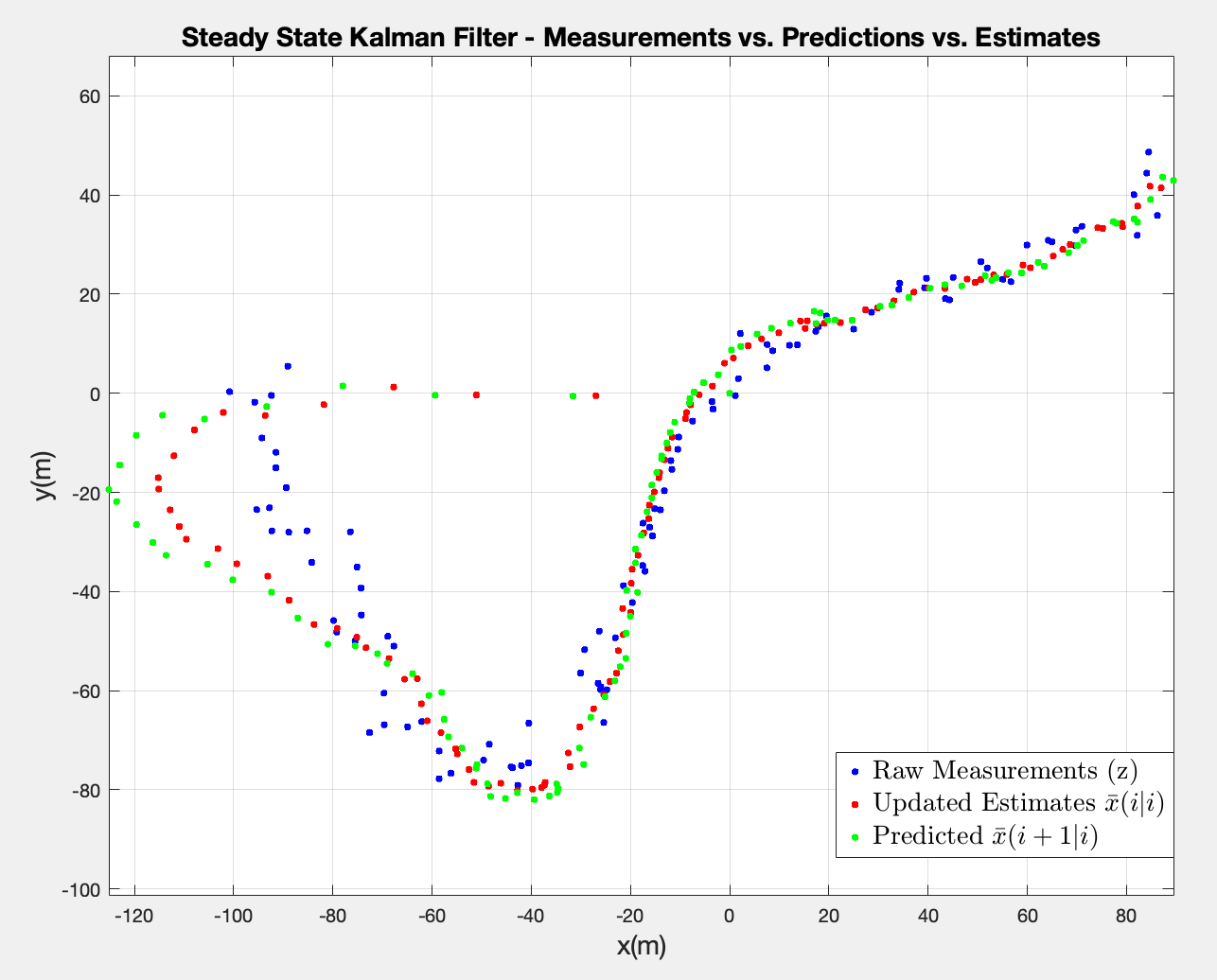
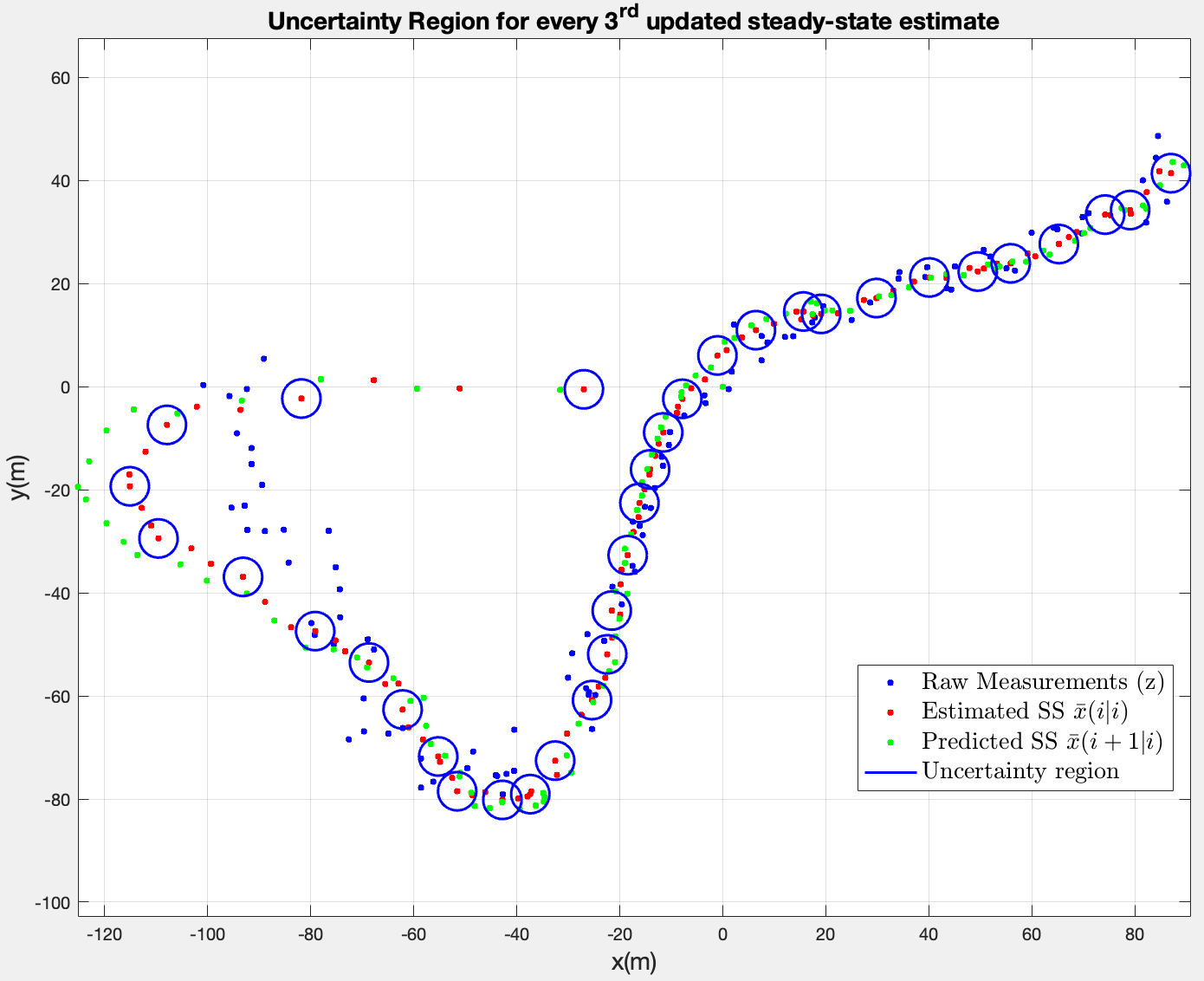
They suggest that the prediction and estimation start from the origin , causing them to drift badly at the start. In retrospect, it does make sense: the initial uncertainty in the previous case was high, resulting the big ellipses. Here, the filter assumes it has already converged, without taking that initial uncertainty into consideration, so the steady state Kalman Gain is too small to shift the results in the right direction.
In the previous case (time-varrying version), K started large because started large — initial uncertainty of 100 for the position. It translated into the filter trusting the initial radar measurements more.
The conclusion in this case is that the steady-state filter performs worse in the transient phase.