This is exercise 4/8 from my optimal estimation course. The focus is on propagation of uncertainty and prediction.
Context
Again, to gather data, we use dead reckoning. The navigator uses a log to measure the speed of the vessel and a compass to determine the heading. Together, they can be used to extract the velocity .
- Consider an estimate that is available for position and the velocity determined at time .
- Together, and provide sufficient information to deduce an estimate of the position valid for time . So we call the prediction with a lead of i.e. -step ahead prediction.
So I want to develop a predictor that can predict the position of the ship and that provides an uncertainty region. So in this application, the mean and the covariance will be propagated in time as opposed to Fundamentals of parameter estimation - Part III, where they were static. And the whole application was static.
I am provided with the identified linear state space model
where is a time invariant system matrix, and is a white sequence of Gaussian random vectors with zero mean and a time invariant covariance matrix .
Invariant means they do not change over time. Now I’m a lil’ bit confused, I thought I would have dynamic parameters now. So it’s the states that change over time and not the params? Reading this again, ofc that’s what it means; that’s exactly what a dynamic system is, dumbo.
so the state space is of type
Like any shitty dead reckoning which I don’t support, velocity and position are obtained through integration of their respective derivative. I guess she said white noise so maybe not so bad if accumulated but still bad you know what I mean? I want a beer.
These equations hold only for dt=1. In continuous time:
In discrete time with sampling period :
So integration becomes. Mind that and that’s it.
Questions
1. Using the first two state space equations, determine the matrix and the covariance matrix . Use the xsi array (load mat) to deduce the state vector .
By focusing on extracting the next state (updates), I can simply rewrite
Clarification: The 3 dimensions are all 2-dimensional vectors representing the and axes. Because of this, the next time step requires identity matrices, moving the overall system matrix to .
so, according to the equations above, and should look like this ( | | ).
Some explanations to myself
The overall system covariance matrix would suggest that uncertainty enters the system only through the acceleration. Position and velocity accumulate that uncertainty over time, but they don’t have their own independent noise sources. I feel like this is wrong from the start since it assumes the position and velocity are perfectly determined by integrating acceleration.
- Both and consider the vector.
2+3. Suppose we start from i=10 (11 in MATLAB because of 1-indexing). Predict the position at time j=i+l, where l=90. In other words, using , I want to predict the position steps ahead . The prediction equals only the expectation i.e. don’t take the covariance into consideration.
I think the idea is self explanatory. I need to apply over and over again until I will have hit the target. However, it says in the context that is based on measurements taken at time . It means that I never update i.e. it’s fixed.
The covariance is 0 at time and so on because the question says it is considered exact.
So bottom line, just keep applying forward. No updates, pure prediction.
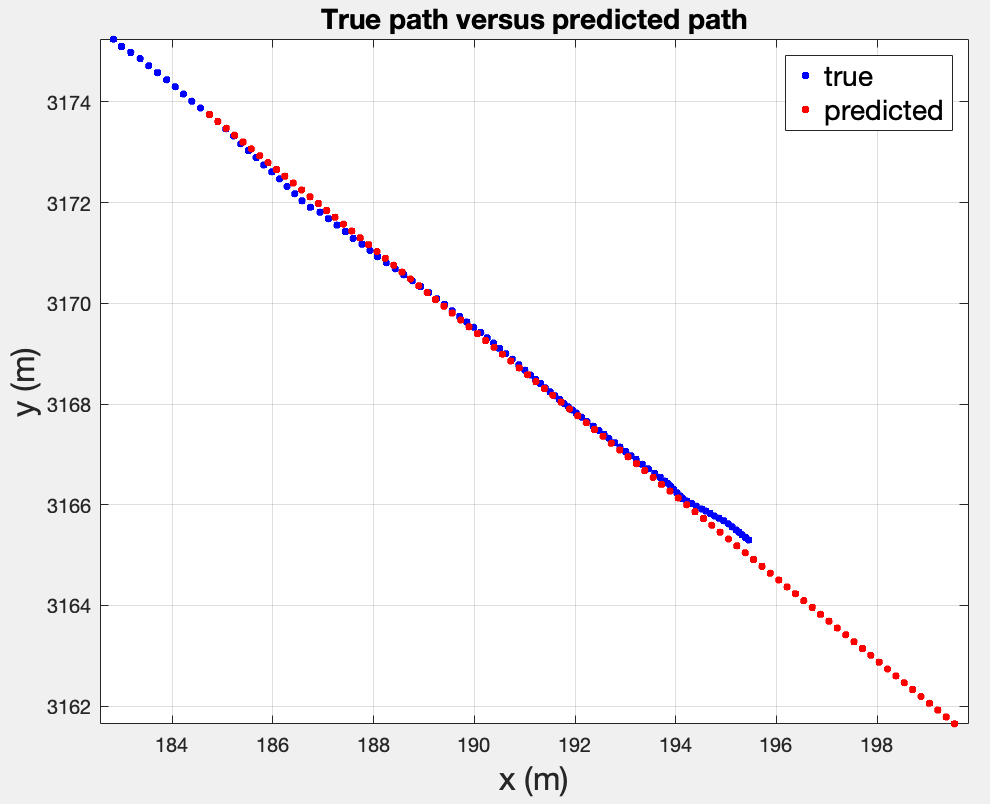
The results suggest:
- If we only predict and never update, we never react to the turn around the end. Also, the scales are different and the prediction assumes a mostly constant step at every iteration (See , I have for position).
- The prediction is a straight line, since propagating through is linear.
4. Suppose that the covariance matrix of a prediction is denoted by i.e. the covariance matrix of the prediction error . Draw the ellipse associated with the submatrix for .
From the book (page 90):
The white noise indicates that the expectation is zero and the autocorrelation is governed by the Kronecker delta function:
- is the covariance matrix of .
In the special case, where neither nor depend on i (i.e. the state space model is time invariant), the sequence converges to a constant matrix. If such is the case, then:
- This is the discrete Lyapunov equation
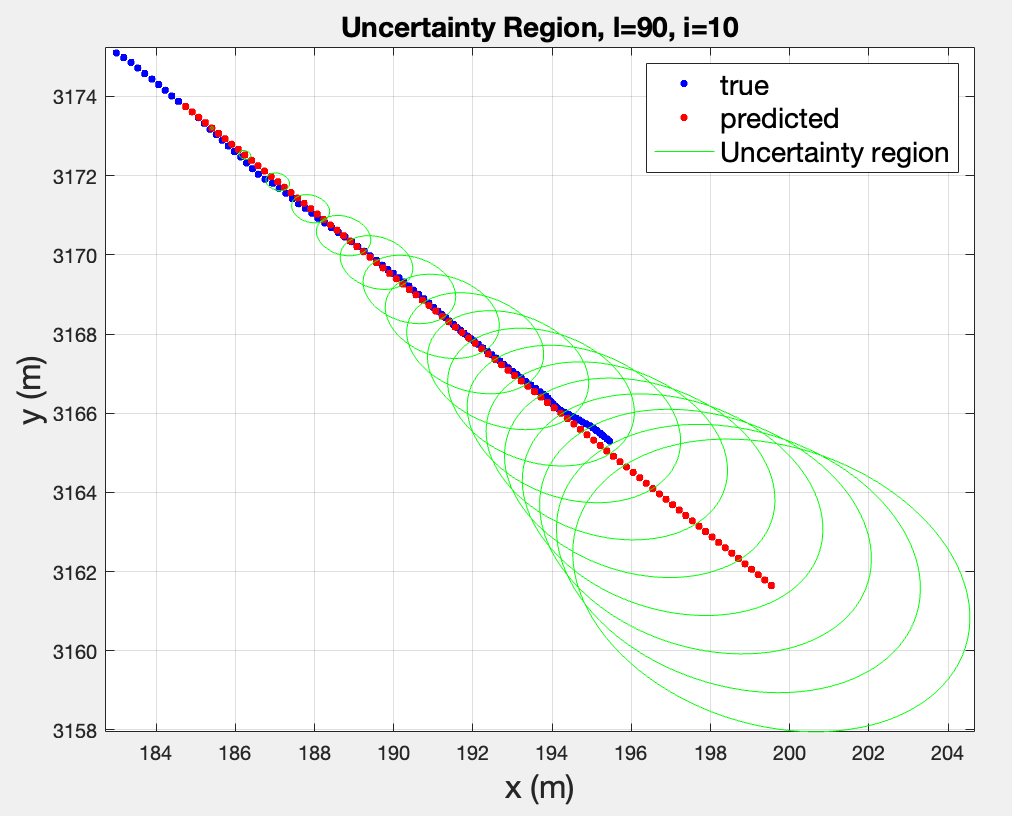
**5. Repeat for and . j is fixed at 100. Explain the results.
I plotted the uncertainty region for every 5 steps.




The trends reveal a obvious pattern: the larger the lead, the larger the uncertainty regions. This is expected, since every step adds to the covariance, so the longer I predict without updating, the more uncertainty accumulates.
For mostly every case, the true path eventually diverges outside the ellipses, especially in those where the prediction took place before the turn.
Bottom line: this is pure dead reckoning without any new measurement updates. The shorter the lead, the more reliable the prediction.