Topic that I encountered in my GenAI Models and Robotic Applications course at Twente.
Basic Concept
Normalizing flows exploit the rule for change of variables. Normalizing flows begin with an initial distribution, and apply a sequence of K invertible transforms to formulate a new distribution.
Learns complex joint densities by decomposing the joint density into a product of one-dimensional conditional densities, where each depends on only the previous values (so just like in Markov Chains):
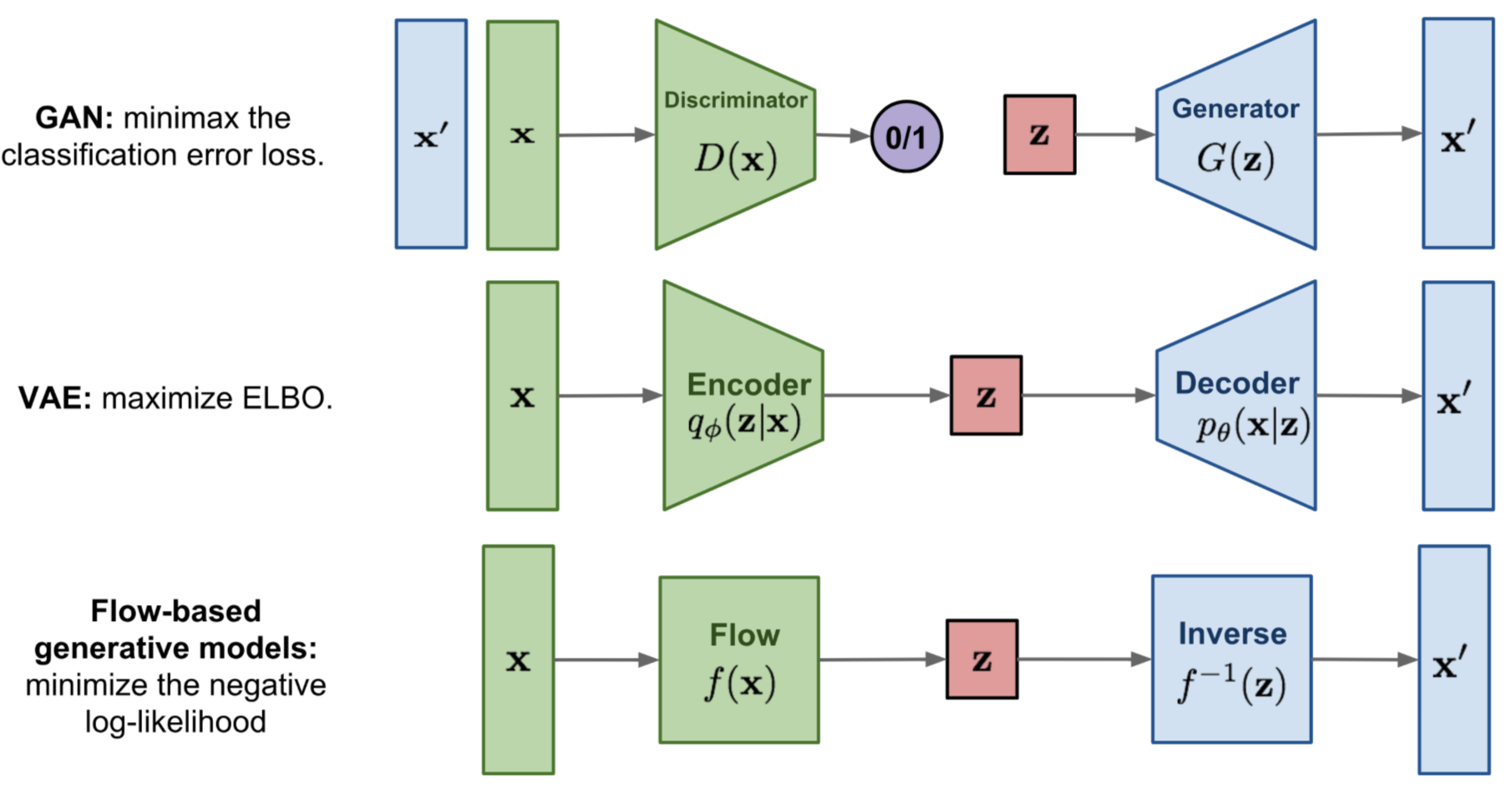
Quick summary of the difference between GAN, VAE, and flow-based generative models
- Generative adversarial networks: GAN provides a smart solution to model the data generation, an unsupervised learning problem, as a supervised one. The discriminator model learns to distinguish the real data from the fake samples that are produced by the generator model. Two models are trained as they are playing a minimax game.
- Variational autoencoders: VAE inexplicitly optimizes the log likelihood of the data by maximizing the evidence lower bound (ELBO). VAE is stochastic: it uses a stochastic encoder that samples from a learned distribution . It outputs a distribution. In VAEs, the model learns to approximate the mapping between data and latent Gaussian through separate encoder/decoder networks.
- Flow-based generative models: A flow-based generative model is constructed by a sequence of invertible transformations. Unlike other two, the model explicitly learns the data distribution and therefore the loss function is simply the negative log likelihood. Normalizing Flows are deterministic: no randomness is added when transforming . It’s exact; we know what happens. In flows, the Gaussian is transformed through exact, invertible functions to match the data.
What are Normalizing Flows?
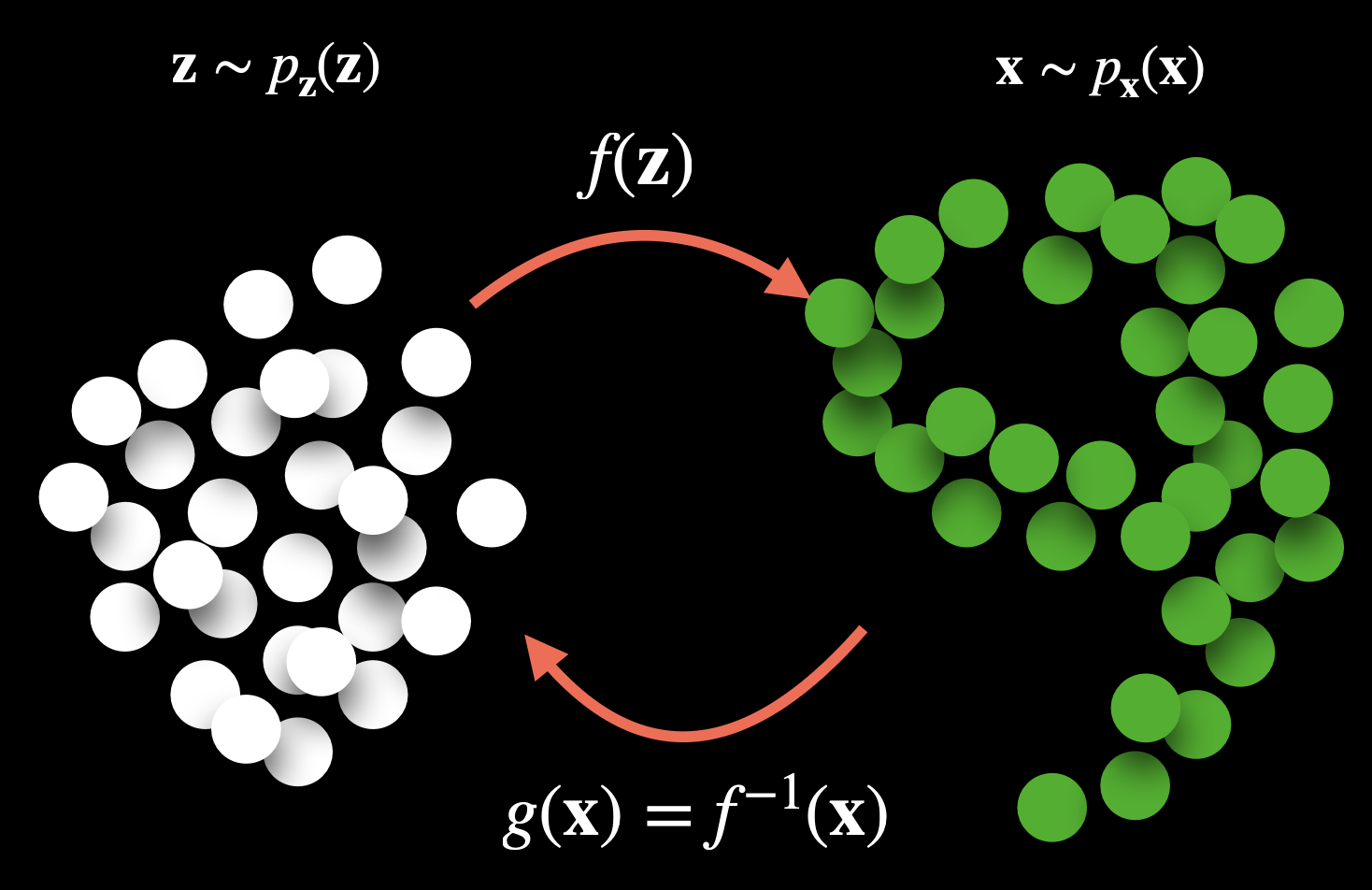
Normalizing flows learn an invertible transformation between data and latent variables:
- is a target distribution data sample
- is a latent variable sampled from the source distribution
If we define , then we have:
Intuitively, we can also write
Explaining the Jacobian
is the Jacobian of the model from x to z (the inverse direction).
We can write in terms of probability density function (see Change-of-Variable Formula theorem)
Since , we have:
It describes how the transformation maps from the data space (x) to the latent space (z).
Conversely, maps from z to x.
The restriction () ensures invertibility, which is why normalizing flows require bijective transformations.
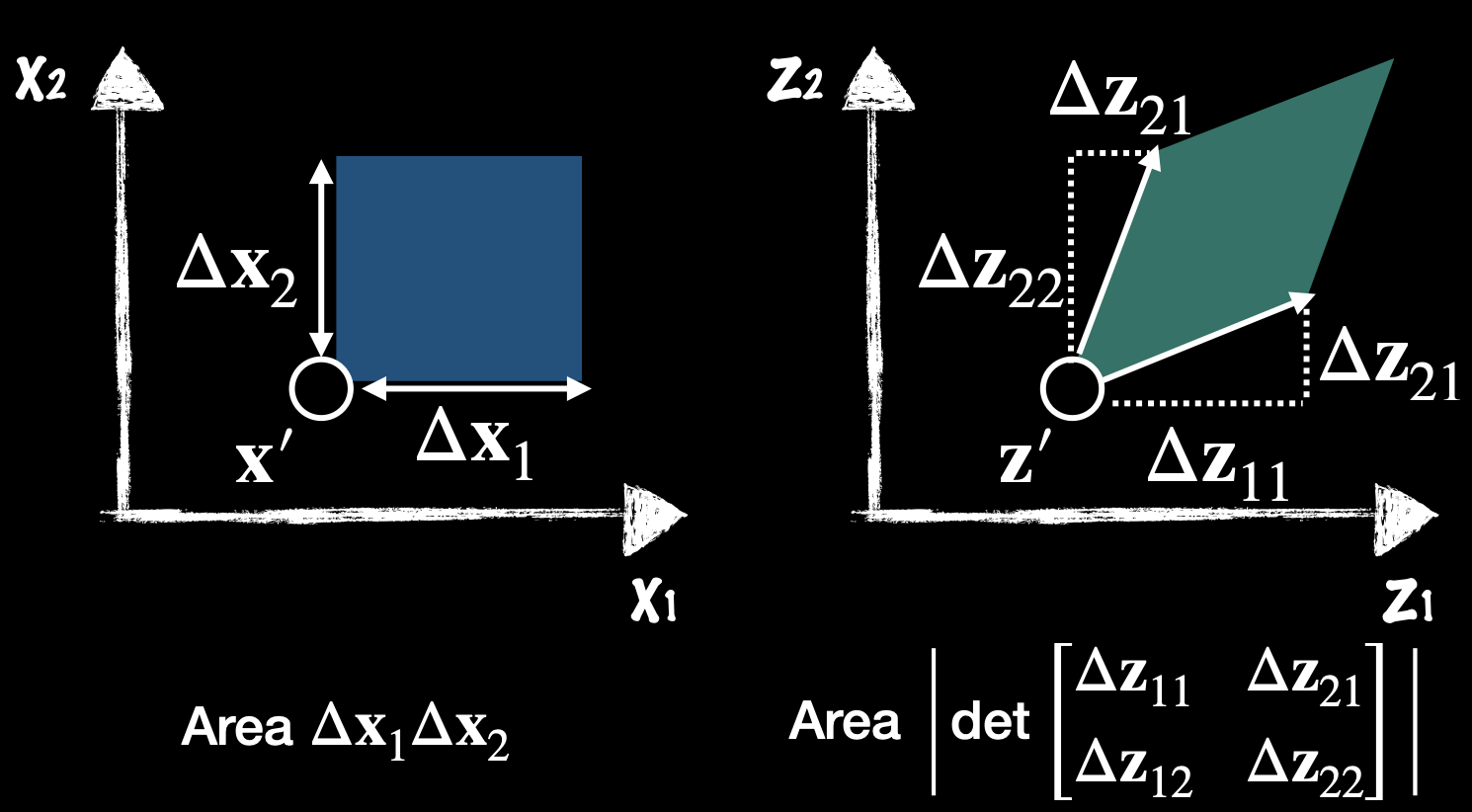
Here, indicates the ratio between the area of rectangles defined in two different coordinate of variables and respectively
You can't just have
The function in normalizing flows is perfectly invertible. In normalizing flows, we care about density estimation, not reconstruction. The loss is based on the log likelihood of data under the model (more below).
- That would basically be an Autoencoder.
- In training, data flows from where . We maximize (or minimize the negative log likelihood):
- In sampling/generation, data flows from , sample from the base distribution, and apply the forward flow: .
A normalizing flow transforms a simple distribution into a complex one by applying a sequence of invertible transformation functions. Flowing through a chain of transformations, we repeatedly substitute the variable for the new one according to the change of variables theorem and eventually obtain a probability distribution of the final target variable.
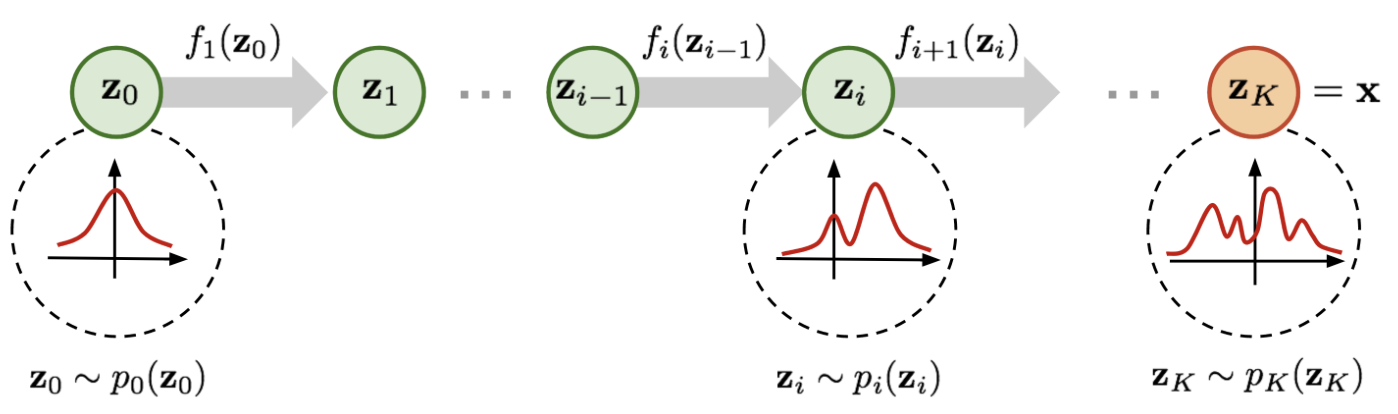
We apply a chain of invertible transformations (map the target distribution sequentially):
As defined in the figure above, we have
What does f look like? They’re generally Affine Transforms (affine coupling layer) since they are differentiable.
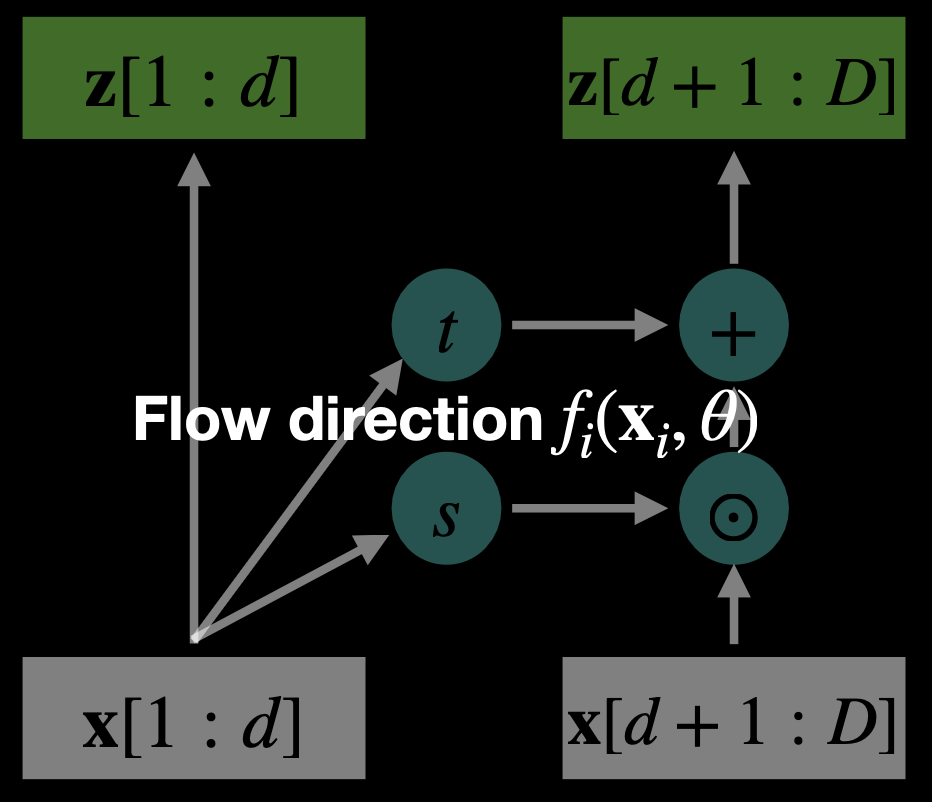
Flow Path (Forward Pass):
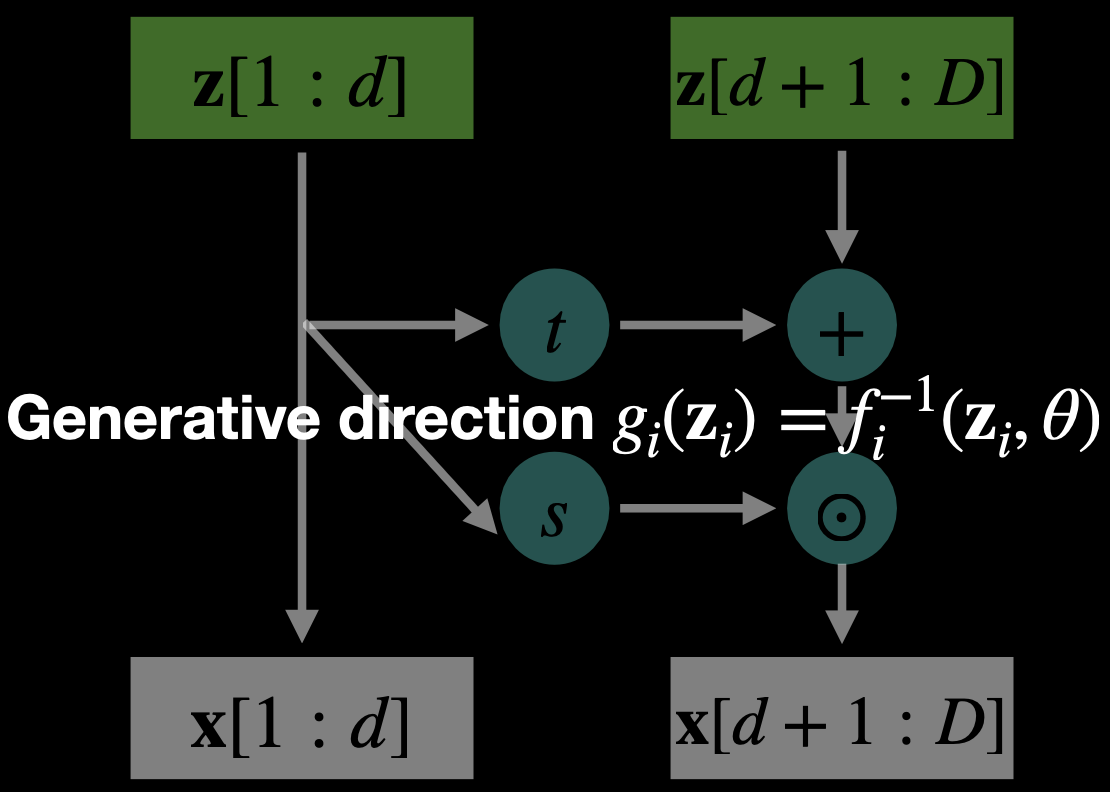
Generative Path (Inverse Pass):
- and are neural networks (often small CNNs or MLPs)
- Same parameters are reused in both directions.
How weight updates work in flow-based models
Training is done via maximum likelihood estimation (MLE) using the change-of-variables formula.
Change of Variables
Given and (just a unit Gaussian):
We know that and so we can write in the end:
Training Steps
- Inverse Pass: Given data , compute
- Compute log-likelihood loss:
- Backpropagate through:
- the inverse transformations
- the neural nets and
- the log-determinant term
- Gradient Descent:
- Use Adam/SGD to update parameters in and