First used them in Visual-Language Models for Object Detection and Segmentation and encountered them again in my GenAI Models and Robotic Applications course at Twente.
VLMs are a type of generative models that take image and text inputs, and generate text outputs. These models can output bounding boxes or segmentation masks when prompted to detect or segment a particular subject, or they can localize different entities or answer questions about their relative or absolute positions.
CLIP is a VLM, but it’s not generative (it’s contrastive).
There are a few setups:
- In captioning / VQA tasks, the VLM conditions on image tokens and then predicts text tokens autoregressively (e.g., “a dog chasing a ball”).
- In multimodal generation (e.g., image generation with text prompts), the VLM conditions on text tokens and predicts image tokens, which are then decoded back into pixels.
- In bidirectional encoders (e.g., CLIP, ALIGN), the VLM doesn’t “predict” tokens autoregressively at all, but instead aligns text tokens with visual embeddings in a joint latent space
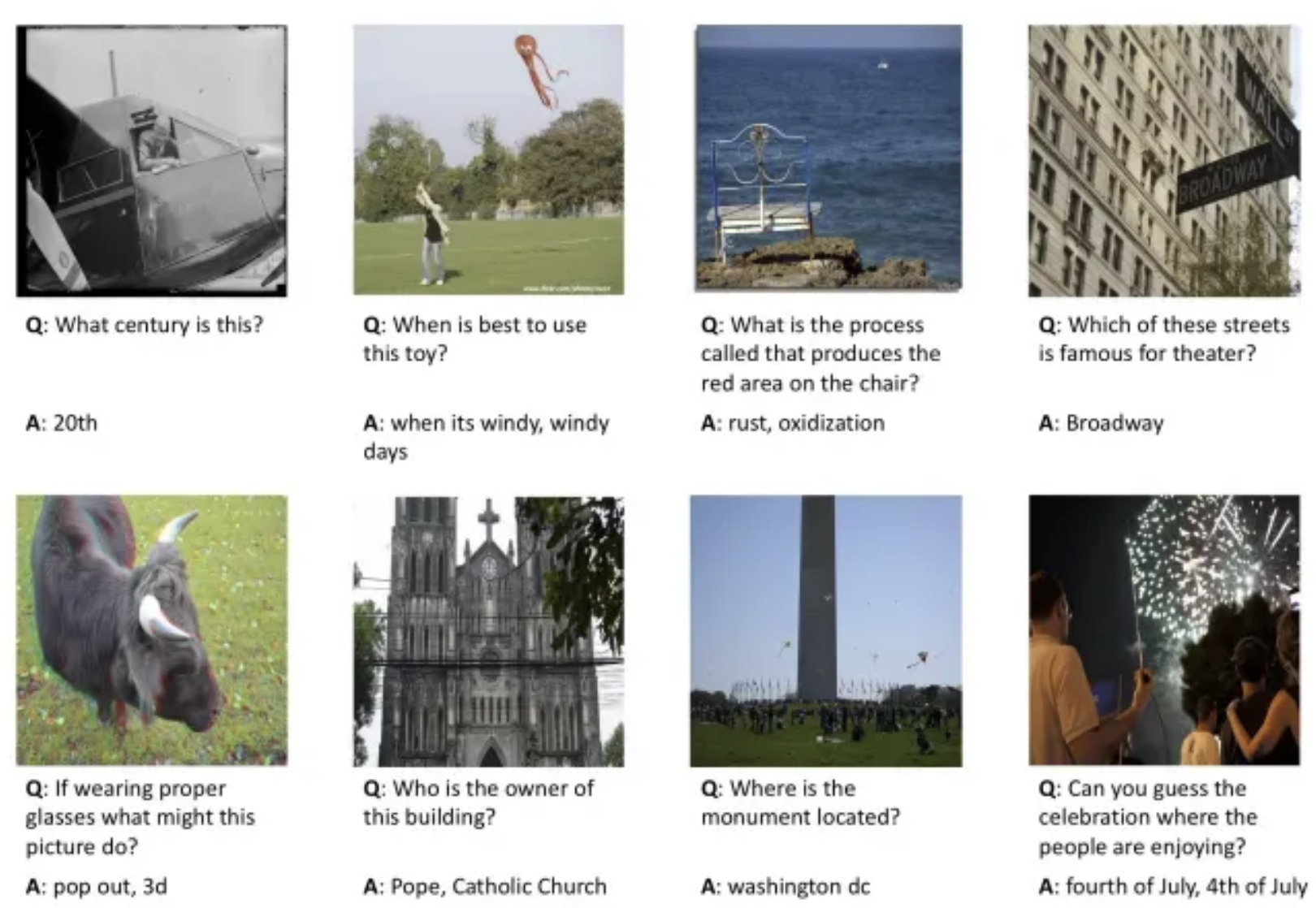
Visual Question Answering (VQA)
It’s taking an image and asking a question about it: