What if we express Linear Attention as a time-dependent process?
concept covered in Efficient FoMos. it’s a discrete recurrence.
I see it revisited the Change-of-Variable Formula (Jacobian Matrix) concept from Normalizing Flows. Basically we can represent the current attention to an ODE which relates functions and its derivatives to a single independent variable.
- I believe should be from the following state-space formulation?
Linear State-Space Layer (LSSL)
- is the continuous input at time
- controls how input enters — Input Matrix.
- ( states inputs)
- is the continuous evolving state at time
- controls how the state is updated — State/System Matrix.
- ( states states)
- determines which combinations of the states make up the measured outputs — Output Matrix
- ( outputs states)
- D directly maps the external inputs to the outputs without passing through the system states — Feedthrough/Feedforward Marix
- ( outputs inputs)
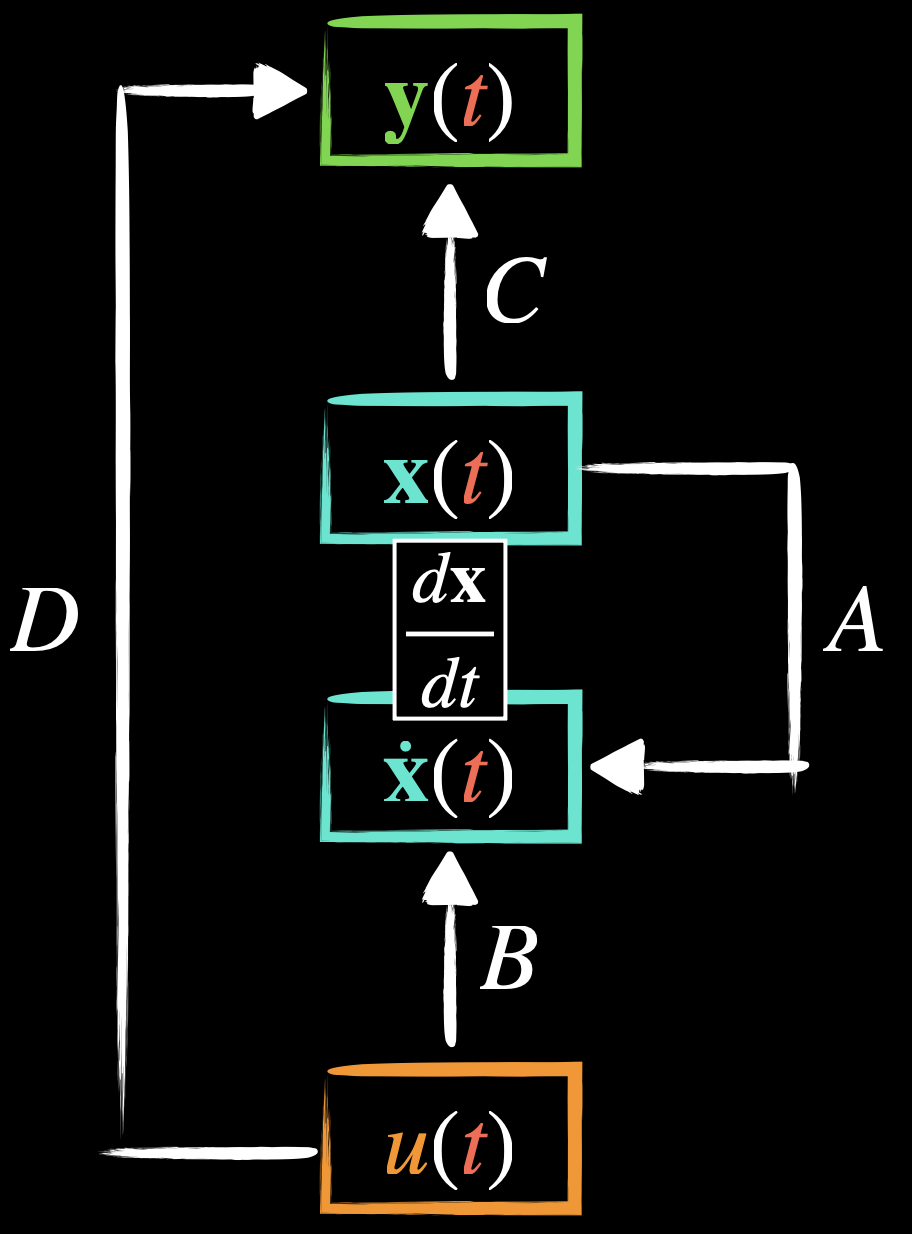
- LSSLs are recurrent: if a discrete step-size is specified, the LSSL can be discretized into a linear recurrence using standard techniques, and simulated during inference as a stateful recurrent model with constant memory and computation per time step.
- LSSLs are convolutional: the linear time-invariant systems defined by the equations above are known to be explicitly representable as a continuous convolution. Moreover, the discrete-time version can be parallelized during training using convolutions.
- LSSLs are continuous-time: the LSSL itself is a differential equation. As such, it can perform unique applications of continuous-time models, such as simulating continuous processes, handling missing data, and adapting to different timescales.
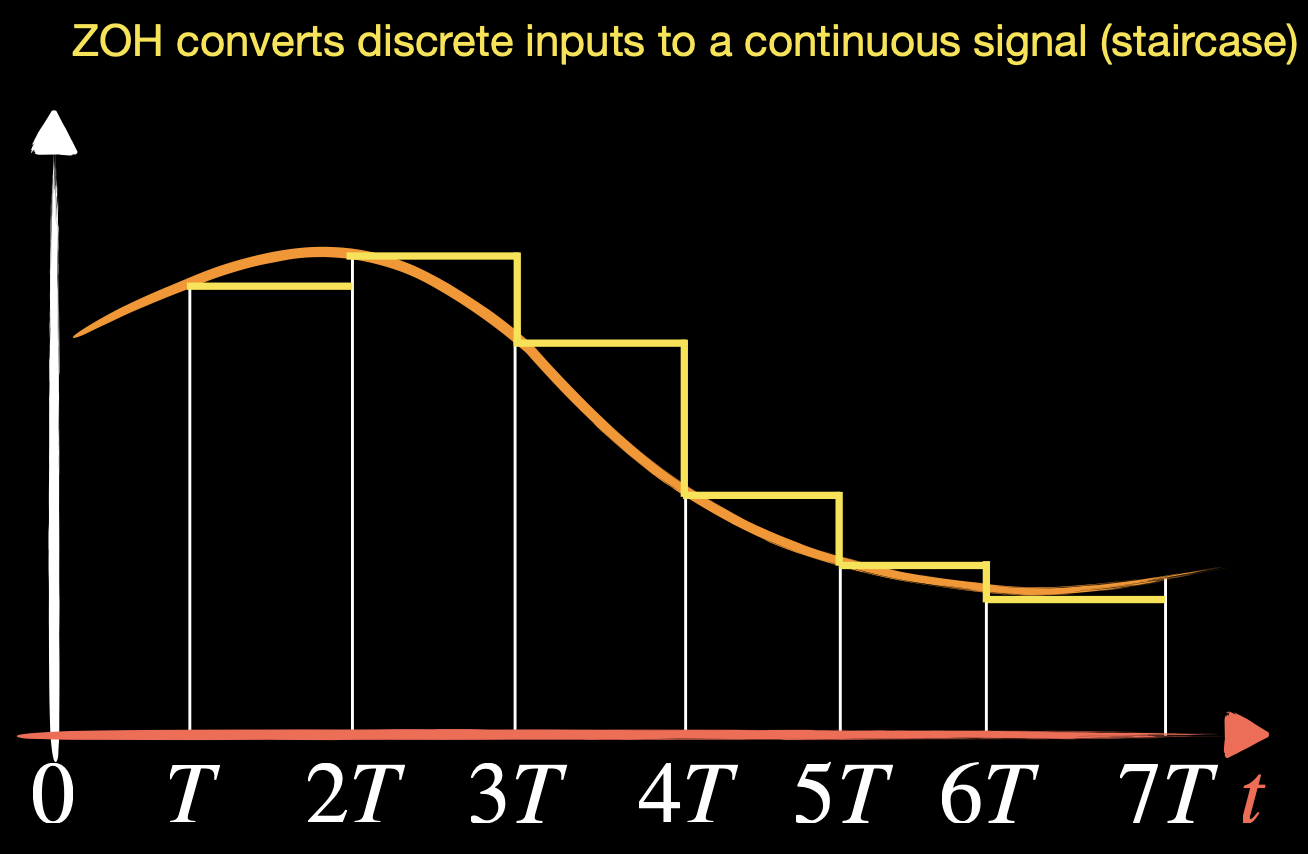
However, in real world our inputs are sampled data, not continuous observations. We need to integrate our discrete signals.
ZOH converts discrete inputs to a continuous signal (staircase).
The idea is basically saving the value of the lower bound.
- , and and are samples at timesteps
- this implies however constant values in inter-sample periods
- points can be represented with delays
- is learnable
- is our step size between and
We denote and . So the new state space becomes
with
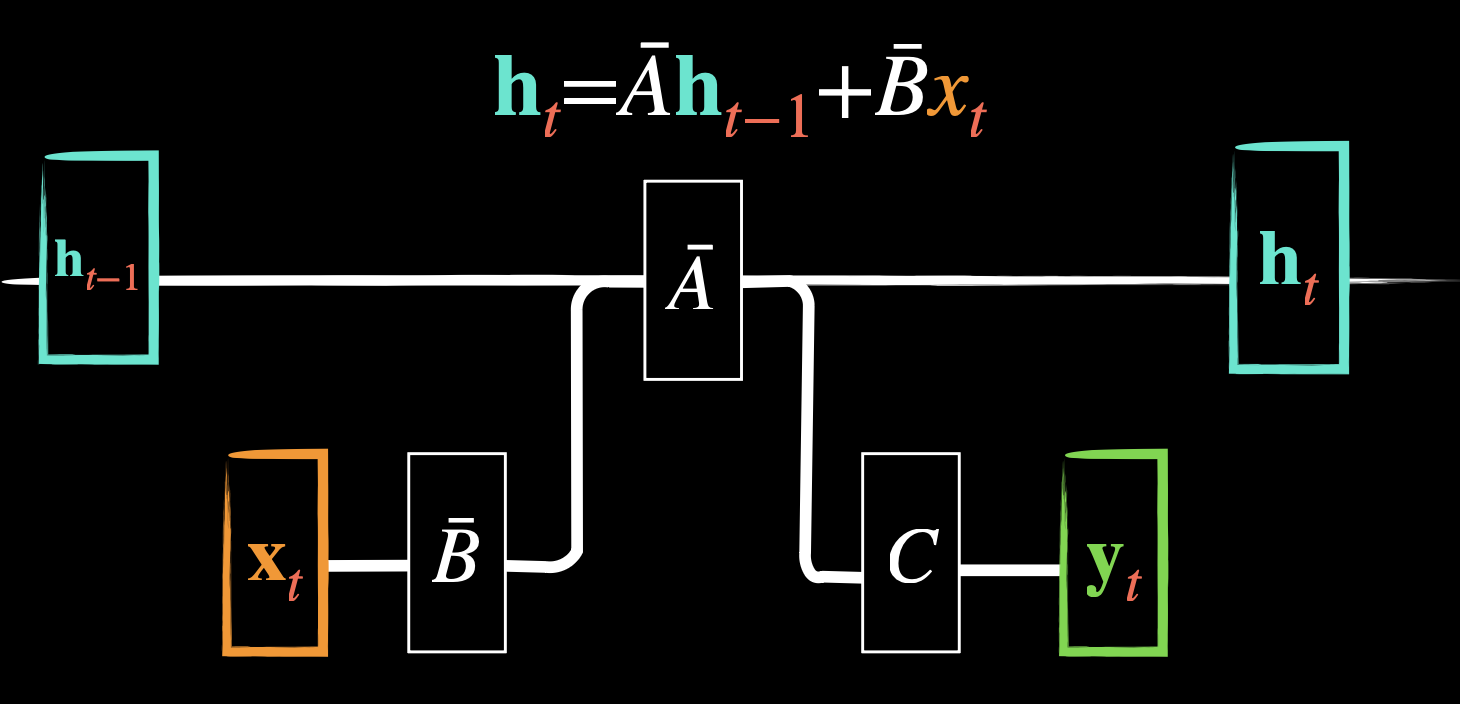
However, by expanding according to Efficiently Modeling Long Sequences with Structured State Spaces, we get the next formulation:
State updates are primarily influenced by :
-
- grows large over sequence — bias towards start
-
- grows small over sequence — forgetting
-
- no selectivity
should decay in a structured way based on the input
HiPPO -- High-order Polynomial Projection Operations
Different polynomials capture different details — Legendre polynomials
- w/ ⇒ — flat which captures the mean
- w/ ⇒ — linear captures the slope
- w/ ⇒ — quadratic captures the curve
- w/ ⇒ — cubic captures assymetry
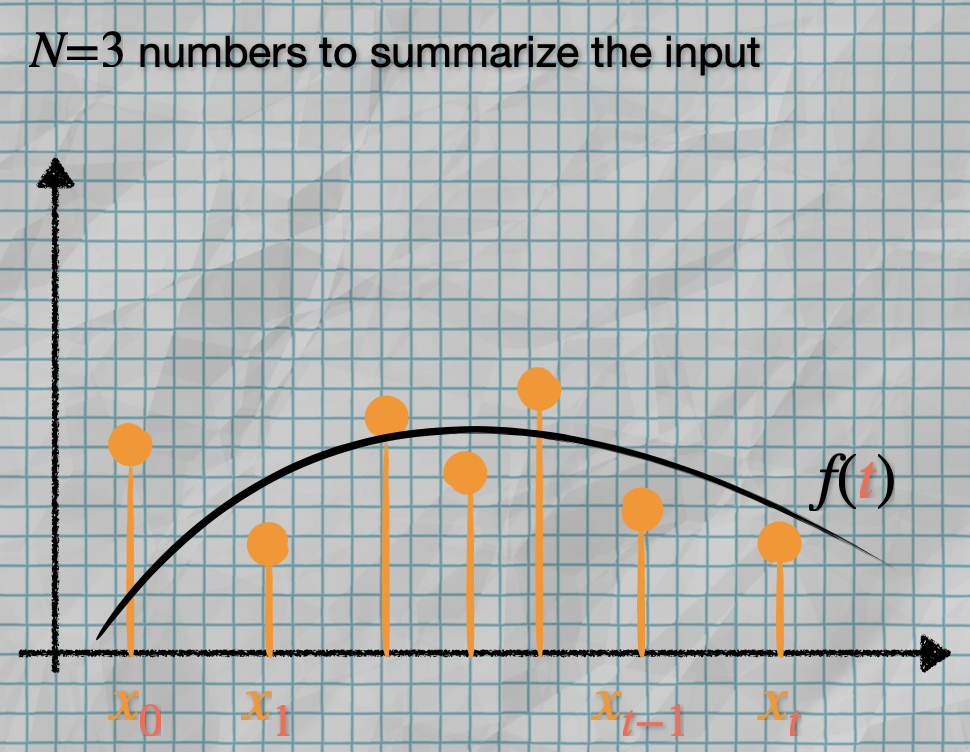
So we rewrite as:
where the coefficients capture how much of each polynomial’s shape is present in the signal.
- Low-order coefficients () capture the big picture (long-range)
- High-order coefficients capture fine details (short-range)
- are updated as new inputs arrive


When we revisit , we see a multitude of consecutive matrix multiplications that are input independent. We can precompute them by defining
Structured State Space Sequence Models (S4)
- Therefore, is a convolution kernel ⇒ parallelizable training
- is a recurrent process ⇒ efficient inference.
Currently there’s no selectivity over which states to remember? That’s where Mamba: Linear-Time Sequence Modeling with Selective State Spaces introduced selectivity.
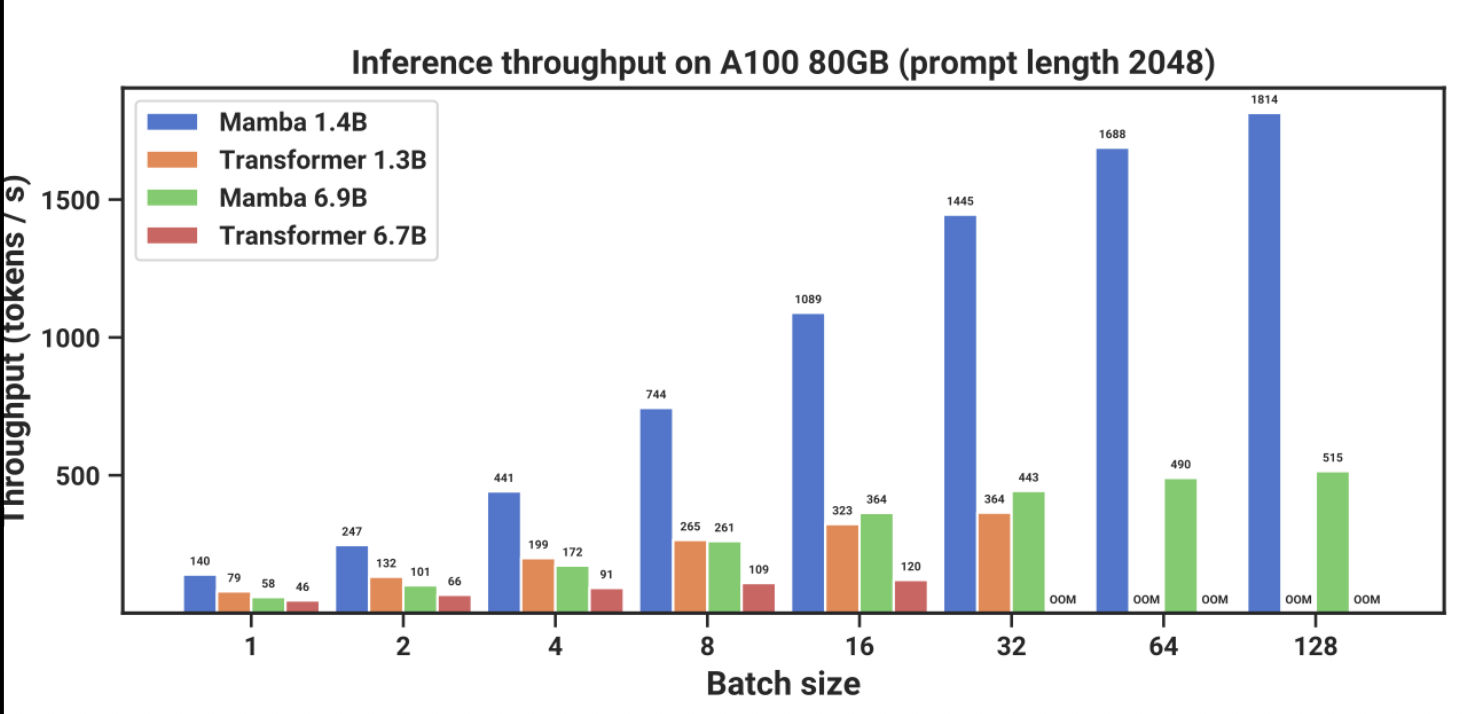
The left graph demonstrates Mamba’s superiority in inference throughput compared to standard transformers of comparable sizes. As the batch size increases, standard transformers quickly run out of memory because the memory required for their KV cache grows significantly. Mamba uses a constant-size hidden state instead of a growing cache, allowing it to process much larger batch sizes rapidly without memory exhaustion.
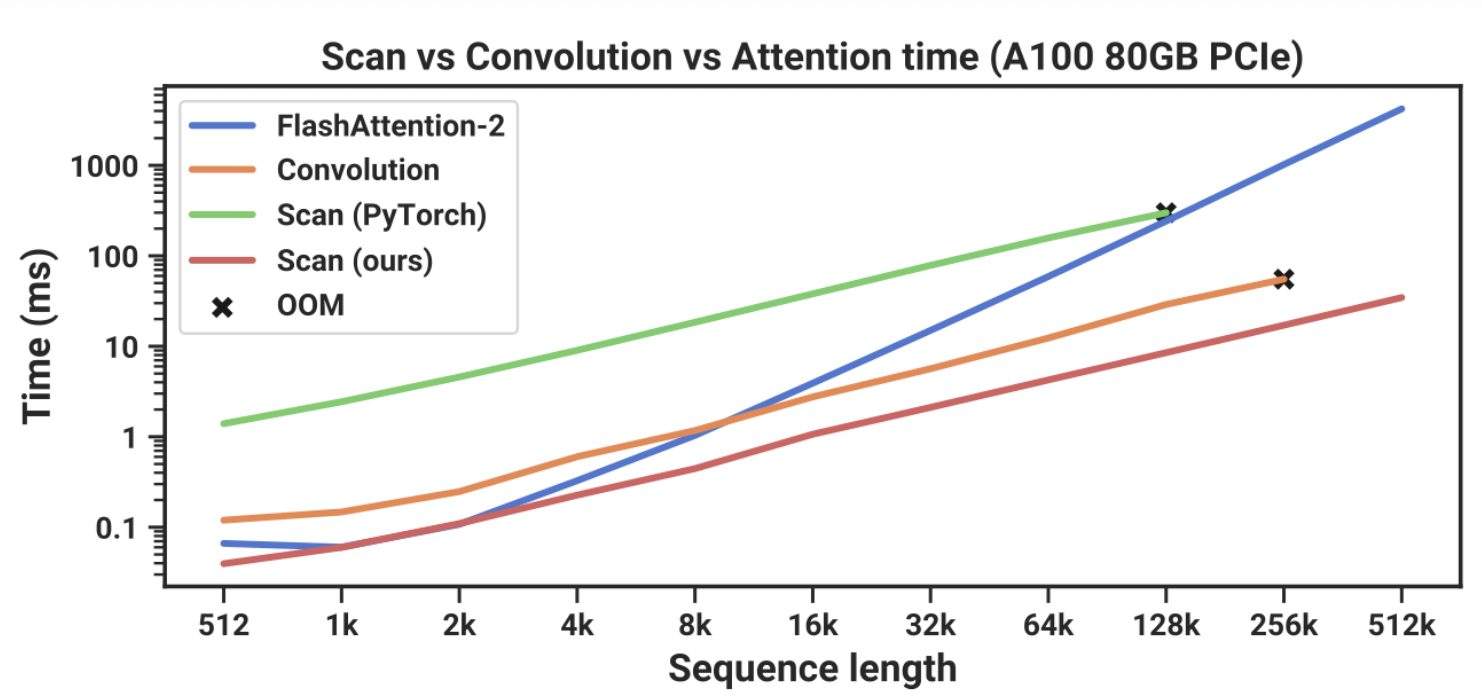
The second graph highlights Mamba’s computational efficiency with long sequences. It compares the execution time of Mamba’s core scan operation against standard attention mechanisms as sequence length increases. Standard FlashAttention-2 scales quadratically, meaning processing time explodes for long texts. The authors’ custom hardware-optimized scan operation scales linearly, allowing Mamba to handle massive context windows of up to 512k tokens significantly faster and without the out-of-memory errors that limit other methods.
| SSMs(S6) | SSMs(S4) | Transformers | |
|---|---|---|---|
| speed | linear | quadratic | |
| memory | linear | linear | quadratic |
| context-aware | Yes (selective) | No — all tokens are processed equally with fixed A, B, C | Yes — softmax over Q, K |
Still need to understand how they go from S4 to S6 and the selective attention process.