Source: paper
Instead of specifying a discrete sequence of hidden layers, we parameterize the derivative of the hidden state using a neural network.
These continuous-depth models have constant memory cost, adapt their evaluation strategy to each input, and can explicitly trade numerical precision for speed.
Related to Normalizing Flows, Transformers in depth and time.
Models such as residual networks and Normalizing Flows build complicated transformations by composing a sequence of transformations to a hidden state. They can be seen as an Euler discretization of a continuous transformation.
A ODE network defines a vector field, which continuously transforms the state.
In this case we parametrize the continuous dynamics of hidden units using an ODE specified by a neural network.
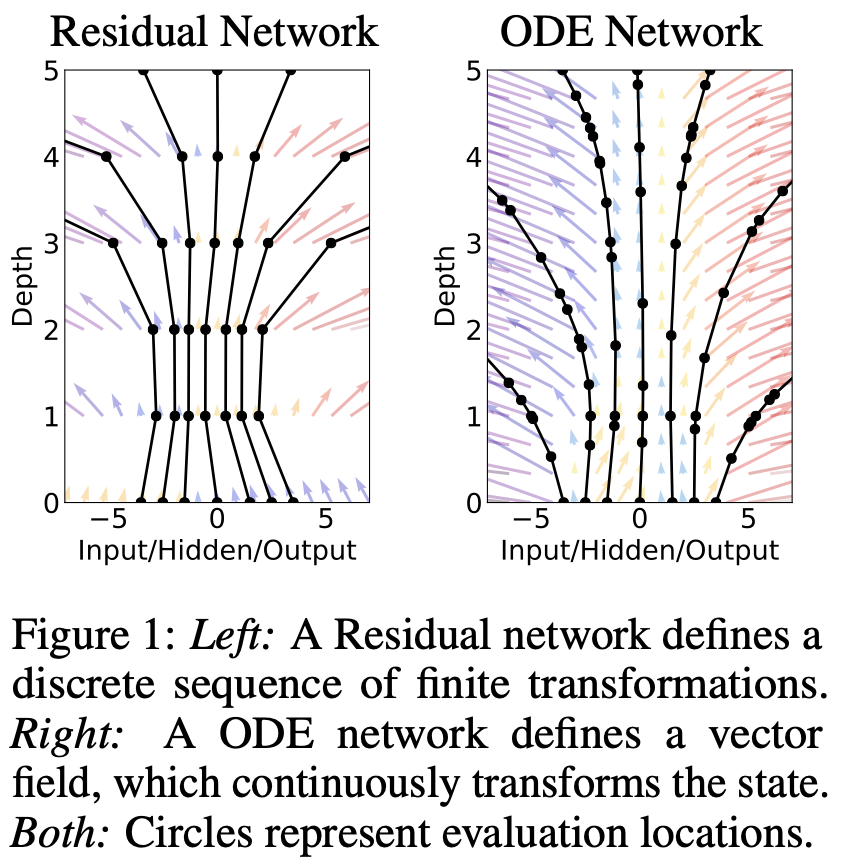
Starting from the input layer , we can define the output layer to be the solution to this ODE initial value problem at some time . This value can be computed by a black-box differential equation solver, which evaluates the hidden unit dynamics f wherever necessary to determine the solution with the desired accuracy.
Advantages
- O(1) memory — instead of storing every layer’s activations for backprop, they use the adjoint sensitivity method: solve a second ODE backwards in time to get gradients, without ever storing the forward trajectory
- Adaptive compute — modern ODE solvers (Runge-Kutta, etc.) pick their own step sizes to hit an error tolerance. So the network “depth” adapts per input automatically.
- Continuous Normalizing Flows — for generative models, computing the log-det-Jacobian (needed for change-of-variables) is normally O(). In the continuous limit it becomes just a trace of the Jacobian, which is O(D) and doesn’t require restricting model architecture.
So the first bulletpoint is actually their main contribution. Differentiating through the operations of the forward pass is straightforward, but incurs a high memory cost and introduces additional numerical error. This approach scales linearly with problem size, has low memory cost, and explicitly controls numerical error.
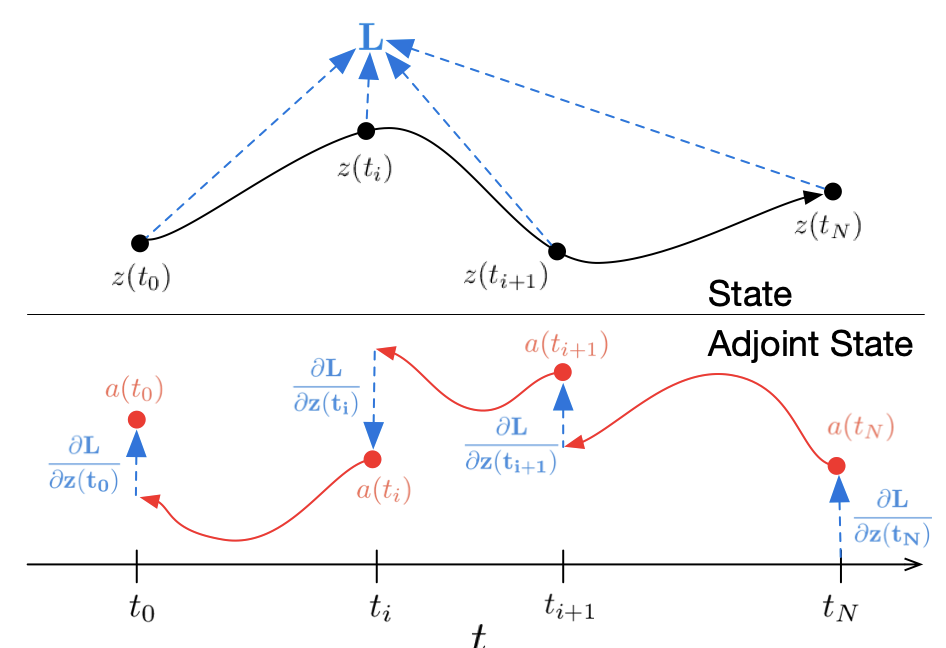
To optimize the process, they first determine how the gradient of the loss depends on the hidden state at each instant i.e. the adjoint :
- just solve this backwards from to and you get gradients w.r.t. the initial state, parameters , and even integration times — all in one backward ODE solve.
For flows, just go with the trace idea mentioned earlier.