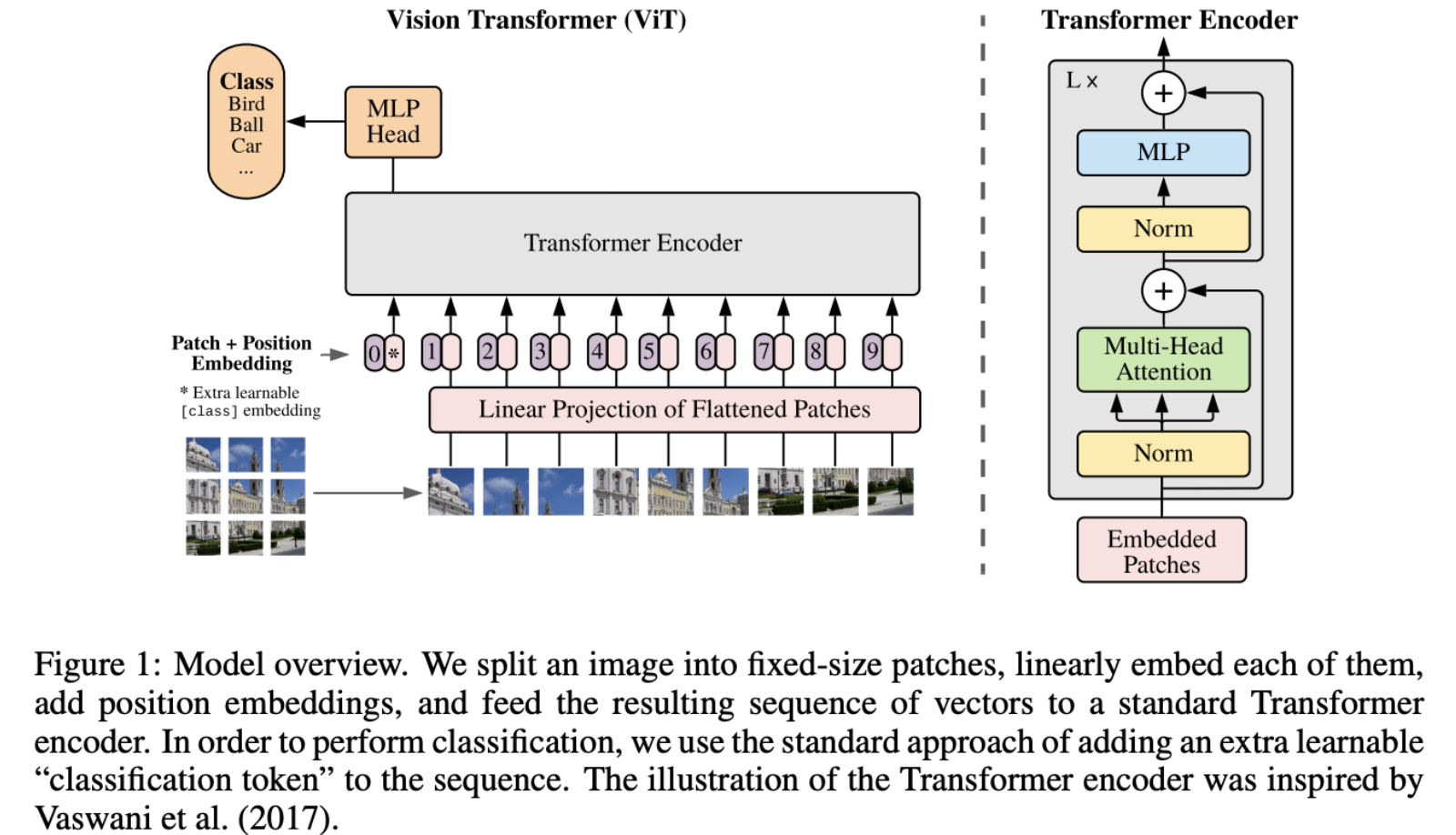
Well it’s basically the same as a normal transformer. You split the image into 16x16 pixel patches, and they are encoded into vector using linear projection. And then you have one extra token for positional encoding.

I used Vision Transformers in my Visual-Language Models for Object Detection and Segmentation project that I did for a startup (THEKER). There I learned about the segmentation model SAM (Segment Anything) and about CLIP which made the connection from text (NLP) to the actual object in the image (vision).
From the original paper: Transformers lack some of the inductive biases inherent to CNNs, such as translation equivariance and locality, and therefore do not generalize well when trained on insufficient amounts of data.
From Gemini AI
CNNs were designed specifically for images. They come with “built-in” assumptions that act like training wheels, helping the model learn very quickly even with small amounts of data.
- Locality: CNNs assume that pixels close to each other are more related than pixels far away. A filter only looks at a tiny 3×3 or 5×5 patch at a time. This helps it find edges and textures immediately.
- Translation Equivariance: This is a fancy way of saying “if the cat moves, the features move with it.” Because CNNs use the same “filter” (weight sharing) across the entire image, they naturally understand that an ear is still an ear, regardless of where it appears on the screen.
ViTs don’t have these “training wheels.” Instead of sliding a filter over an image, they chop the image into patches (like a jigsaw puzzle) and use Self-Attention to look at every patch simultaneously.
- Lack of Locality: From the very first layer, a Transformer is allowed to compare a pixel in the top-left corner with a pixel in the bottom-right corner. It doesn’t “know” that nearby pixels are usually more important; it has to learn that relationship from scratch.
- Lack of Equivariance: Transformers don’t inherently know that shifting an object in an image shouldn’t change its meaning. They use “positional embeddings” (basically labels saying “I am patch #1,” “I am patch #2”) to keep track of space, but they have to learn how to interpret those labels.
As a rule of thumb, if you have small amounts of data, CNNs will out-perform the Transformers, but when you have millions of data, the Transformers eventually learn the rules as well — and sometimes even better ones.
An Image is worth 16x16 Words: Transformers for Image Recognition at Scale
Resources: the original paper and Steven
Original image: 224x224x3 patch size: 16x16x3 total number of patches: 14x14 = 196
Each flattened patch is a vector of length 768.
Why is the Linear Projection Filter needed?
This lets the model reweight and mix the 768 raw pixel values into a better representation (e.g. combining color channels, edges, local contrasts).
As in Transformers, the embeddings in the embedding representation can all change for a given token. We want the same here, which is why letting the model learn an Affine Transformation is useful.
Input for the transformer encoder: [CLS], patch1, patch2, [MASK], patch4, [MASK], …
- Learnable
[class]embedding - Learnable position embeddings