A foundation model is anything that gives you meaningful re-usable features. Foundation Models are trained on massive datasets and perform well in zero-shot (no fine-tuning) scenarios (so like BERT, DALL-E, GPT-3).
Generalization is the “Holy Grail” of AI i.e. training a sufficiently large model on a large dataset and expecting it to have strong performance on different independent test sets.
Increasing model complexity (no. parameters) enters a training regime where generalization is first hurt and subsequently improved.
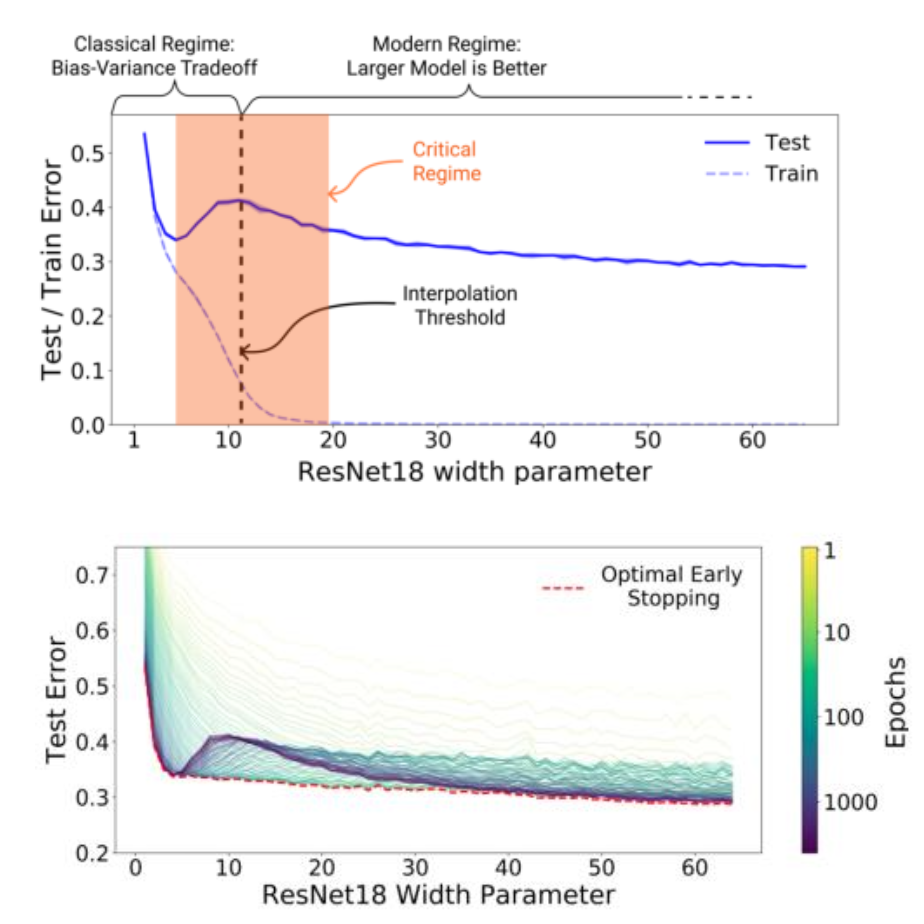
Don't start big. Start small, then scale.
- Experimenting with architecture on large datasets is extremely expensive. So instead, find the right architecture/hyperparameters on small datasets first — the structure of what works transfers.
- Once you’ve validated your model design, scale it up to larger data and expect predictable, proportional accuracy improvements (thanks to scaling laws).
Model architecture exploration should be feasible with small training data sets. In short, scaling laws make development predictable, so you can prototype cheap and scale confidently.
resources: Kaplan et al. from OpenAI (Scaling Laws for Neural Language Models), and the Baidu Research (Deep Learning Scaling Is Predictable, Empirically)
Neural Scaling Laws
Three quantities dominate model performance improvements:
- C = compute (FLOPs)
- D = data (tokens)
- N = parameters
Performance improves as long as we increase both N and D. Larger models require fewer samples to reach the same performance, and convergence is not critical for good performance. Additionally, model shape doesn’t matter too much.
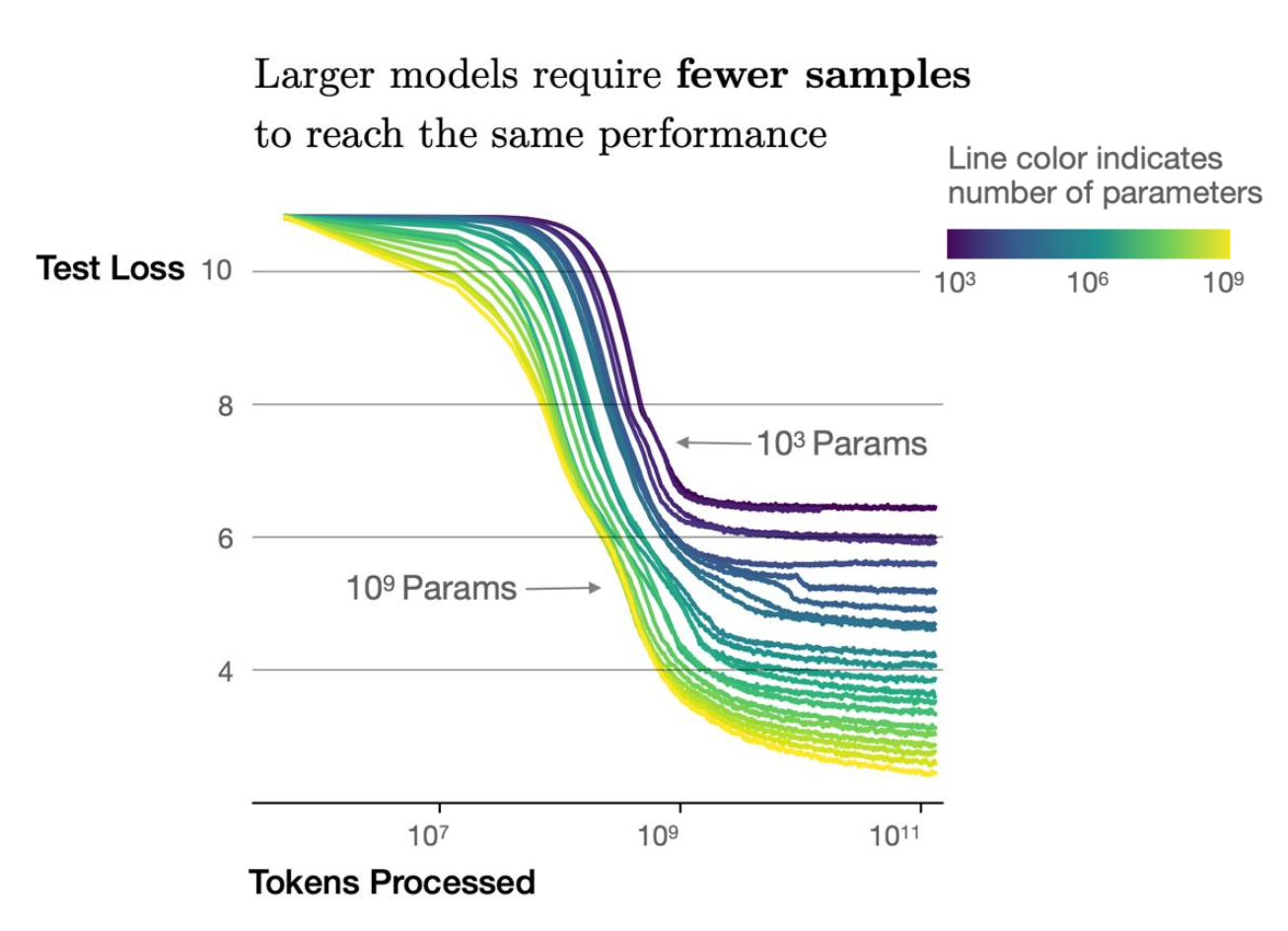
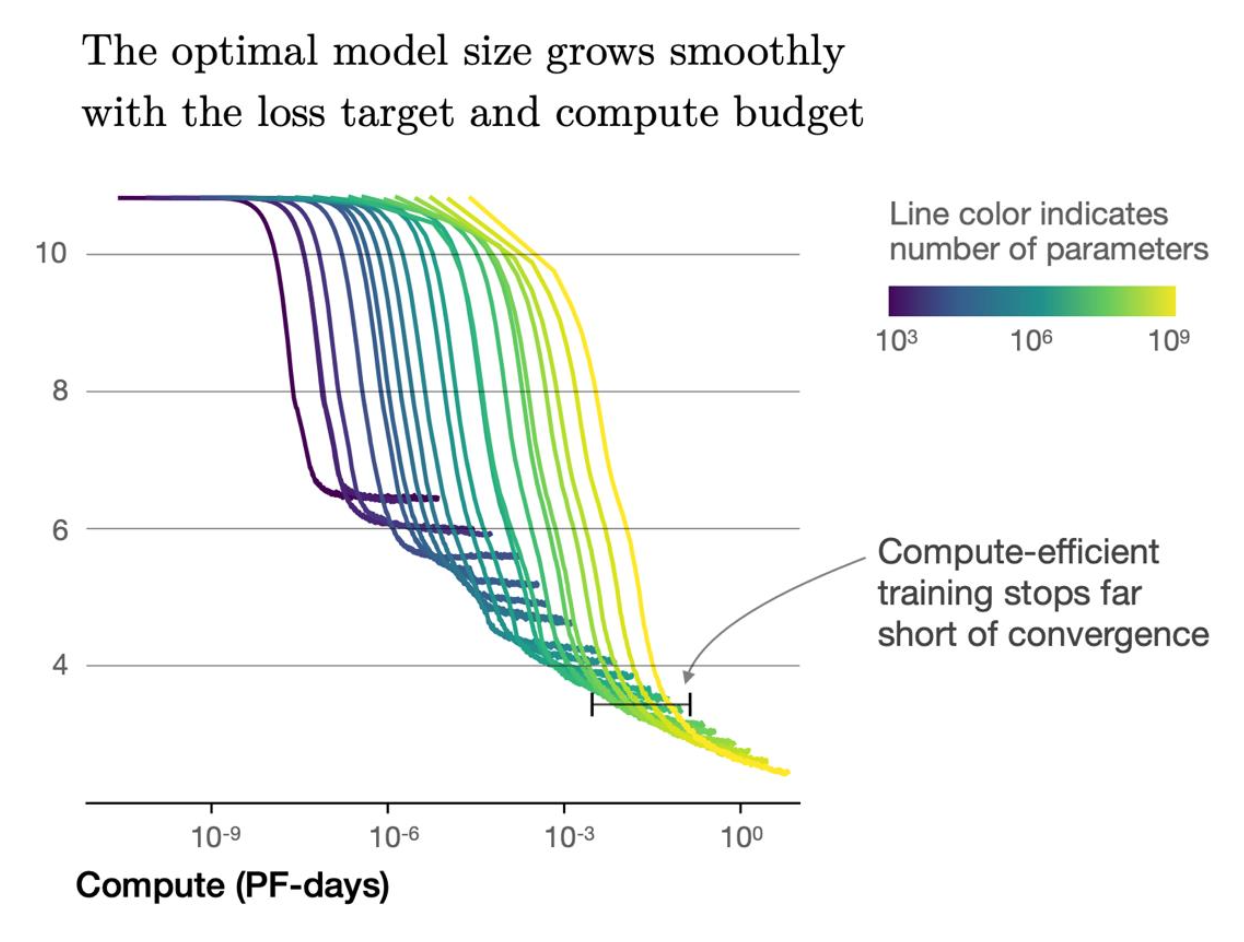
Scaling more data has diminishing returns — so be smarter about your data instead.
According to “Beyond neural scaling laws: beating power law scaling via data pruning”, a 1% drop in error might require more data/compute. That’s the wall you hit following standard power-law scaling. They suggest that pruning the least informative samples from your dataset can beat the full dataset, and do so more efficiently than simply scaling up. This “beats the power law” because the improvement curve is steeper than what raw scaling predicts.
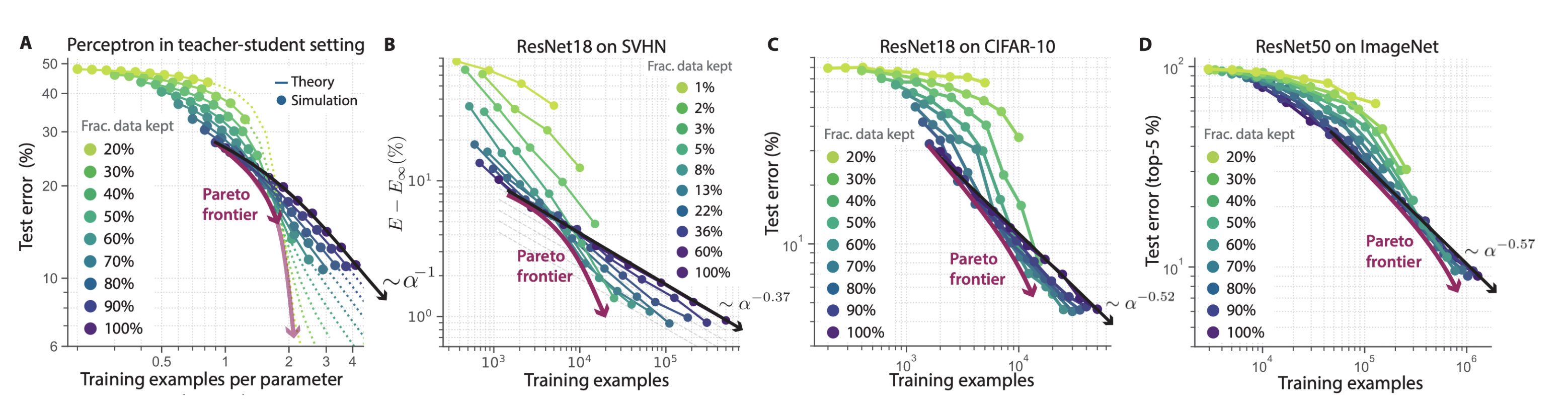
- The Pareto frontier (purple curve) shows that a carefully pruned smaller dataset can actually outperform training on the full dataset at the same compute budget.
According to “No zero-shot without exponential data”, Zero-shot performance isn’t “free” — it’s bought with data. Specifically, to get a linear improvement in zero-shot accuracy, you need exponentially more pretraining data covering that concept.
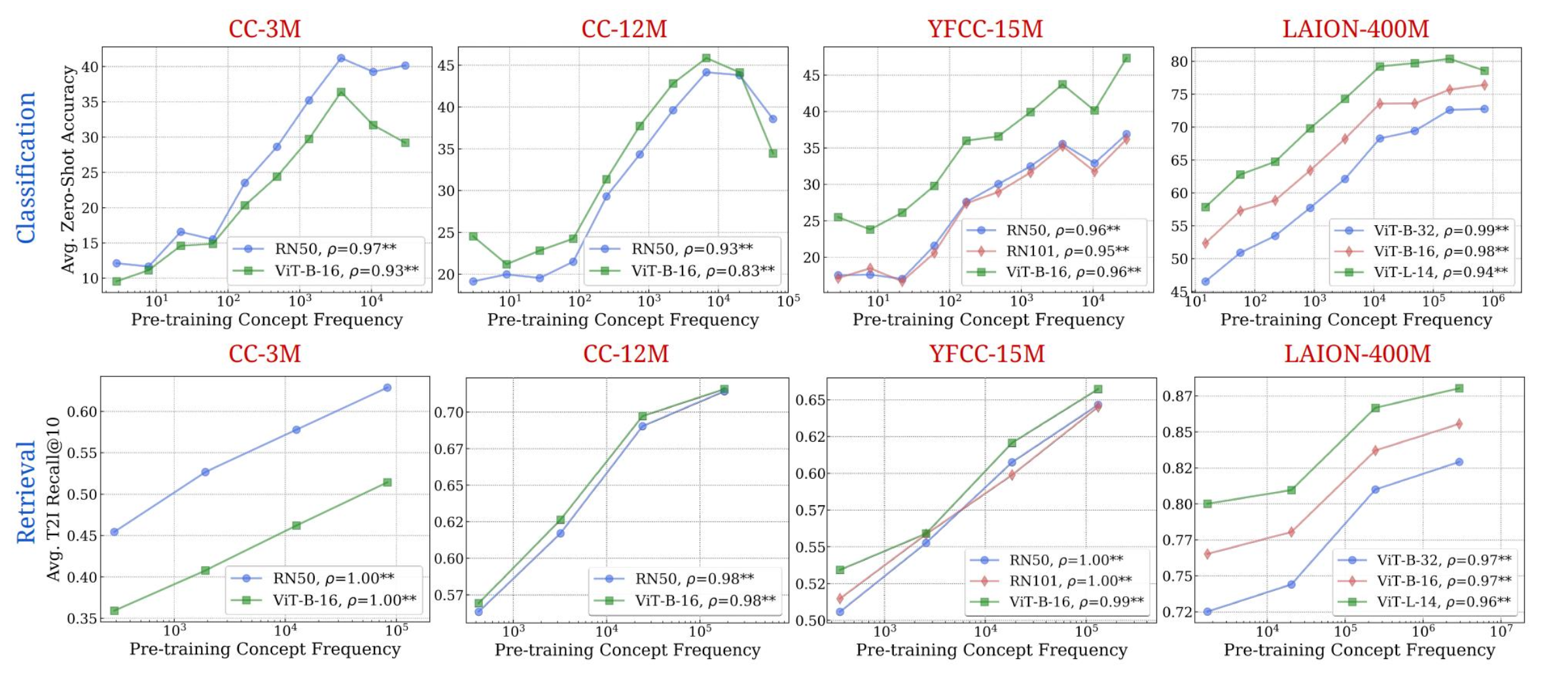
- The x-axis is logarithmic — meaning each step right is more data — yet accuracy only grows linearly.
- Rare concepts (e.g. “wet dog”, “ripe tomato”) are severely penalized because they appear infrequently in pretraining data
A potential escape hatch: Compositionality
If models could compose known concepts rather than needing to have seen every combination explicitly, the data requirements could be broken. For example: if a model knows “wet” and “dog” separately, can it generalize to “wet dog” zero-shot?
Still an open research question whether current models truly achieve it.
Copying (with updated weights) a FoMo for every task is inefficient (storage-wise, loading or switching among them)
Deploying them on specific tasks and achieving high performance requires tuning their parameters.
In terms of efficiency — Self-attention has quadratic complexity — a core bottleneck. Techniques like FlashAttention and mixed precision training address this. Covered in Efficient FoMos.