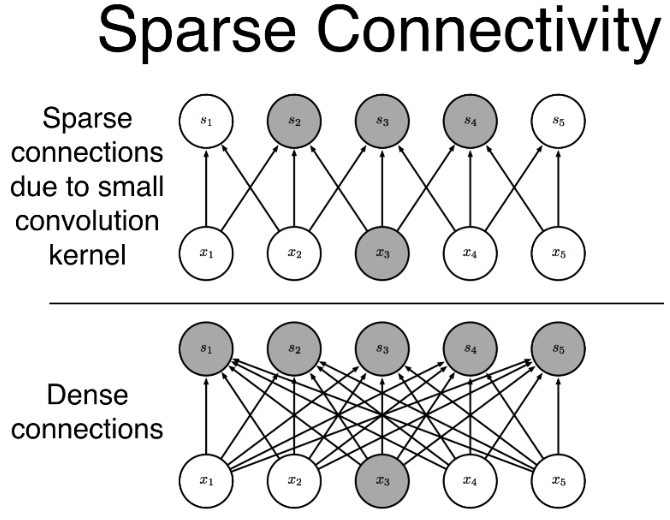
Sparse Interactions
In a standard neural network layer, every input value is connected to every output value, creating a massive web of dense connections. In a CNN, an output value is only calculated using a small, localized patch of the input, determined by the size of the convolution kernel. This localized focus significantly reduces the total number of connections and parameters, making the network computationally efficient.
Parameter Sharing
Instead of learning a completely unique set of weights for every single location in an image, a CNN uses the exact same weights (the kernel) across the entire input. As the kernel slides across the image, it reuses those same parameters to calculate the output. This allows the network to learn to detect a specific pattern, like a horizontal edge, and find it anywhere in the image without needing to relearn what that edge looks like at every possible coordinate.
Equivariant Features
Because the same kernel weights are shared and applied across the whole input space, the network’s output responds predictably to shifts in the input. If an object is shifted slightly to the right in the input image, the feature map representing that object’s detection will also shift to the right by the same amount. The representation moves exactly as the input moves.