Related to Efficient FoMos. Source: huggingface and OLMoE paper.
TL;DR
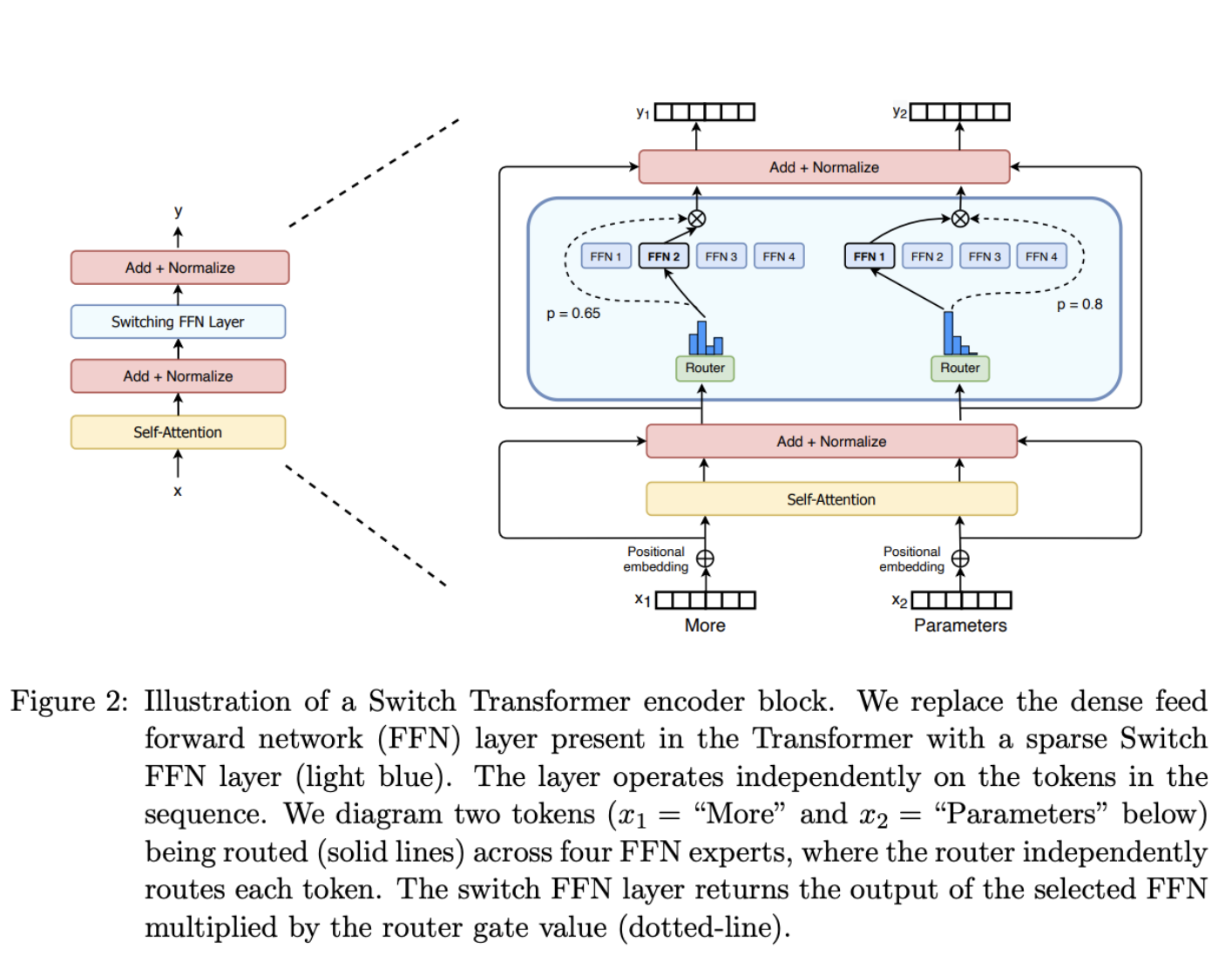
MoEs replace the dense FFN in a transformer layer with multiple smaller FFNs (“experts”) + a router that picks which experts process each token.:
- Are pretrained much faster vs. dense models
- Have faster inference compared to a model with the same number of parameters
- Require high VRAM as all experts are loaded in memory
- Face many challenges in fine-tuning, but recent work with MoE instruction-tuning is promising
Mixture of Experts enable models to be pretrained with far less compute, which means you can dramatically scale up the model or dataset size with the same compute budget as a dense model. In particular, a MoE model should achieve the same quality as its dense counterpart much faster during pretraining.
Sparse vs Dense
Sparsity uses the idea of conditional computation. While in dense models all the parameters are used for all the inputs, sparsity allows us to only run some parts of the whole system.
In the context of transformers models, a MoE consists of two main elements:
- Spares MoE layers are used instead of dense feed-forward network (FFN) layers. MoE layers have a certain number of “experts” (e.g. 8).
- A gate network or router, that determines which tokens are sent to which expert — just restricted to the top-k experts instead of summing over all of them. For example, in the image below, the token “More” is sent to the second expert, and the token “Parameters” is sent to the first network.