FlashAttention is a memory-efficient exact-attention algorithm that fuses the whole attention computation into a single tiled CUDA kernel, avoiding ever materializing the full attention matrix.
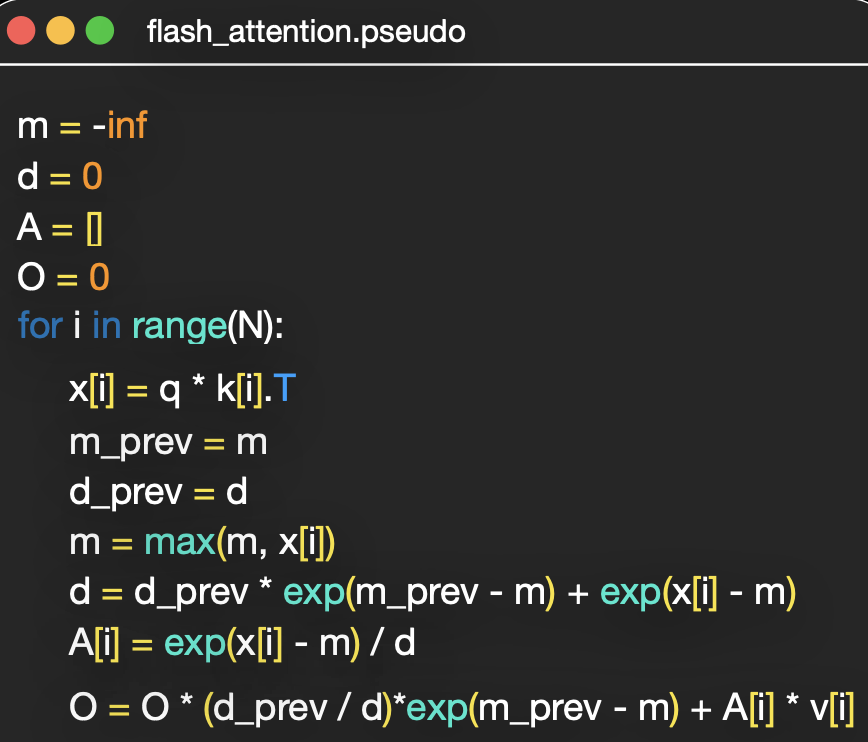
It’s not a different attention mechanism! It’s the same softmax attention, just computed without ever materializing the attention matrix in slow DRAM (tiling + recursive stable-softmax trick).
The naive implementation from transformers computes of shape , writes it to DRAM, reads it back to softmax, writes again, reads to multiply with . Covered in Efficient FoMos. For long contexts this is both memory-quadratic and bandwidth-bound.
The process
- Load blocks of from DRAM to SRAM one tile at a time
- Compute the tile’s partial attention in SRAM
- Use an online softmax that updates the running normalizer as new tiles arrive, so a global pass isn’t needed
Net effect: O(N) memory instead of , plus 2-4 wall-clock speedup on long sequences.