This guy notates the states in state space as s and the inputs as a (actions).
When the system becomes very complicated, it can become either unknown or unreliable.
chaos in dynamics = we can get different depending on the conditions (think of double pendulum). Even if you have a deterministic model(state space), you are limited in terms of predicting its states. In practice, even if you have a good model, you are limited.
Inpainting is another way to condition the generative diffusion step (please research this, because I did not get it)
From Claude: Inpainting = Filling in missing or corrupted parts of data while keeping known parts fixed. it’s replacing part of a trajectory (like changing a car to a tank) while maintaining consistency with the rest of the sequence.
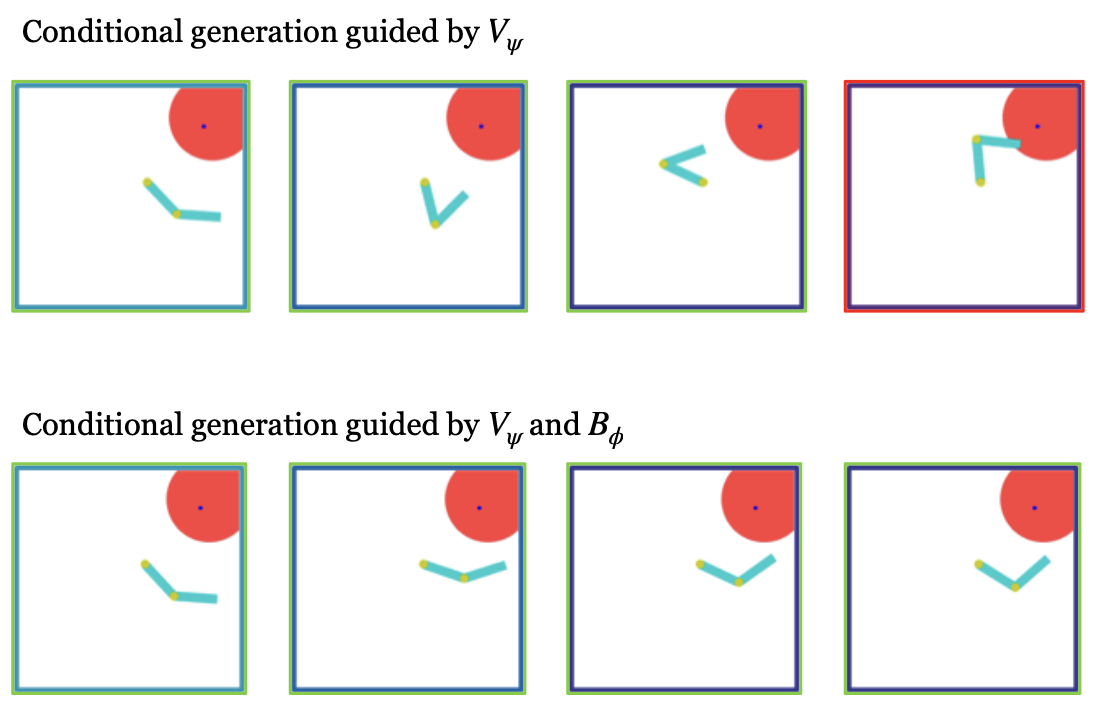
Guided sampling: Steering the generation process toward desired outcomes by incorporating additional constraints or goals. For example, generating trajectories that satisfy specific conditions (reach a target, avoid obstacles, follow certain dynamics).

DYNAMICALLY-CONSISTENT TRAJECTORY GENERATION
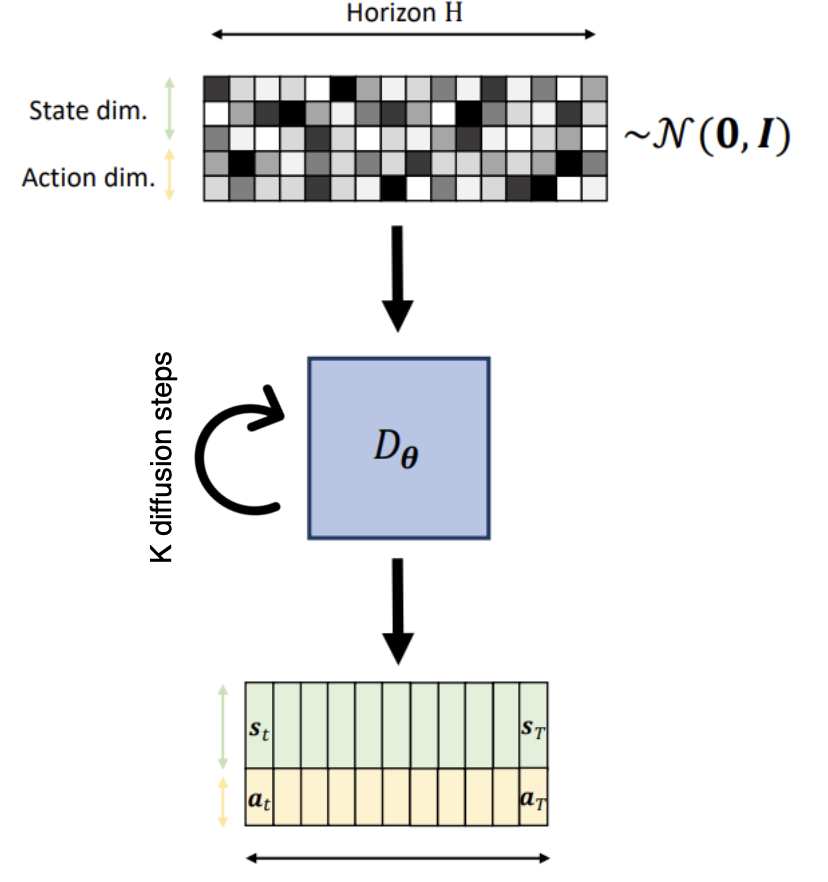
DDPMS for Dynamical Systems: they corrupt the discrete trajectory in time where we stack the states . stands for the amount of corruption we apply (noise).
So basically we corrupt this trajectory with noise.
We learn directly the closed loop system if we store in a RL (Reinforcement Learning) way:
How denoising is done: copy paste from difussion denoising process — aka NN. In this phase, the causal relations are learned. In the paper you will find one time-axis and one diffusion-axis.
The loss function is formulated as:
Use guided sampling and inpainting to set up optimal control schemes.
- The dataset is augmented with reward signals (like in RL).
- The DDPM is trained to predict the expected cumulative return of trajectories.
- The DDPM is trained to predict the safety condition at each step of the trajectory.
- After training, we use and to guide the generation of
- In this phase, the specific task is encoded and the safety conditions() are also encoded.
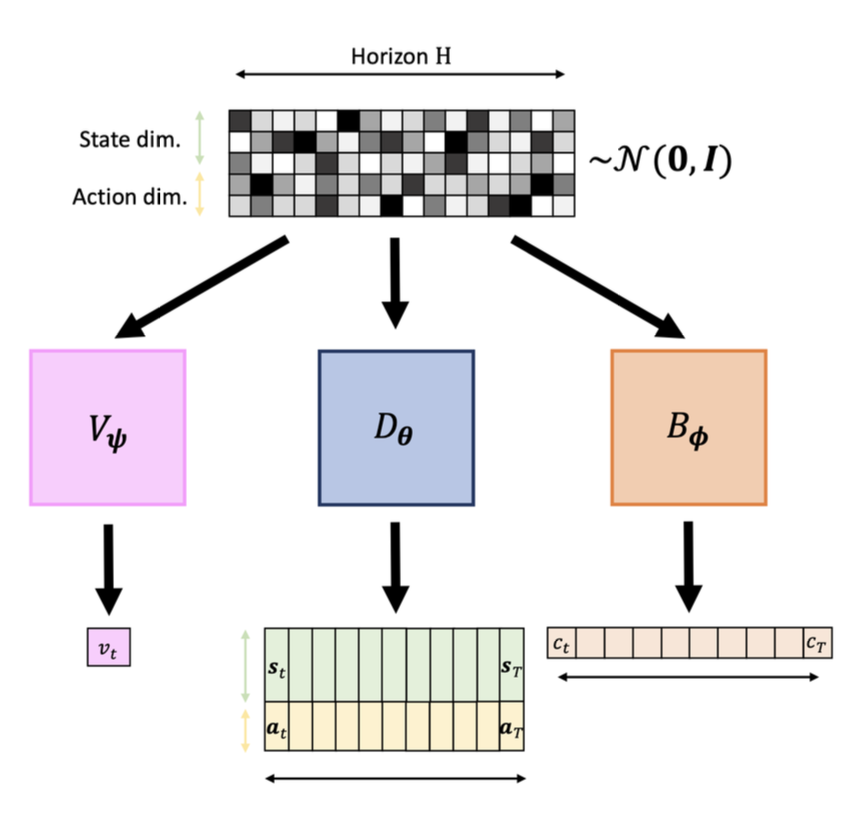
Notice that we don’t need the dynamics .
One advantage is the flexible prediction horizon.
This whole concept requires collecting good examples.
Difference between classifier free and classifier guidance??????
Classifier free: you have an extra vector that you add as extra input for DDPM which acts as additional conditions for the system you want to learn
Classifier guidance: train another NN to generate the V (map) function which maps a closed loop trajectory into a value. This value is the value-function in a RL sense. If the value is very high, it is a very good behaviour.
From Claude, because I don’t trust myself:
Classifier guidance: Train a separate classifier network that predicts p(condition|x_t) at each noise level. During sampling, use its gradient to steer the diffusion toward high-probability regions for your desired condition. You’re essentially using ∇log p(condition|x_t) to guide the denoising.
Classifier-free guidance: Train a single model that learns both conditional p(x|condition) and unconditional p(x) distributions (by randomly dropping the condition during training). At sampling time, extrapolate away from the unconditional prediction: ε_guided = ε_uncond + w(ε_cond - ε_uncond), where w is guidance scale.
Still have to understand these concepts.