This is Lecture 6 from my Natural Language Processing course.
Neural Networks
Logistic Regression
We wrote the posterior probability of the class given a datapoint as:
The parameters of this model, , can be trained by conditional Maximum Likelihood:
This is equivalent with minimizing the binary cross-entropy loss.
Activation Functions
The activation functions (turn to 0-1 possibility) used the most are:
Feed-forward networks and back-propagation
Computational Graphs
Consider the following function
We can decompose this into temporary variables and compute the forward and backward propagations
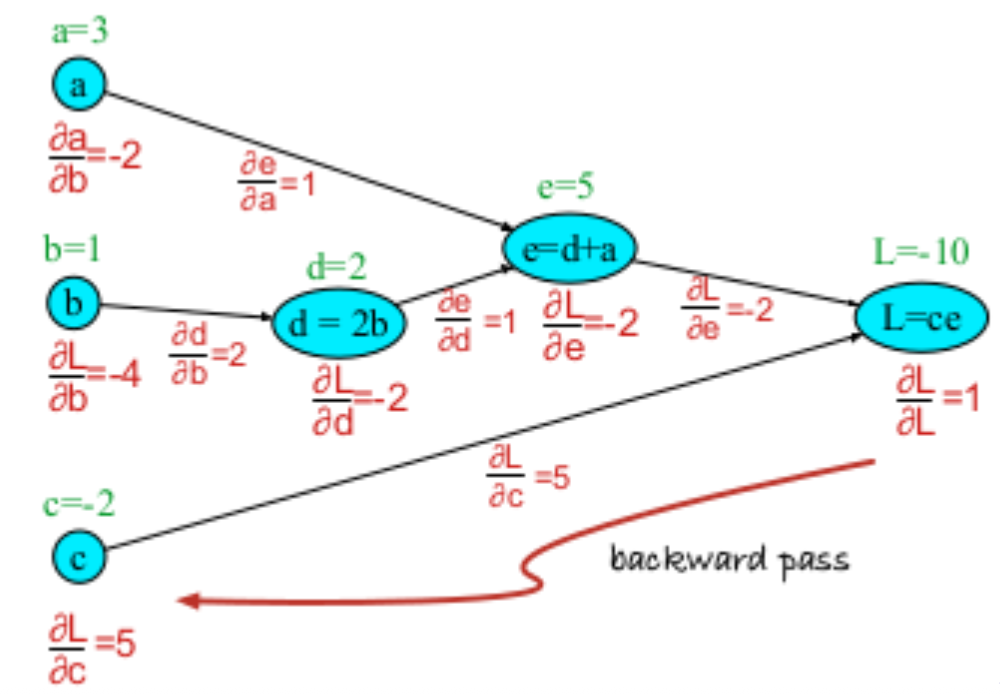
If we consider the function , then the derivative of with respect to can be decomposed into
Transformers
Self-attention layers (Basic version)
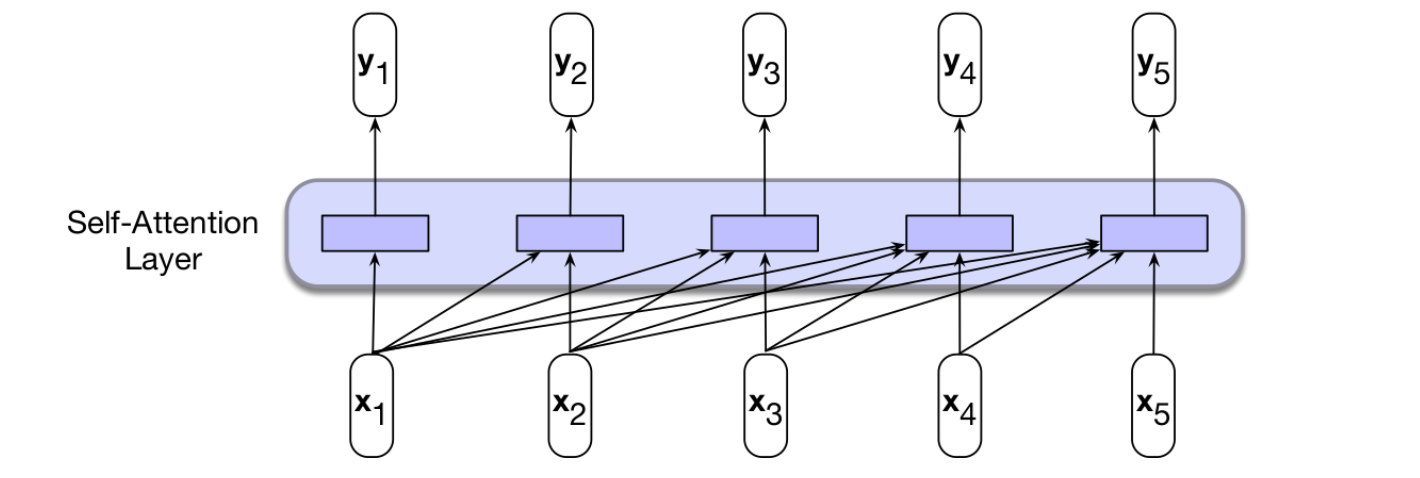
- Weigh each input by its importance within the context
- Most basic version:
- all can be computed in parallel.
Self-attention layers (Extended version)
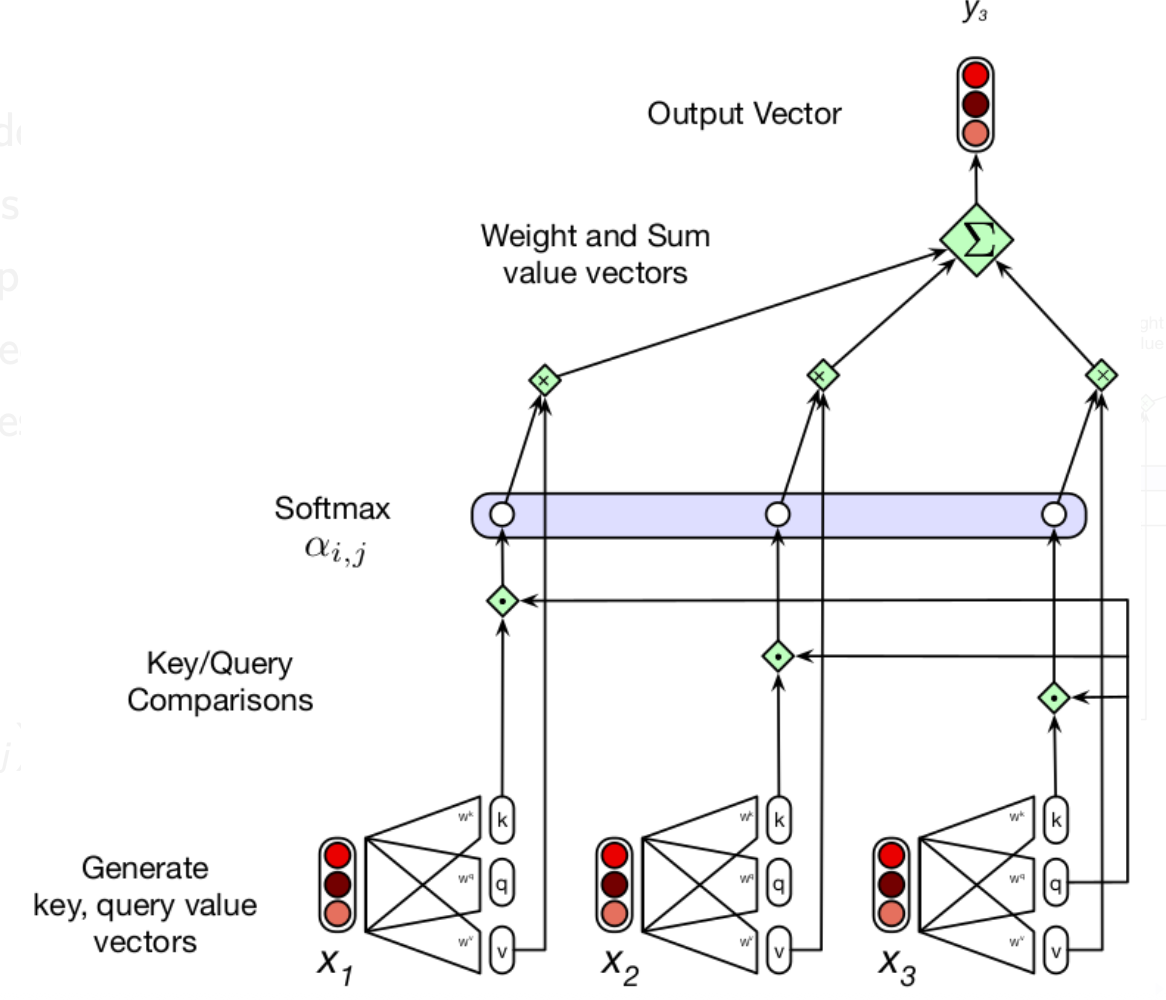
Each input embedding plays multiple roles:
- Current focus of attention (Query)
- Preceding input compared to query (Key)
- Input weighted in computing the output (Value)
So, we encode these as:
and get:
Transformers
- Map sequence to sequence
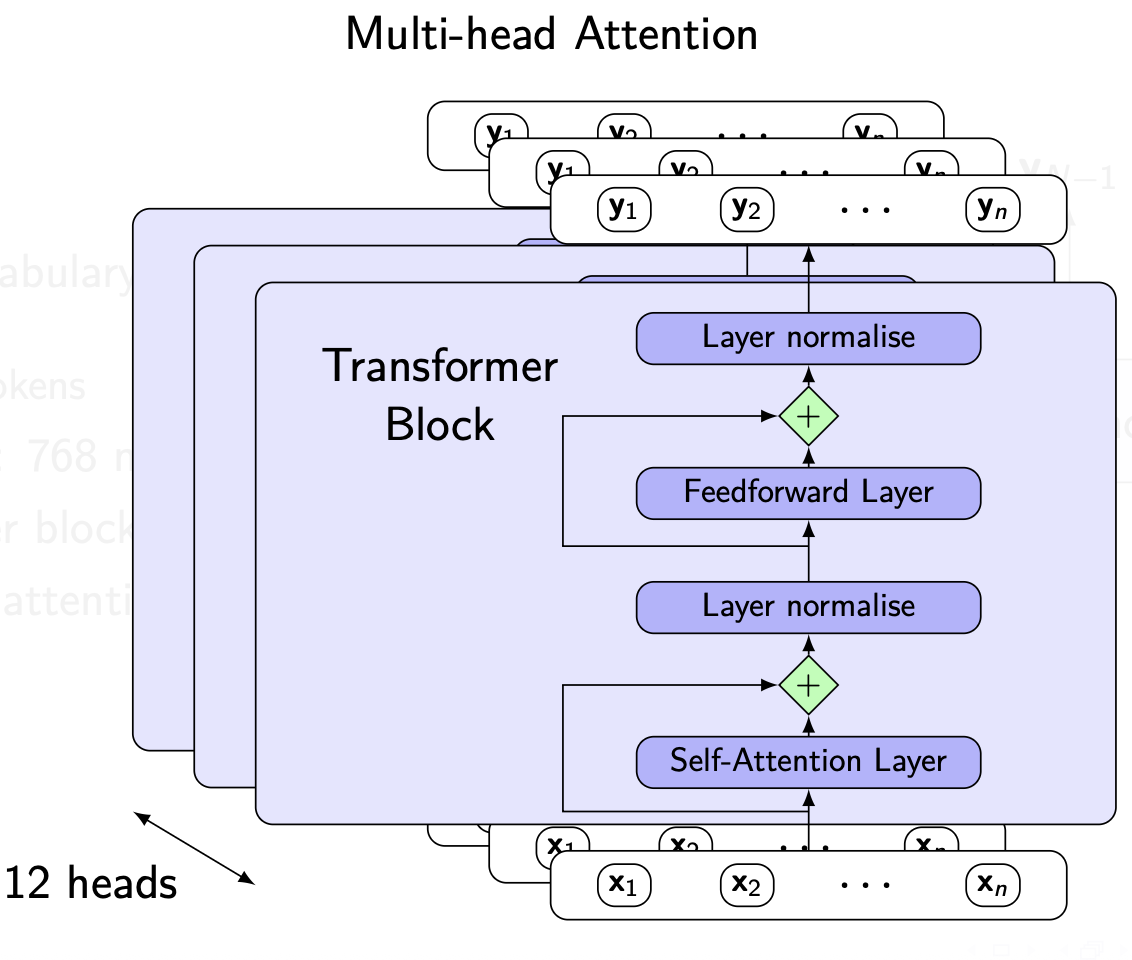
- Made of stacks of transformer blocks
Units of transformer blocks
- Self attention layers
- Residual connections
- Directly pass information from lower to higher layer
- Similarly improves training
- Normalisation layers
- Limits range of values: facilitates gradient-based learning
- Make all vector elements have zero mean, unit variance
Multi-head attention and positional encoding
- How to capture different kinds of relationships between inputs?
- various versions of Q,K,W
- various versions of Q,K,W
- Positional encoding
- Embedding contains position information
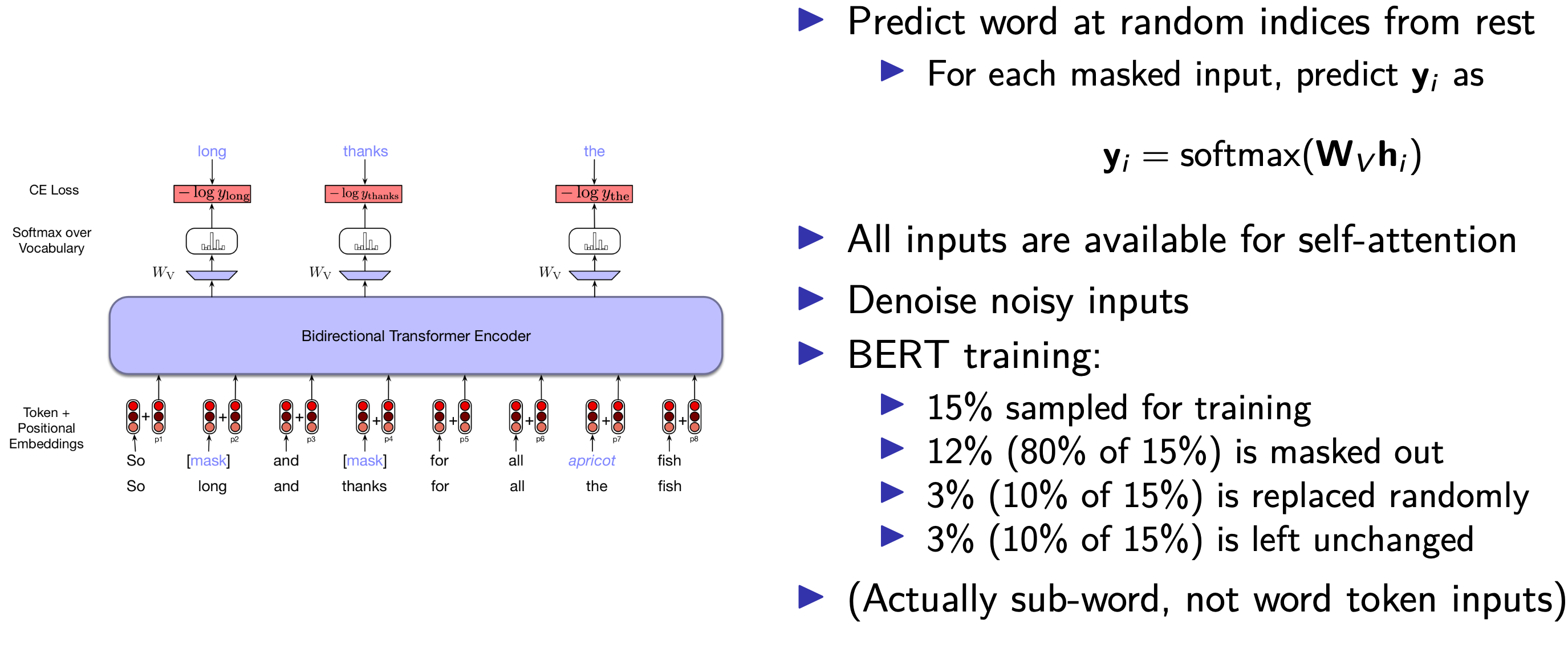
Masked training and fine tuning
- Unidirectional: Predict future from past
- Bidirectional: Predict anything from anything
- No encoder-decoder architecture
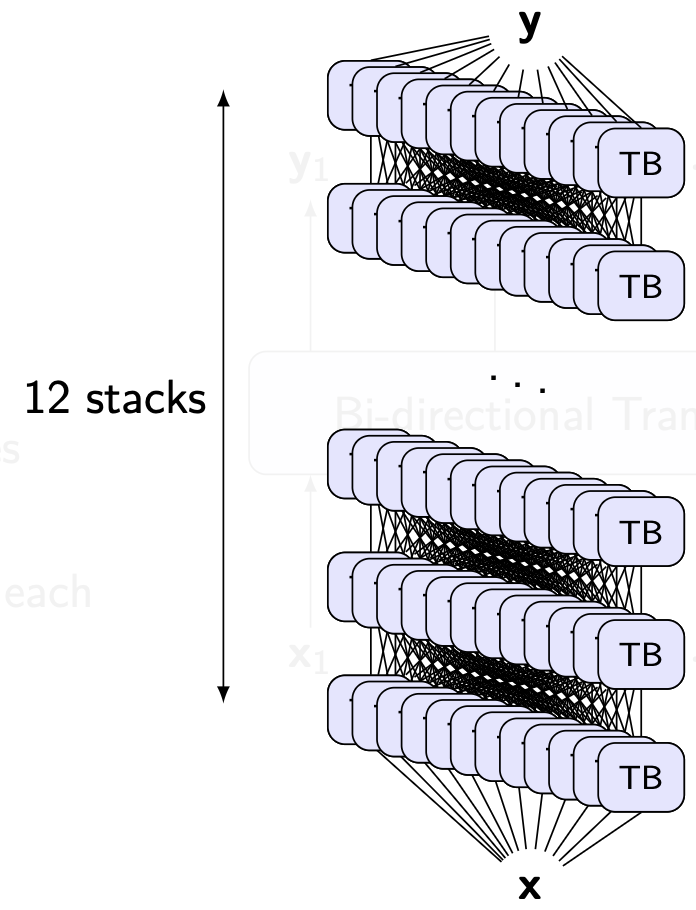
BERT: Bidirectional encoder representations from transformers
BERT
- Sub-word vocabulary, Word-Piece: 30k tokens
- Hidden layers: 768 nodes
- 12 transformer blocks
- 12 multihead attention, each
Training BERT